 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-centric Predictive Model Conditioned on Hand Trajectories
Aug 28, 2025In egocentric scenarios, anticipating both the next action and its visual outcome is essential for understanding human-object interactions and for enabling robotic planning. However, existing paradigms fall short of jointly modeling these aspects. Vision-Language-Action (VLA) models focus on action prediction but lack explicit modeling of how actions influence the visual scene, while video prediction models generate future frames without conditioning on specific actions, often resulting in implausible or contextually inconsistent outcomes. To bridge this gap, we propose a unified two-stage predictive framework that jointly models action and visual future in egocentric scenarios, conditioned on hand trajectories. In the first stage, we perform consecutive state modeling to process heterogeneous inputs (visual observations, language, and action history) and explicitly predict future hand trajectories. In the second stage, we introduce causal cross-attention to fuse multi-modal cues, leveraging inferred action signals to guide an image-based Latent Diffusion Model (LDM) for frame-by-frame future video generation. Our approach is the first unified model designed to handle both egocentric human activity understanding and robotic manipulation tasks, providing explicit predictions of both upcoming actions and their visual consequences. Extensive experiments on Ego4D, BridgeData, and RLBench demonstrate that our method outperforms state-of-the-art baselines in both action prediction and future video synthesis.
TaCA: Upgrading Your Visual Foundation Model with Task-agnostic Compatible Adapter
Jun 22, 2023Visual foundation models like CLIP excel in learning feature representations from extensive datasets through self-supervised methods, demonstrating remarkable transfer learning and generalization capabilities. A growing number of applications based on visual foundation models are emerging, including innovative solutions such as BLIP-2. These applications employ pre-trained CLIP models as upstream feature extractors and train various downstream modules to accomplish diverse tasks. In situations involving system upgrades that require updating the upstream foundation model, it becomes essential to re-train all downstream modules to adapt to the new foundation model, which is inflexible and inefficient. In this paper, we introduce a parameter-efficient and task-agnostic adapter, dubbed TaCA, that facilitates compatibility across distinct foundation models while ensuring enhanced performance for the new models. TaCA allows downstream applications to seamlessly integrate better-performing foundation models without necessitating retraining. We conduct extensive experimental validation of TaCA using different scales of models with up to one billion parameters on various tasks such as video-text retrieval, video recognition, and visual question answering. The results consistently demonstrate the emergent ability of TaCA on hot-plugging upgrades for visual foundation models. Codes and models will be available at https://github.com/TencentARC/TaCA.
Darwinian Model Upgrades: Model Evolving with Selective Compatibility
Oct 13, 2022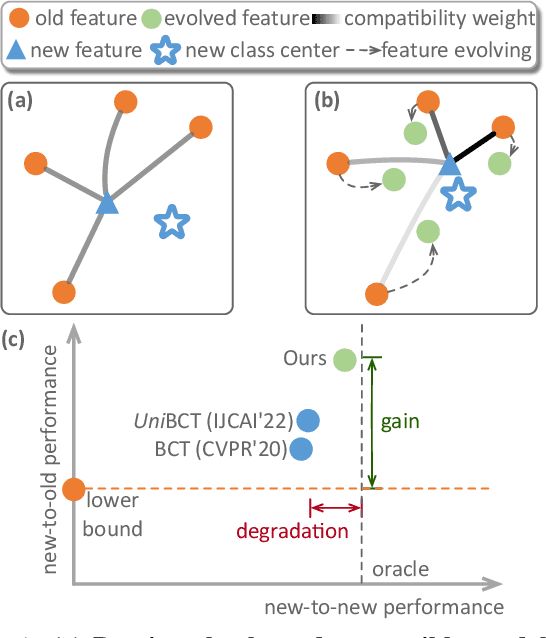
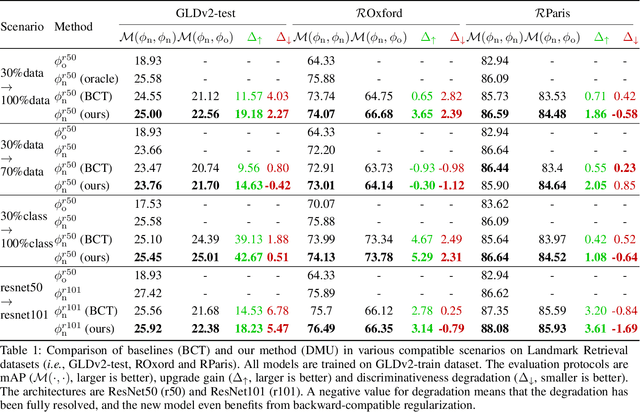
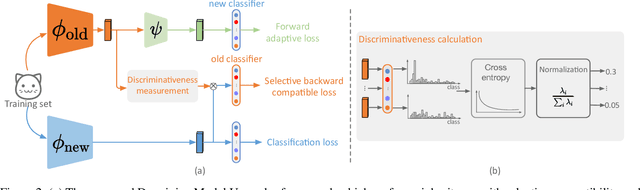
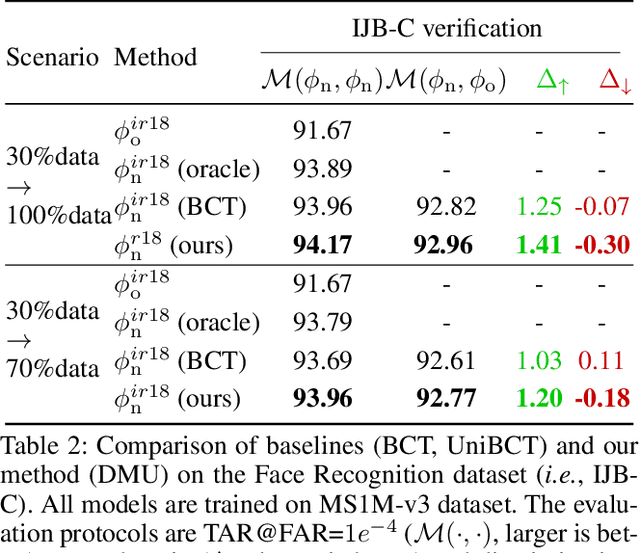
The traditional model upgrading paradigm for retrieval requires recomputing all gallery embeddings before deploying the new model (dubbed as "backfilling"), which is quite expensive and time-consuming considering billions of instances in industrial applications. BCT presents the first step towards backward-compatible model upgrades to get rid of backfilling. It is workable but leaves the new model in a dilemma between new feature discriminativeness and new-to-old compatibility due to the undifferentiated compatibility constraints. In this work, we propose Darwinian Model Upgrades (DMU), which disentangle the inheritance and variation in the model evolving with selective backward compatibility and forward adaptation, respectively. The old-to-new heritable knowledge is measured by old feature discriminativeness, and the gallery features, especially those of poor quality, are evolved in a lightweight manner to become more adaptive in the new latent space. We demonstrate the superiority of DMU through comprehensive experiments on large-scale landmark retrieval and face recognition benchmarks. DMU effectively alleviates the new-to-new degradation and improves new-to-old compatibility, rendering a more proper model upgrading paradigm in large-scale retrieval systems.
Privacy-Preserving Model Upgrades with Bidirectional Compatible Training in Image Retrieval
Apr 29, 2022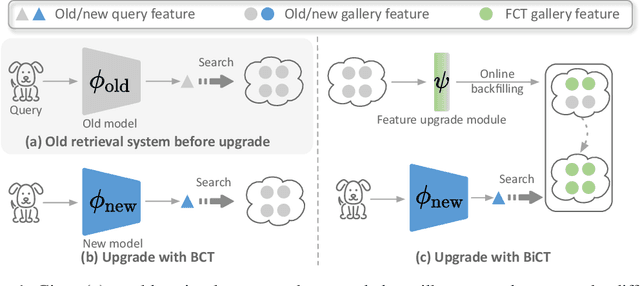

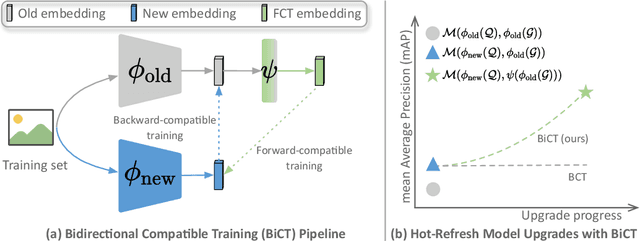

The task of privacy-preserving model upgrades in image retrieval desires to reap the benefits of rapidly evolving new models without accessing the raw gallery images. A pioneering work introduced backward-compatible training, where the new model can be directly deployed in a backfill-free manner, i.e., the new query can be directly compared to the old gallery features. Despite a possible solution, its improvement in sequential model upgrades is gradually limited by the fixed and under-quality old gallery embeddings. To this end, we propose a new model upgrade paradigm, termed Bidirectional Compatible Training (BiCT), which will upgrade the old gallery embeddings by forward-compatible training towards the embedding space of the backward-compatible new model. We conduct comprehensive experiments to verify the prominent improvement by BiCT and interestingly observe that the inconspicuous loss weight of backward compatibility actually plays an essential role for both backward and forward retrieval performance. To summarize, we introduce a new and valuable problem named privacy-preserving model upgrades, with a proper solution BiCT. Several intriguing insights are further proposed to get the most out of our method.
Towards Universal Backward-Compatible Representation Learning
Mar 18, 2022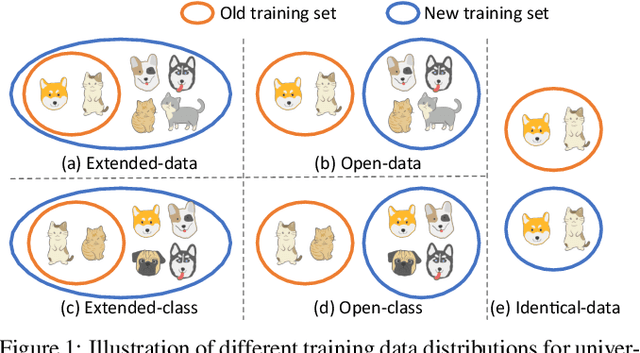
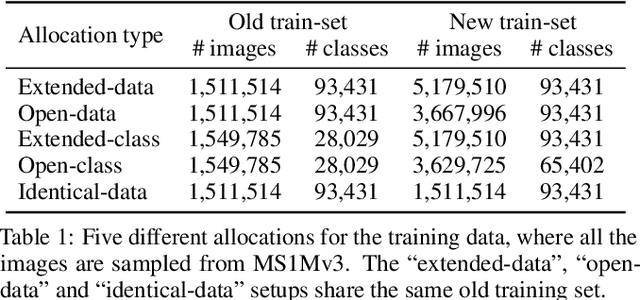
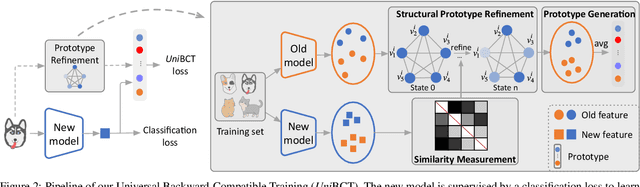
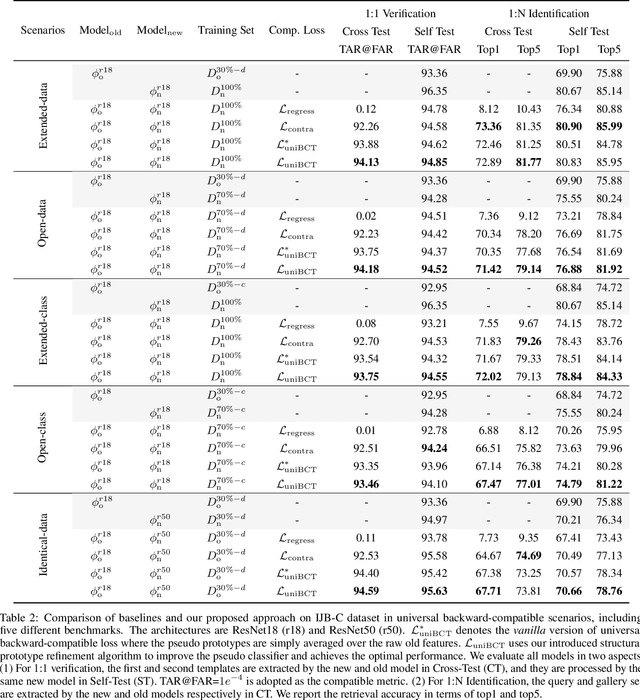
Conventional model upgrades for visual search systems require offline refresh of gallery features by feeding gallery images into new models (dubbed as "backfill"), which is time-consuming and expensive, especially in large-scale applications. The task of backward-compatible representation learning is therefore introduced to support backfill-free model upgrades, where the new query features are interoperable with the old gallery features. Despite the success, previous works only investigated a close-set training scenario (i.e., the new training set shares the same classes as the old one), and are limited by more realistic and challenging open-set scenarios. To this end, we first introduce a new problem of universal backward-compatible representation learning, covering all possible data split in model upgrades. We further propose a simple yet effective method, dubbed as Universal Backward-Compatible Training (UniBCT) with a novel structural prototype refinement algorithm, to learn compatible representations in all kinds of model upgrading benchmarks in a unified manner. Comprehensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C fully demonstrate the effectiveness of our method.
Hot-Refresh Model Upgrades with Regression-Alleviating Compatible Training in Image Retrieval
Jan 24, 2022



The task of hot-refresh model upgrades of image retrieval systems plays an essential role in the industry but has never been investigated in academia before. Conventional cold-refresh model upgrades can only deploy new models after the gallery is overall backfilled, taking weeks or even months for massive data. In contrast, hot-refresh model upgrades deploy the new model immediately and then gradually improve the retrieval accuracy by backfilling the gallery on-the-fly. Compatible training has made it possible, however, the problem of model regression with negative flips poses a great challenge to the stable improvement of user experience. We argue that it is mainly due to the fact that new-to-old positive query-gallery pairs may show less similarity than new-to-new negative pairs. To solve the problem, we introduce a Regression-Alleviating Compatible Training (RACT) method to properly constrain the feature compatibility while reducing negative flips. The core is to encourage the new-to-old positive pairs to be more similar than both the new-to-old negative pairs and the new-to-new negative pairs. An efficient uncertainty-based backfilling strategy is further introduced to fasten accuracy improvements. Extensive experiments on large-scale retrieval benchmarks (e.g., Google Landmark) demonstrate that our RACT effectively alleviates the model regression for one more step towards seamless model upgrades. The code will be available at https://github.com/binjiezhang/RACT_ICLR2022.
A Simple Yet Effective Method for Video Temporal Grounding with Cross-Modality Attention
Sep 23, 2020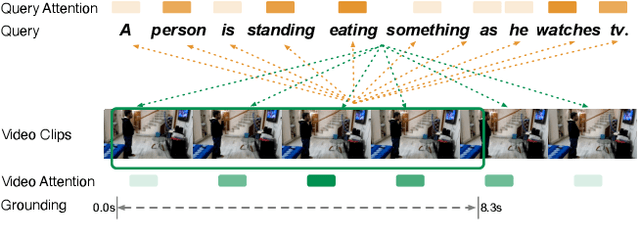
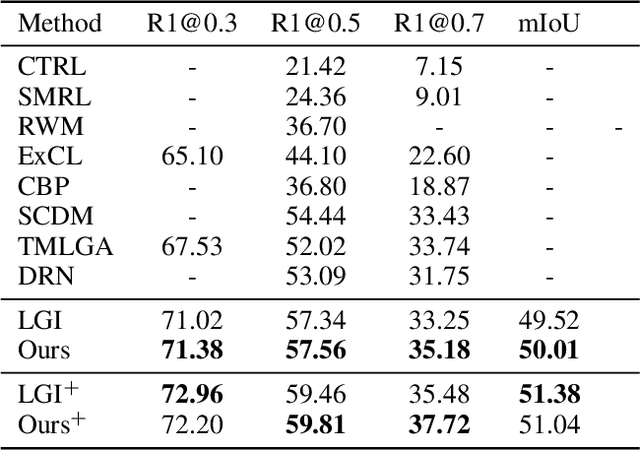
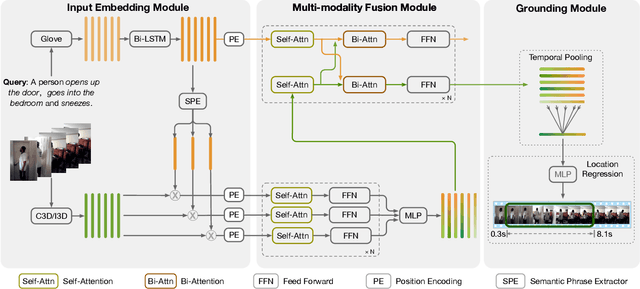
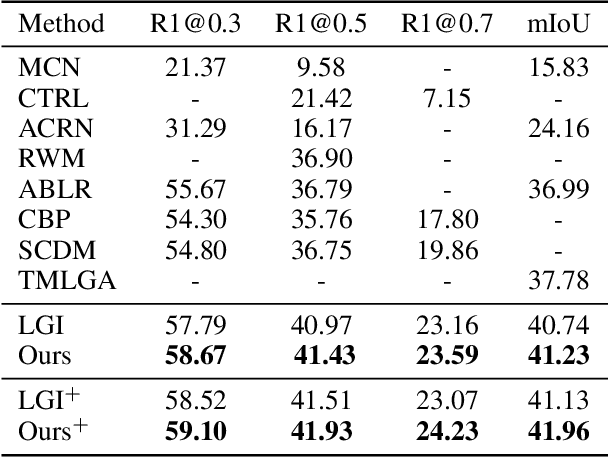
The task of language-guided video temporal grounding is to localize the particular video clip corresponding to a query sentence in an untrimmed video. Though progress has been made continuously in this field, some issues still need to be resolved. First, most of the existing methods rely on the combination of multiple complicated modules to solve the task. Second, due to the semantic gaps between the two different modalities, aligning the information at different granularities (local and global) between the video and the language is significant, which is less addressed. Last, previous works do not consider the inevitable annotation bias due to the ambiguities of action boundaries. To address these limitations, we propose a simple two-branch Cross-Modality Attention (CMA) module with intuitive structure design, which alternatively modulates two modalities for better matching the information both locally and globally. In addition, we introduce a new task-specific regression loss function, which improves the temporal grounding accuracy by alleviating the impact of annotation bias. We conduct extensive experiments to validate our method, and the results show that just with this simple model, it can outperform the state of the arts on both Charades-STA and ActivityNet Captions datasets.