 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
Jan 08, 2026We introduce Talk2Move, a reinforcement learning (RL) based diffusion framework for text-instructed spatial transformation of objects within scenes. Spatially manipulating objects in a scene through natural language poses a challenge for multimodal generation systems. While existing text-based manipulation methods can adjust appearance or style, they struggle to perform object-level geometric transformations-such as translating, rotating, or resizing objects-due to scarce paired supervision and pixel-level optimization limits. Talk2Move employs Group Relative Policy Optimization (GRPO) to explore geometric actions through diverse rollouts generated from input images and lightweight textual variations, removing the need for costly paired data. A spatial reward guided model aligns geometric transformations with linguistic description, while off-policy step evaluation and active step sampling improve learning efficiency by focusing on informative transformation stages. Furthermore, we design object-centric spatial rewards that evaluate displacement, rotation, and scaling behaviors directly, enabling interpretable and coherent transformations. Experiments on curated benchmarks demonstrate that Talk2Move achieves precise, consistent, and semantically faithful object transformations, outperforming existing text-guided editing approaches in both spatial accuracy and scene coherence.
Open-World Dynamic Prompt and Continual Visual Representation Learning
Sep 09, 2024

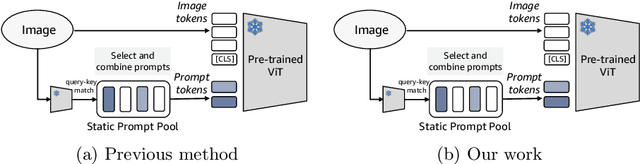

The open world is inherently dynamic, characterized by ever-evolving concepts and distributions. Continual learning (CL) in this dynamic open-world environment presents a significant challenge in effectively generalizing to unseen test-time classes. To address this challenge, we introduce a new practical CL setting tailored for open-world visual representation learning. In this setting, subsequent data streams systematically introduce novel classes that are disjoint from those seen in previous training phases, while also remaining distinct from the unseen test classes. In response, we present Dynamic Prompt and Representation Learner (DPaRL), a simple yet effective Prompt-based CL (PCL) method. Our DPaRL learns to generate dynamic prompts for inference, as opposed to relying on a static prompt pool in previous PCL methods. In addition, DPaRL jointly learns dynamic prompt generation and discriminative representation at each training stage whereas prior PCL methods only refine the prompt learning throughout the process. Our experimental results demonstrate the superiority of our approach, surpassing state-of-the-art methods on well-established open-world image retrieval benchmarks by an average of 4.7\% improvement in Recall@1 performance.
B'MOJO: Hybrid State Space Realizations of Foundation Models with Eidetic and Fading Memory
Jul 08, 2024We describe a family of architectures to support transductive inference by allowing memory to grow to a finite but a-priori unknown bound while making efficient use of finite resources for inference. Current architectures use such resources to represent data either eidetically over a finite span ("context" in Transformers), or fading over an infinite span (in State Space Models, or SSMs). Recent hybrid architectures have combined eidetic and fading memory, but with limitations that do not allow the designer or the learning process to seamlessly modulate the two, nor to extend the eidetic memory span. We leverage ideas from Stochastic Realization Theory to develop a class of models called B'MOJO to seamlessly combine eidetic and fading memory within an elementary composable module. The overall architecture can be used to implement models that can access short-term eidetic memory "in-context," permanent structural memory "in-weights," fading memory "in-state," and long-term eidetic memory "in-storage" by natively incorporating retrieval from an asynchronously updated memory. We show that Transformers, existing SSMs such as Mamba, and hybrid architectures such as Jamba are special cases of B'MOJO and describe a basic implementation, to be open sourced, that can be stacked and scaled efficiently in hardware. We test B'MOJO on transductive inference tasks, such as associative recall, where it outperforms existing SSMs and Hybrid models; as a baseline, we test ordinary language modeling where B'MOJO achieves perplexity comparable to similarly-sized Transformers and SSMs up to 1.4B parameters, while being up to 10% faster to train. Finally, we show that B'MOJO's ability to modulate eidetic and fading memory results in better inference on longer sequences tested up to 32K tokens, four-fold the length of the longest sequences seen during training.
Musketeer (All for One, and One for All): A Generalist Vision-Language Model with Task Explanation Prompts
May 11, 2023We present a sequence-to-sequence vision-language model whose parameters are jointly trained on all tasks (all for one) and fully shared among multiple tasks (one for all), resulting in a single model which we named Musketeer. The integration of knowledge across heterogeneous tasks is enabled by a novel feature called Task Explanation Prompt (TEP). TEP reduces interference among tasks, allowing the model to focus on their shared structure. With a single model, Musketeer achieves results comparable to or better than strong baselines trained on single tasks, almost uniformly across multiple tasks.
ELODI: Ensemble Logit Difference Inhibition for Positive-Congruent Training
May 13, 2022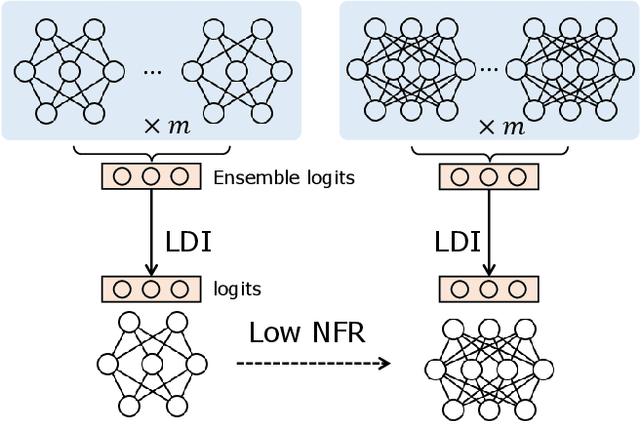
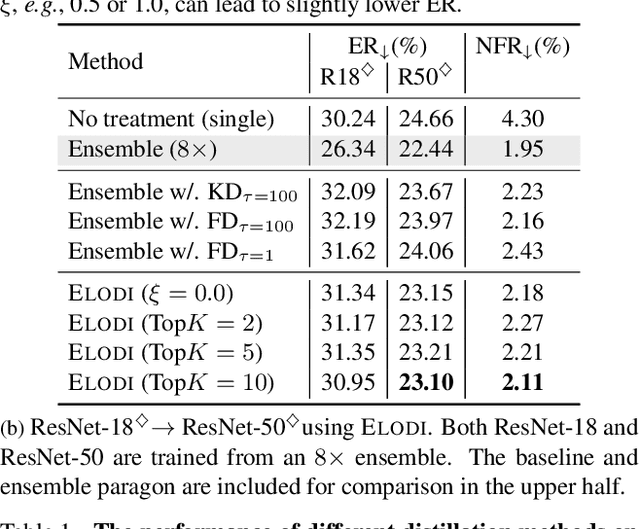
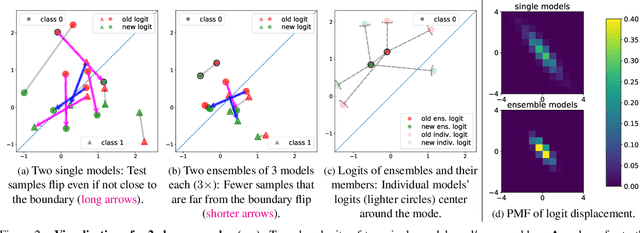
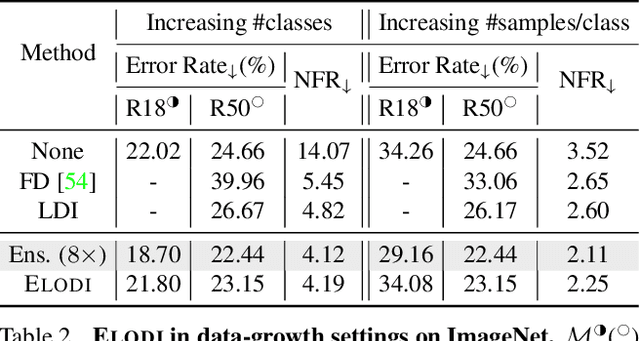
Negative flips are errors introduced in a classification system when a legacy model is replaced with a new one. Existing methods to reduce the negative flip rate (NFR) either do so at the expense of overall accuracy using model distillation, or use ensembles, which multiply inference cost prohibitively. We present a method to train a classification system that achieves paragon performance in both error rate and NFR, at the inference cost of a single model. Our method introduces a generalized distillation objective, Logit Difference Inhibition (LDI), that penalizes changes in the logits between the new and old model, without forcing them to coincide as in ordinary distillation. LDI affords the model flexibility to reduce error rate along with NFR. The method uses a homogeneous ensemble as the reference model for LDI, hence the name Ensemble LDI, or ELODI. The reference model can then be substituted with a single model at inference time. The method leverages the observation that negative flips are typically not close to the decision boundary, but often exhibit large deviations in the distance among their logits, which are reduced by ELODI.
Towards Universal Backward-Compatible Representation Learning
Mar 18, 2022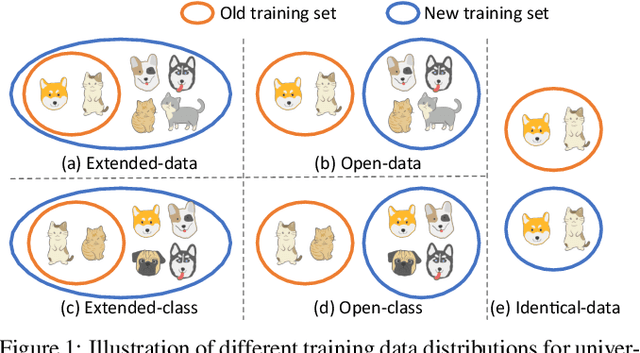
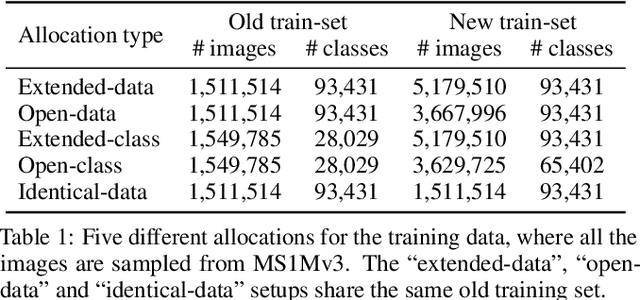
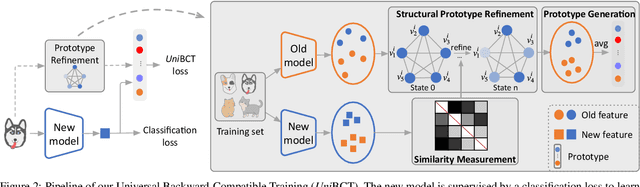
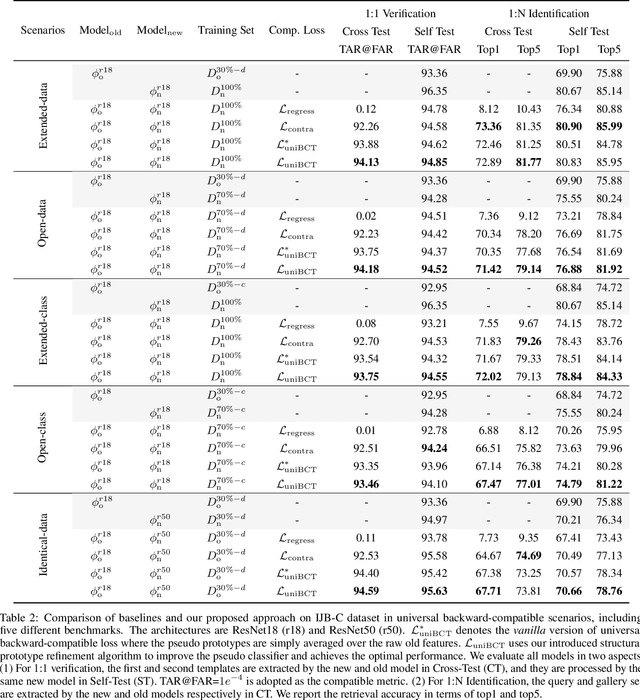
Conventional model upgrades for visual search systems require offline refresh of gallery features by feeding gallery images into new models (dubbed as "backfill"), which is time-consuming and expensive, especially in large-scale applications. The task of backward-compatible representation learning is therefore introduced to support backfill-free model upgrades, where the new query features are interoperable with the old gallery features. Despite the success, previous works only investigated a close-set training scenario (i.e., the new training set shares the same classes as the old one), and are limited by more realistic and challenging open-set scenarios. To this end, we first introduce a new problem of universal backward-compatible representation learning, covering all possible data split in model upgrades. We further propose a simple yet effective method, dubbed as Universal Backward-Compatible Training (UniBCT) with a novel structural prototype refinement algorithm, to learn compatible representations in all kinds of model upgrading benchmarks in a unified manner. Comprehensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C fully demonstrate the effectiveness of our method.
Hot-Refresh Model Upgrades with Regression-Alleviating Compatible Training in Image Retrieval
Jan 24, 2022



The task of hot-refresh model upgrades of image retrieval systems plays an essential role in the industry but has never been investigated in academia before. Conventional cold-refresh model upgrades can only deploy new models after the gallery is overall backfilled, taking weeks or even months for massive data. In contrast, hot-refresh model upgrades deploy the new model immediately and then gradually improve the retrieval accuracy by backfilling the gallery on-the-fly. Compatible training has made it possible, however, the problem of model regression with negative flips poses a great challenge to the stable improvement of user experience. We argue that it is mainly due to the fact that new-to-old positive query-gallery pairs may show less similarity than new-to-new negative pairs. To solve the problem, we introduce a Regression-Alleviating Compatible Training (RACT) method to properly constrain the feature compatibility while reducing negative flips. The core is to encourage the new-to-old positive pairs to be more similar than both the new-to-old negative pairs and the new-to-new negative pairs. An efficient uncertainty-based backfilling strategy is further introduced to fasten accuracy improvements. Extensive experiments on large-scale retrieval benchmarks (e.g., Google Landmark) demonstrate that our RACT effectively alleviates the model regression for one more step towards seamless model upgrades. The code will be available at https://github.com/binjiezhang/RACT_ICLR2022.
Printed Texts Tracking and Following for a Finger-Wearable Electro-Braille System Through Opto-electrotactile Feedback
Aug 06, 2021This paper presents our recent development on a portable and refreshable text reading and sensory substitution system for the blind or visually impaired (BVI), called Finger-eye. The system mainly consists of an opto-text processing unit and a compact electro-tactile based display that can deliver text-related electrical signals to the fingertip skin through a wearable and Braille-dot patterned electrode array and thus delivers the electro-stimulation based Braille touch sensations to the fingertip. To achieve the goal of aiding BVI to read any text not written in Braille through this portable system, in this work, a Rapid Optical Character Recognition (R-OCR) method is firstly developed for real-time processing text information based on a Fisheye imaging device mounted at the finger-wearable electro-tactile display. This allows real-time translation of printed text to electro-Braille along with natural movement of user's fingertip as if reading any Braille display or book. More importantly, an electro-tactile neuro-stimulation feedback mechanism is proposed and incorporated with the R-OCR method, which facilitates a new opto-electrotactile feedback based text line tracking control approach that enables text line following by user fingertip during reading. Multiple experiments were designed and conducted to test the ability of blindfolded participants to read through and follow the text line based on the opto-electrotactile-feedback method. The experiments show that as the result of the opto-electrotactile-feedback, the users were able to maintain their fingertip within a $2mm$ distance of the text while scanning a text line. This research is a significant step to aid the BVI users with a portable means to translate and follow to read any printed text to Braille, whether in the digital realm or physically, on any surface.
Towards Backward-Compatible Representation Learning
Mar 29, 2020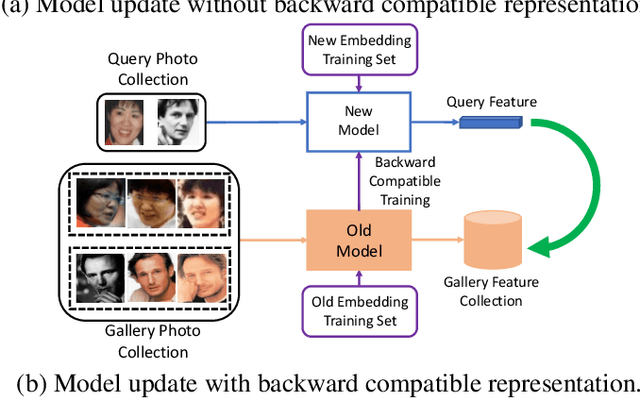
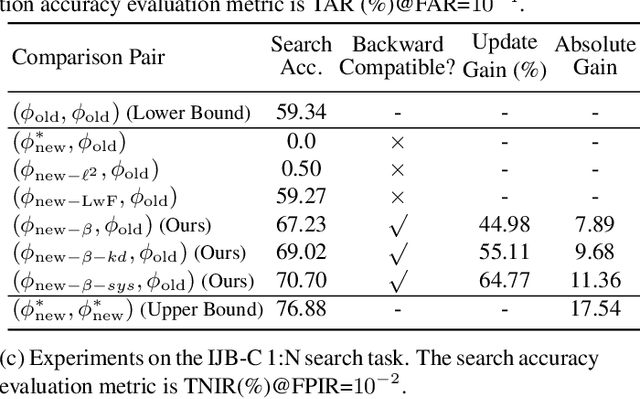

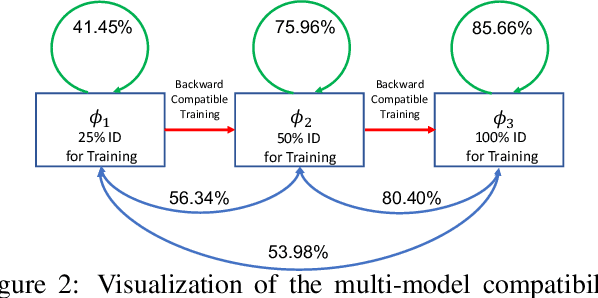
We propose a way to learn visual features that are compatible with previously computed ones even when they have different dimensions and are learned via different neural network architectures and loss functions. Compatible means that, if such features are used to compare images, then "new" features can be compared directly to "old" features, so they can be used interchangeably. This enables visual search systems to bypass computing new features for all previously seen images when updating the embedding models, a process known as backfilling. Backward compatibility is critical to quickly deploy new embedding models that leverage ever-growing large-scale training datasets and improvements in deep learning architectures and training methods. We propose a framework to train embedding models, called backward-compatible training (BCT), as a first step towards backward compatible representation learning. In experiments on learning embeddings for face recognition, models trained with BCT successfully achieve backward compatibility without sacrificing accuracy, thus enabling backfill-free model updates of visual embeddings.
A Comparison of Various Approaches to Reinforcement Learning Algorithms for Multi-robot Box Pushing
Sep 21, 2018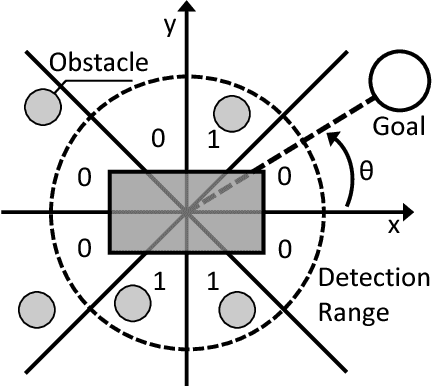
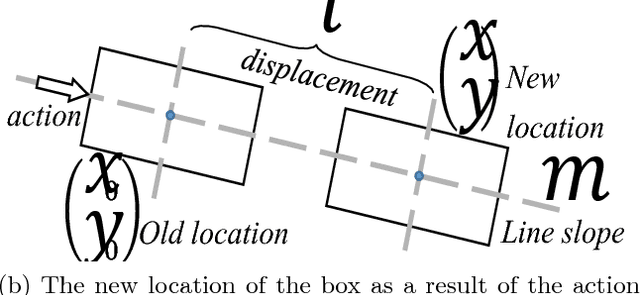
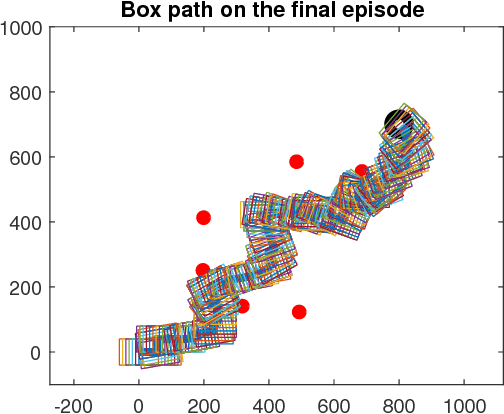
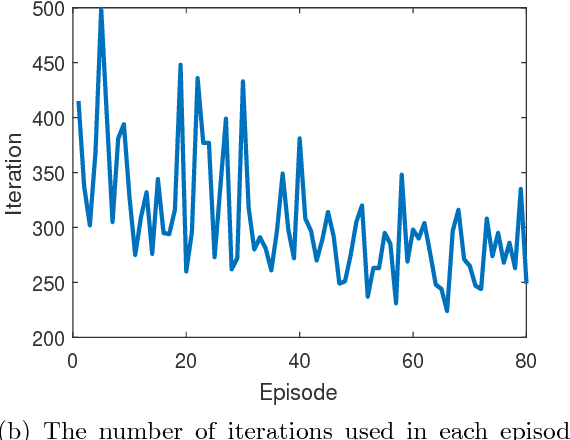
In this paper, a comparison of reinforcement learning algorithms and their performance on a robot box pushing task is provided. The robot box pushing problem is structured as both a single-agent problem and also a multi-agent problem. A Q-learning algorithm is applied to the single-agent box pushing problem, and three different Q-learning algorithms are applied to the multi-agent box pushing problem. Both sets of algorithms are applied on a dynamic environment that is comprised of static objects, a static goal location, a dynamic box location, and dynamic agent positions. A simulation environment is developed to test the four algorithms, and their performance is compared through graphical explanations of test results. The comparison shows that the newly applied reinforcement algorithm out-performs the previously applied algorithms on the robot box pushing problem in a dynamic environment.