 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround-V: Teaching VLMs to Ground Complex Instructions in Pixels
May 20, 2025This work presents a simple yet effective workflow for automatically scaling instruction-following data to elicit pixel-level grounding capabilities of VLMs under complex instructions. In particular, we address five critical real-world challenges in text-instruction-based grounding: hallucinated references, multi-object scenarios, reasoning, multi-granularity, and part-level references. By leveraging knowledge distillation from a pre-trained teacher model, our approach generates high-quality instruction-response pairs linked to existing pixel-level annotations, minimizing the need for costly human annotation. The resulting dataset, Ground-V, captures rich object localization knowledge and nuanced pixel-level referring expressions. Experiment results show that models trained on Ground-V exhibit substantial improvements across diverse grounding tasks. Specifically, incorporating Ground-V during training directly achieves an average accuracy boost of 4.4% for LISA and a 7.9% for PSALM across six benchmarks on the gIoU metric. It also sets new state-of-the-art results on standard benchmarks such as RefCOCO/+/g. Notably, on gRefCOCO, we achieve an N-Acc of 83.3%, exceeding the previous state-of-the-art by more than 20%.
Open-World Dynamic Prompt and Continual Visual Representation Learning
Sep 09, 2024

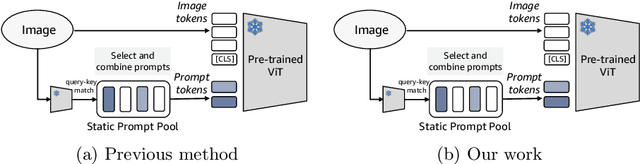

The open world is inherently dynamic, characterized by ever-evolving concepts and distributions. Continual learning (CL) in this dynamic open-world environment presents a significant challenge in effectively generalizing to unseen test-time classes. To address this challenge, we introduce a new practical CL setting tailored for open-world visual representation learning. In this setting, subsequent data streams systematically introduce novel classes that are disjoint from those seen in previous training phases, while also remaining distinct from the unseen test classes. In response, we present Dynamic Prompt and Representation Learner (DPaRL), a simple yet effective Prompt-based CL (PCL) method. Our DPaRL learns to generate dynamic prompts for inference, as opposed to relying on a static prompt pool in previous PCL methods. In addition, DPaRL jointly learns dynamic prompt generation and discriminative representation at each training stage whereas prior PCL methods only refine the prompt learning throughout the process. Our experimental results demonstrate the superiority of our approach, surpassing state-of-the-art methods on well-established open-world image retrieval benchmarks by an average of 4.7\% improvement in Recall@1 performance.
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Mar 26, 2023Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
A Meta-Learning Approach to Predicting Performance and Data Requirements
Mar 02, 2023We propose an approach to estimate the number of samples required for a model to reach a target performance. We find that the power law, the de facto principle to estimate model performance, leads to large error when using a small dataset (e.g., 5 samples per class) for extrapolation. This is because the log-performance error against the log-dataset size follows a nonlinear progression in the few-shot regime followed by a linear progression in the high-shot regime. We introduce a novel piecewise power law (PPL) that handles the two data regimes differently. To estimate the parameters of the PPL, we introduce a random forest regressor trained via meta learning that generalizes across classification/detection tasks, ResNet/ViT based architectures, and random/pre-trained initializations. The PPL improves the performance estimation on average by 37% across 16 classification and 33% across 10 detection datasets, compared to the power law. We further extend the PPL to provide a confidence bound and use it to limit the prediction horizon that reduces over-estimation of data by 76% on classification and 91% on detection datasets.
ComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers
Sep 13, 2022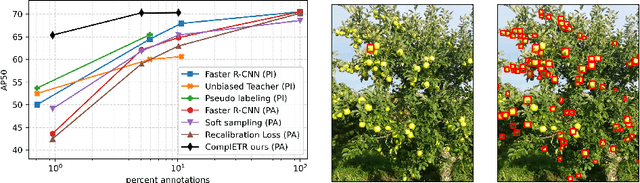
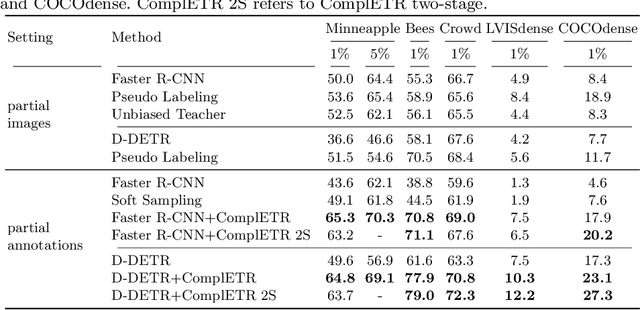
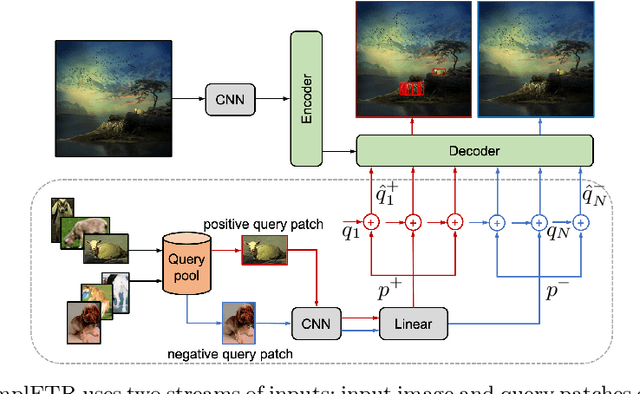
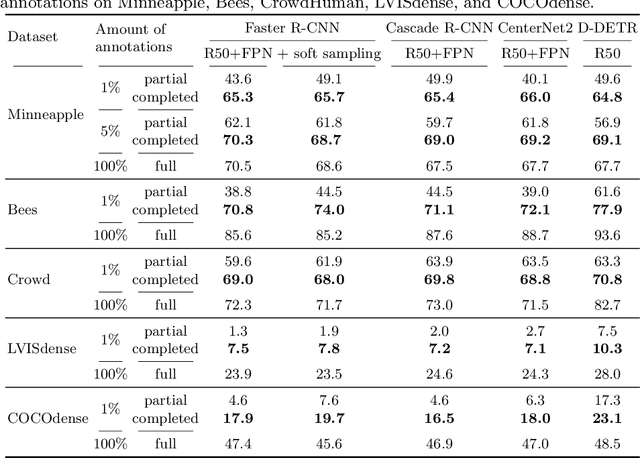
Annotating bounding boxes for object detection is expensive, time-consuming, and error-prone. In this work, we propose a DETR based framework called ComplETR that is designed to explicitly complete missing annotations in partially annotated dense scene datasets. This reduces the need to annotate every object instance in the scene thereby reducing annotation cost. ComplETR augments object queries in DETR decoder with patch information of objects in the image. Combined with a matching loss, it can effectively find objects that are similar to the input patch and complete the missing annotations. We show that our framework outperforms the state-of-the-art methods such as Soft Sampling and Unbiased Teacher by itself, while at the same time can be used in conjunction with these methods to further improve their performance. Our framework is also agnostic to the choice of the downstream object detectors; we show performance improvement for several popular detectors such as Faster R-CNN, Cascade R-CNN, CenterNet2, and Deformable DETR on multiple dense scene datasets.
SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation
Jul 28, 2022



Visual anomaly detection is commonly used in industrial quality inspection. In this paper, we present a new dataset as well as a new self-supervised learning method for ImageNet pre-training to improve anomaly detection and segmentation in 1-class and 2-class 5/10/high-shot training setups. We release the Visual Anomaly (VisA) Dataset consisting of 10,821 high-resolution color images (9,621 normal and 1,200 anomalous samples) covering 12 objects in 3 domains, making it the largest industrial anomaly detection dataset to date. Both image and pixel-level labels are provided. We also propose a new self-supervised framework - SPot-the-difference (SPD) - which can regularize contrastive self-supervised pre-training, such as SimSiam, MoCo and SimCLR, to be more suitable for anomaly detection tasks. Our experiments on VisA and MVTec-AD dataset show that SPD consistently improves these contrastive pre-training baselines and even the supervised pre-training. For example, SPD improves Area Under the Precision-Recall curve (AU-PR) for anomaly segmentation by 5.9% and 6.8% over SimSiam and supervised pre-training respectively in the 2-class high-shot regime. We open-source the project at http://github.com/amazon-research/spot-diff .
Rethinking Few-Shot Object Detection on a Multi-Domain Benchmark
Jul 22, 2022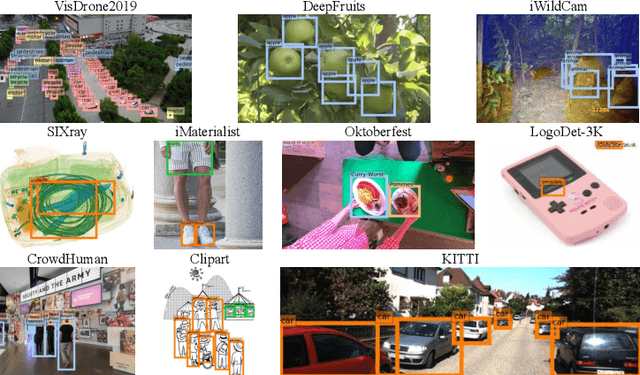
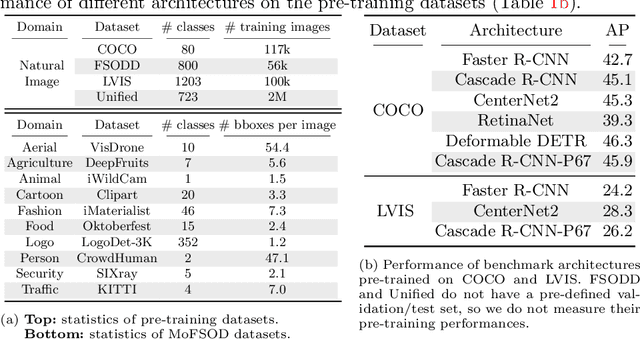
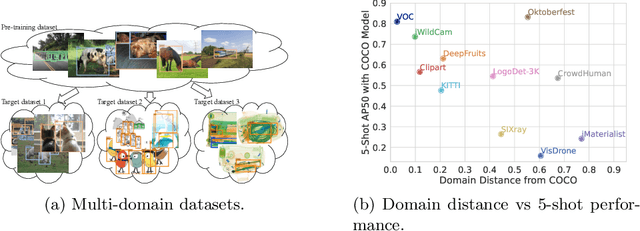
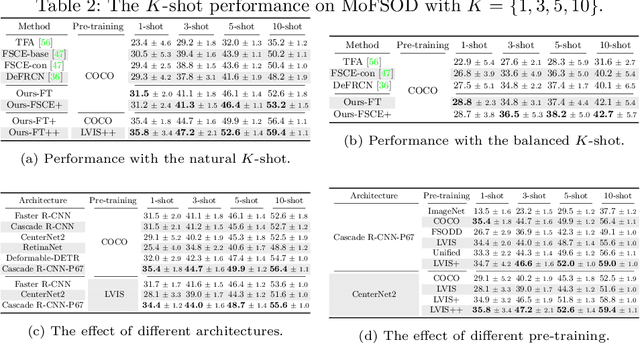
Most existing works on few-shot object detection (FSOD) focus on a setting where both pre-training and few-shot learning datasets are from a similar domain. However, few-shot algorithms are important in multiple domains; hence evaluation needs to reflect the broad applications. We propose a Multi-dOmain Few-Shot Object Detection (MoFSOD) benchmark consisting of 10 datasets from a wide range of domains to evaluate FSOD algorithms. We comprehensively analyze the impacts of freezing layers, different architectures, and different pre-training datasets on FSOD performance. Our empirical results show several key factors that have not been explored in previous works: 1) contrary to previous belief, on a multi-domain benchmark, fine-tuning (FT) is a strong baseline for FSOD, performing on par or better than the state-of-the-art (SOTA) algorithms; 2) utilizing FT as the baseline allows us to explore multiple architectures, and we found them to have a significant impact on down-stream few-shot tasks, even with similar pre-training performances; 3) by decoupling pre-training and few-shot learning, MoFSOD allows us to explore the impact of different pre-training datasets, and the right choice can boost the performance of the down-stream tasks significantly. Based on these findings, we list possible avenues of investigation for improving FSOD performance and propose two simple modifications to existing algorithms that lead to SOTA performance on the MoFSOD benchmark. The code is available at https://github.com/amazon-research/few-shot-object-detection-benchmark.
An End-to-End System for Crowdsourced 3d Maps for Autonomous Vehicles: The Mapping Component
Mar 31, 2017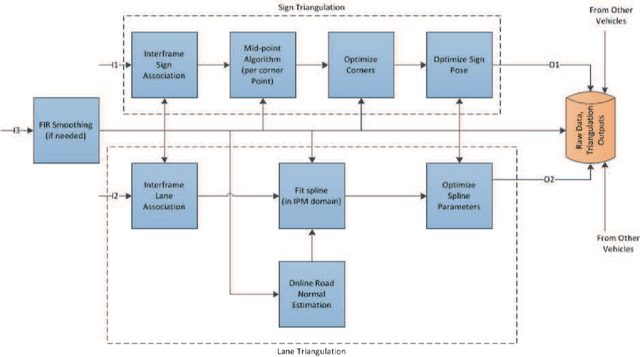
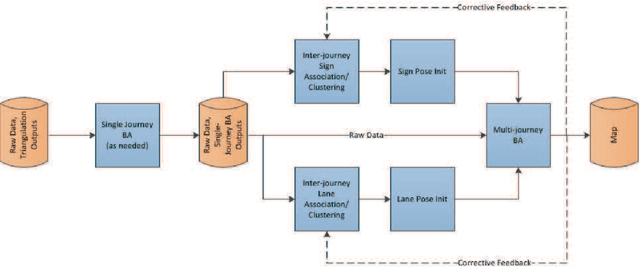
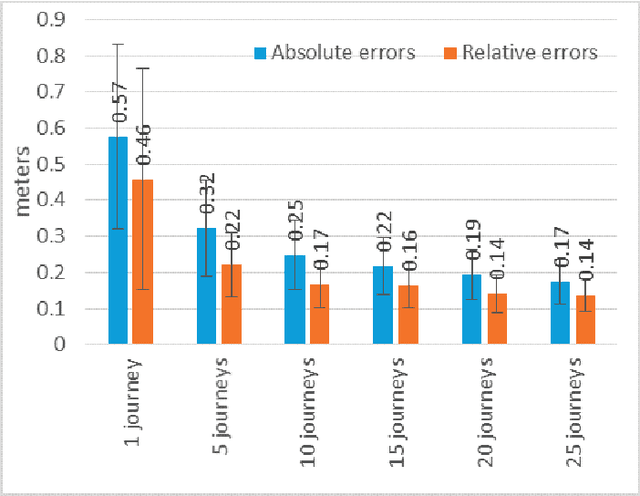
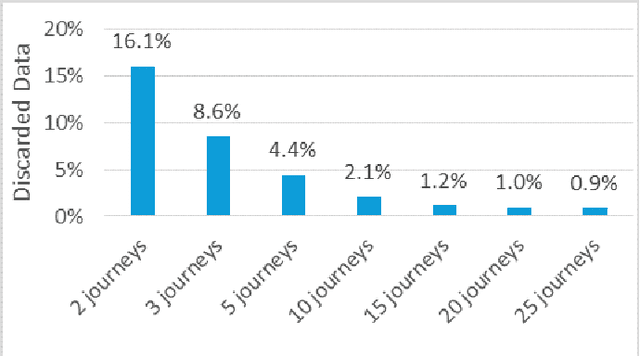
Autonomous vehicles rely on precise high definition (HD) 3d maps for navigation. This paper presents the mapping component of an end-to-end system for crowdsourcing precise 3d maps with semantically meaningful landmarks such as traffic signs (6 dof pose, shape and size) and traffic lanes (3d splines). The system uses consumer grade parts, and in particular, relies on a single front facing camera and a consumer grade GPS. Using real-time sign and lane triangulation on-device in the vehicle, with offline sign/lane clustering across multiple journeys and offline Bundle Adjustment across multiple journeys in the backend, we construct maps with mean absolute accuracy at sign corners of less than 20 cm from 25 journeys. To the best of our knowledge, this is the first end-to-end HD mapping pipeline in global coordinates in the automotive context using cost effective sensors.
Clustered regression with unknown clusters
Mar 23, 2011
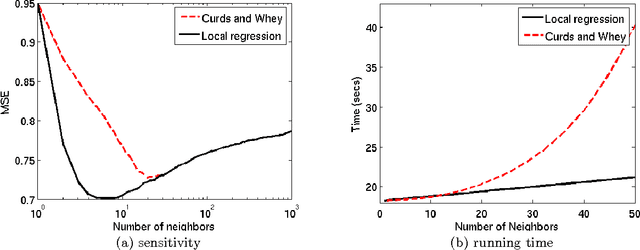
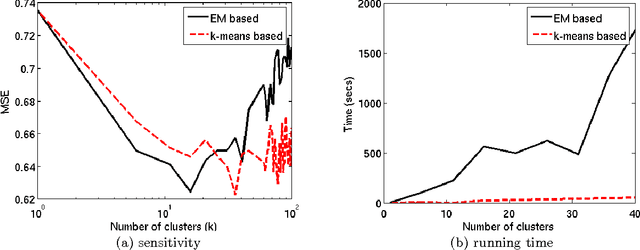

We consider a collection of prediction experiments, which are clustered in the sense that groups of experiments ex- hibit similar relationship between the predictor and response variables. The experiment clusters as well as the regres- sion relationships are unknown. The regression relation- ships define the experiment clusters, and in general, the predictor and response variables may not exhibit any clus- tering. We call this prediction problem clustered regres- sion with unknown clusters (CRUC) and in this paper we focus on linear regression. We study and compare several methods for CRUC, demonstrate their applicability to the Yahoo Learning-to-rank Challenge (YLRC) dataset, and in- vestigate an associated mathematical model. CRUC is at the crossroads of many prior works and we study several prediction algorithms with diverse origins: an adaptation of the expectation-maximization algorithm, an approach in- spired by K-means clustering, the singular value threshold- ing approach to matrix rank minimization under quadratic constraints, an adaptation of the Curds and Whey method in multiple regression, and a local regression (LoR) scheme reminiscent of neighborhood methods in collaborative filter- ing. Based on empirical evaluation on the YLRC dataset as well as simulated data, we identify the LoR method as a good practical choice: it yields best or near-best prediction performance at a reasonable computational load, and it is less sensitive to the choice of the algorithm parameter. We also provide some analysis of the LoR method for an asso- ciated mathematical model, which sheds light on optimal parameter choice and prediction performance.