 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTVD: A Large-Scale Plot-Oriented Multimodal Dataset Based on Television Dramas
Jun 26, 2023Art forms such as movies and television (TV) dramas are reflections of the real world, which have attracted much attention from the multimodal learning community recently. However, existing corpora in this domain share three limitations: (1) annotated in a scene-oriented fashion, they ignore the coherence within plots; (2) their text lacks empathy and seldom mentions situational context; (3) their video clips fail to cover long-form relationship due to short duration. To address these fundamental issues, using 1,106 TV drama episodes and 24,875 informative plot-focused sentences written by professionals, with the help of 449 human annotators, we constructed PTVD, the first plot-oriented multimodal dataset in the TV domain. It is also the first non-English dataset of its kind. Additionally, PTVD contains more than 26 million bullet screen comments (BSCs), powering large-scale pre-training. Next, aiming to open-source a strong baseline for follow-up works, we developed the multimodal algorithm that attacks different cinema/TV modelling problems with a unified architecture. Extensive experiments on three cognitive-inspired tasks yielded a number of novel observations (some of them being quite counter-intuition), further validating the value of PTVD in promoting multimodal research. The dataset and codes are released at \url{https://ptvd.github.io/}.
TaCA: Upgrading Your Visual Foundation Model with Task-agnostic Compatible Adapter
Jun 22, 2023Visual foundation models like CLIP excel in learning feature representations from extensive datasets through self-supervised methods, demonstrating remarkable transfer learning and generalization capabilities. A growing number of applications based on visual foundation models are emerging, including innovative solutions such as BLIP-2. These applications employ pre-trained CLIP models as upstream feature extractors and train various downstream modules to accomplish diverse tasks. In situations involving system upgrades that require updating the upstream foundation model, it becomes essential to re-train all downstream modules to adapt to the new foundation model, which is inflexible and inefficient. In this paper, we introduce a parameter-efficient and task-agnostic adapter, dubbed TaCA, that facilitates compatibility across distinct foundation models while ensuring enhanced performance for the new models. TaCA allows downstream applications to seamlessly integrate better-performing foundation models without necessitating retraining. We conduct extensive experimental validation of TaCA using different scales of models with up to one billion parameters on various tasks such as video-text retrieval, video recognition, and visual question answering. The results consistently demonstrate the emergent ability of TaCA on hot-plugging upgrades for visual foundation models. Codes and models will be available at https://github.com/TencentARC/TaCA.
Binary Embedding-based Retrieval at Tencent
Feb 17, 2023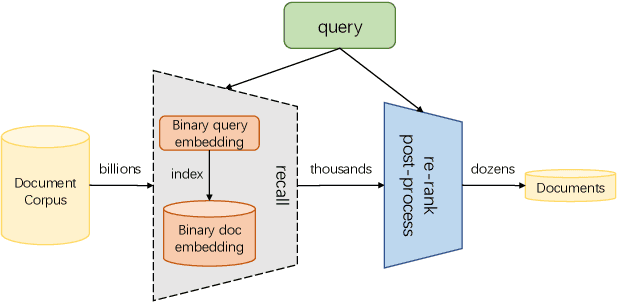

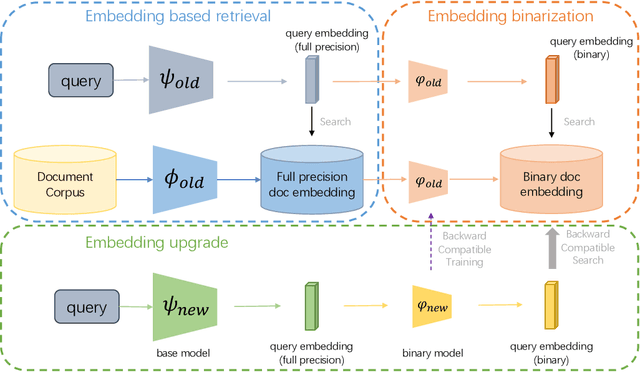

Large-scale embedding-based retrieval (EBR) is the cornerstone of search-related industrial applications. Given a user query, the system of EBR aims to identify relevant information from a large corpus of documents that may be tens or hundreds of billions in size. The storage and computation turn out to be expensive and inefficient with massive documents and high concurrent queries, making it difficult to further scale up. To tackle the challenge, we propose a binary embedding-based retrieval (BEBR) engine equipped with a recurrent binarization algorithm that enables customized bits per dimension. Specifically, we compress the full-precision query and document embeddings, formulated as float vectors in general, into a composition of multiple binary vectors using a lightweight transformation model with residual multilayer perception (MLP) blocks. We can therefore tailor the number of bits for different applications to trade off accuracy loss and cost savings. Importantly, we enable task-agnostic efficient training of the binarization model using a new embedding-to-embedding strategy. We also exploit the compatible training of binary embeddings so that the BEBR engine can support indexing among multiple embedding versions within a unified system. To further realize efficient search, we propose Symmetric Distance Calculation (SDC) to achieve lower response time than Hamming codes. We successfully employed the introduced BEBR to Tencent products, including Sogou, Tencent Video, QQ World, etc. The binarization algorithm can be seamlessly generalized to various tasks with multiple modalities. Extensive experiments on offline benchmarks and online A/B tests demonstrate the efficiency and effectiveness of our method, significantly saving 30%~50% index costs with almost no loss of accuracy at the system level.
Darwinian Model Upgrades: Model Evolving with Selective Compatibility
Oct 13, 2022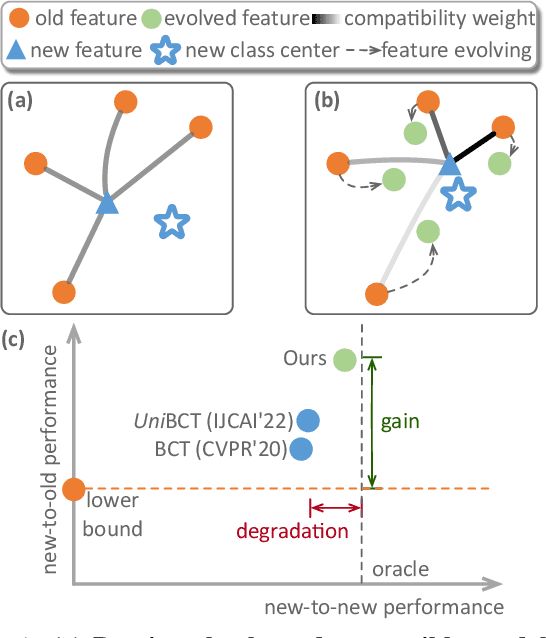
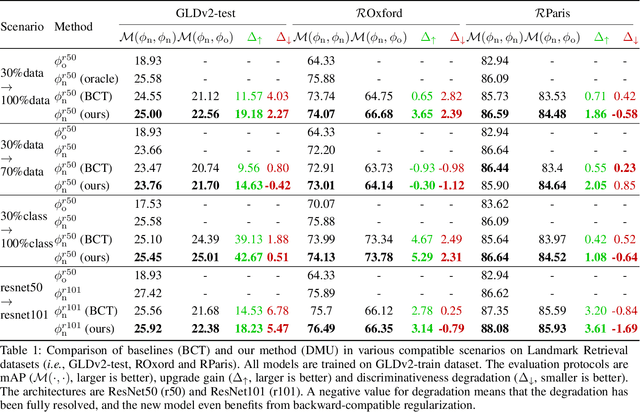
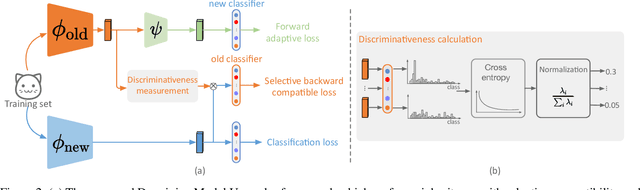
The traditional model upgrading paradigm for retrieval requires recomputing all gallery embeddings before deploying the new model (dubbed as "backfilling"), which is quite expensive and time-consuming considering billions of instances in industrial applications. BCT presents the first step towards backward-compatible model upgrades to get rid of backfilling. It is workable but leaves the new model in a dilemma between new feature discriminativeness and new-to-old compatibility due to the undifferentiated compatibility constraints. In this work, we propose Darwinian Model Upgrades (DMU), which disentangle the inheritance and variation in the model evolving with selective backward compatibility and forward adaptation, respectively. The old-to-new heritable knowledge is measured by old feature discriminativeness, and the gallery features, especially those of poor quality, are evolved in a lightweight manner to become more adaptive in the new latent space. We demonstrate the superiority of DMU through comprehensive experiments on large-scale landmark retrieval and face recognition benchmarks. DMU effectively alleviates the new-to-new degradation and improves new-to-old compatibility, rendering a more proper model upgrading paradigm in large-scale retrieval systems.
Privacy-Preserving Model Upgrades with Bidirectional Compatible Training in Image Retrieval
Apr 29, 2022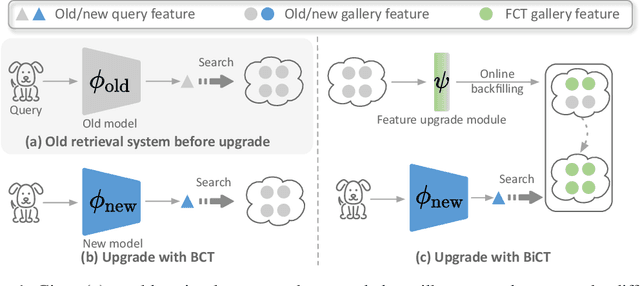

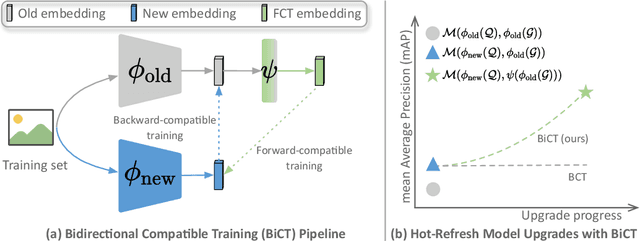

The task of privacy-preserving model upgrades in image retrieval desires to reap the benefits of rapidly evolving new models without accessing the raw gallery images. A pioneering work introduced backward-compatible training, where the new model can be directly deployed in a backfill-free manner, i.e., the new query can be directly compared to the old gallery features. Despite a possible solution, its improvement in sequential model upgrades is gradually limited by the fixed and under-quality old gallery embeddings. To this end, we propose a new model upgrade paradigm, termed Bidirectional Compatible Training (BiCT), which will upgrade the old gallery embeddings by forward-compatible training towards the embedding space of the backward-compatible new model. We conduct comprehensive experiments to verify the prominent improvement by BiCT and interestingly observe that the inconspicuous loss weight of backward compatibility actually plays an essential role for both backward and forward retrieval performance. To summarize, we introduce a new and valuable problem named privacy-preserving model upgrades, with a proper solution BiCT. Several intriguing insights are further proposed to get the most out of our method.
Towards Universal Backward-Compatible Representation Learning
Mar 18, 2022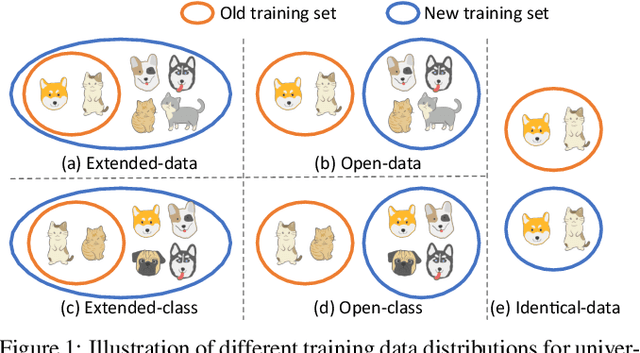
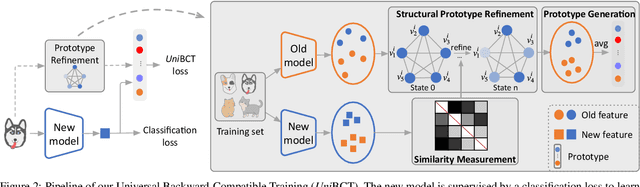
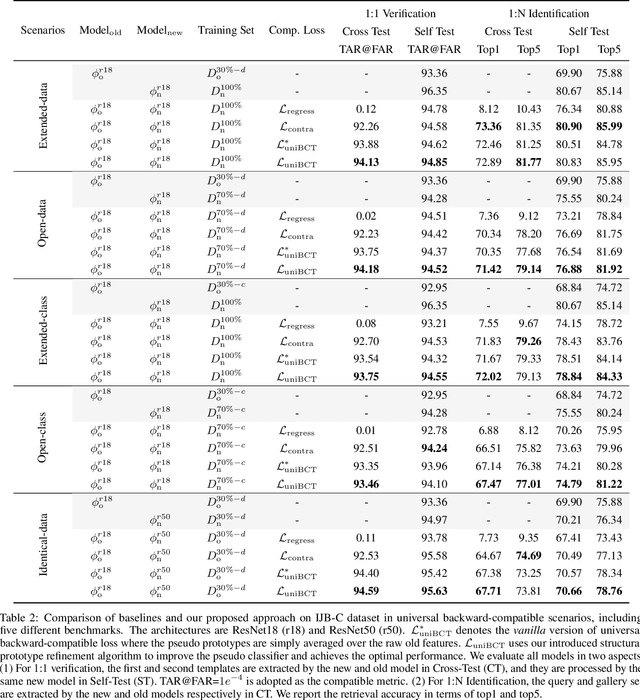
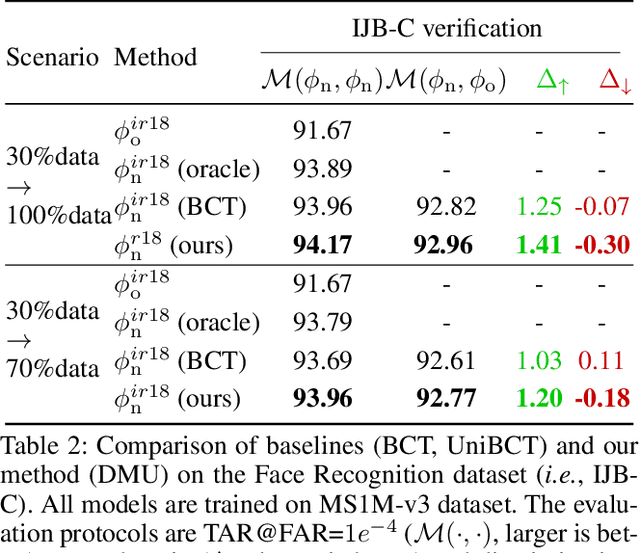
Conventional model upgrades for visual search systems require offline refresh of gallery features by feeding gallery images into new models (dubbed as "backfill"), which is time-consuming and expensive, especially in large-scale applications. The task of backward-compatible representation learning is therefore introduced to support backfill-free model upgrades, where the new query features are interoperable with the old gallery features. Despite the success, previous works only investigated a close-set training scenario (i.e., the new training set shares the same classes as the old one), and are limited by more realistic and challenging open-set scenarios. To this end, we first introduce a new problem of universal backward-compatible representation learning, covering all possible data split in model upgrades. We further propose a simple yet effective method, dubbed as Universal Backward-Compatible Training (UniBCT) with a novel structural prototype refinement algorithm, to learn compatible representations in all kinds of model upgrading benchmarks in a unified manner. Comprehensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C fully demonstrate the effectiveness of our method.
Hot-Refresh Model Upgrades with Regression-Alleviating Compatible Training in Image Retrieval
Jan 24, 2022



The task of hot-refresh model upgrades of image retrieval systems plays an essential role in the industry but has never been investigated in academia before. Conventional cold-refresh model upgrades can only deploy new models after the gallery is overall backfilled, taking weeks or even months for massive data. In contrast, hot-refresh model upgrades deploy the new model immediately and then gradually improve the retrieval accuracy by backfilling the gallery on-the-fly. Compatible training has made it possible, however, the problem of model regression with negative flips poses a great challenge to the stable improvement of user experience. We argue that it is mainly due to the fact that new-to-old positive query-gallery pairs may show less similarity than new-to-new negative pairs. To solve the problem, we introduce a Regression-Alleviating Compatible Training (RACT) method to properly constrain the feature compatibility while reducing negative flips. The core is to encourage the new-to-old positive pairs to be more similar than both the new-to-old negative pairs and the new-to-new negative pairs. An efficient uncertainty-based backfilling strategy is further introduced to fasten accuracy improvements. Extensive experiments on large-scale retrieval benchmarks (e.g., Google Landmark) demonstrate that our RACT effectively alleviates the model regression for one more step towards seamless model upgrades. The code will be available at https://github.com/binjiezhang/RACT_ICLR2022.
3rd Place: A Global and Local Dual Retrieval Solution to Facebook AI Image Similarity Challenge
Dec 29, 2021
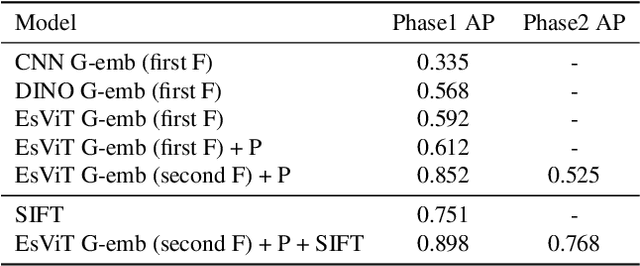
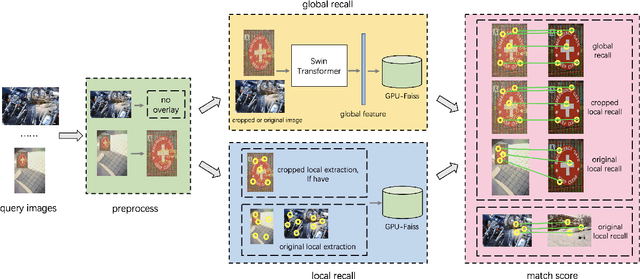
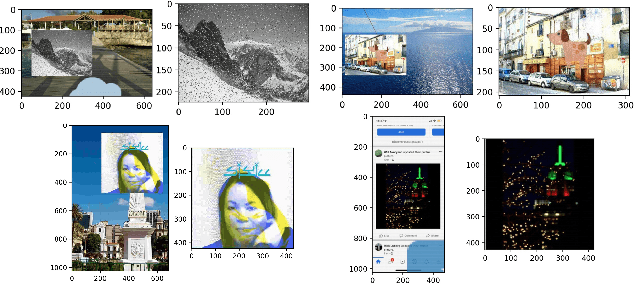
As a basic task of computer vision, image similarity retrieval is facing the challenge of large-scale data and image copy attacks. This paper presents our 3rd place solution to the matching track of Image Similarity Challenge (ISC) 2021 organized by Facebook AI. We propose a multi-branch retrieval method of combining global descriptors and local descriptors to cover all attack cases. Specifically, we attempt many strategies to optimize global descriptors, including abundant data augmentations, self-supervised learning with a single Transformer model, overlay detection preprocessing. Moreover, we introduce the robust SIFT feature and GPU Faiss for local retrieval which makes up for the shortcomings of the global retrieval. Finally, KNN-matching algorithm is used to judge the match and merge scores. We show some ablation experiments of our method, which reveals the complementary advantages of global and local features.
Contrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation
Dec 19, 2021
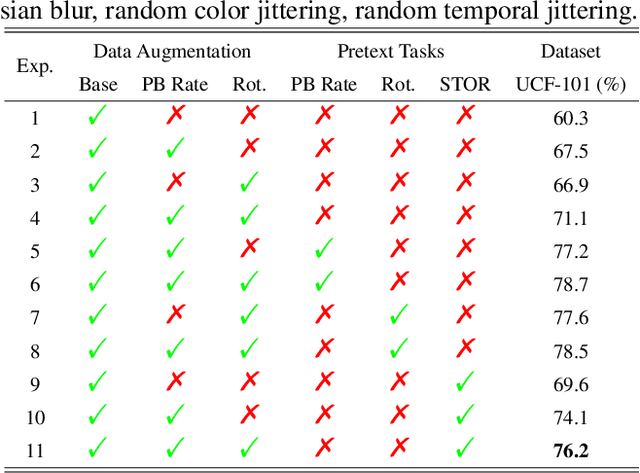
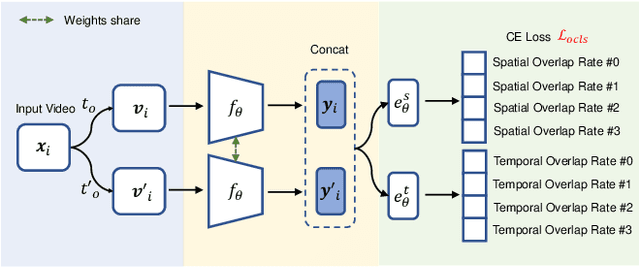
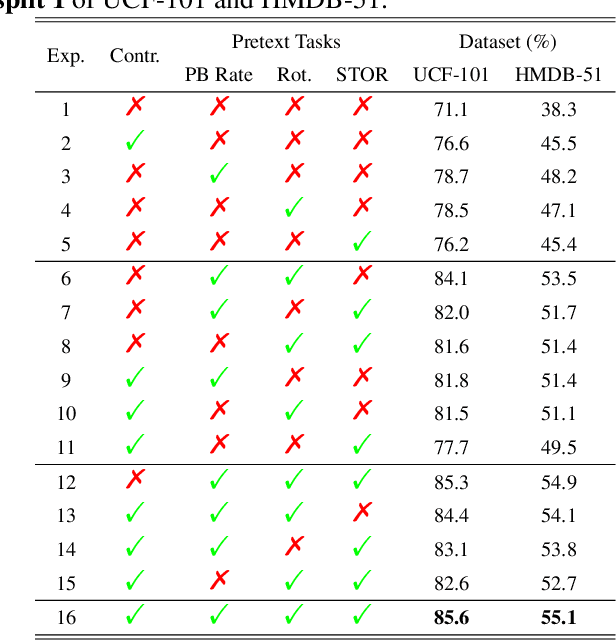
Spatio-temporal representation learning is critical for video self-supervised representation. Recent approaches mainly use contrastive learning and pretext tasks. However, these approaches learn representation by discriminating sampled instances via feature similarity in the latent space while ignoring the intermediate state of the learned representations, which limits the overall performance. In this work, taking into account the degree of similarity of sampled instances as the intermediate state, we propose a novel pretext task - spatio-temporal overlap rate (STOR) prediction. It stems from the observation that humans are capable of discriminating the overlap rates of videos in space and time. This task encourages the model to discriminate the STOR of two generated samples to learn the representations. Moreover, we employ a joint optimization combining pretext tasks with contrastive learning to further enhance the spatio-temporal representation learning. We also study the mutual influence of each component in the proposed scheme. Extensive experiments demonstrate that our proposed STOR task can favor both contrastive learning and pretext tasks. The joint optimization scheme can significantly improve the spatio-temporal representation in video understanding. The code is available at https://github.com/Katou2/CSTP.
Dynamic Token Normalization Improves Vision Transformer
Dec 05, 2021
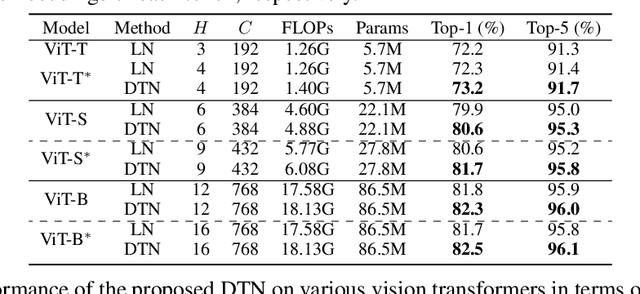


Vision Transformer (ViT) and its variants (e.g., Swin, PVT) have achieved great success in various computer vision tasks, owing to their capability to learn long-range contextual information. Layer Normalization (LN) is an essential ingredient in these models. However, we found that the ordinary LN makes tokens at different positions similar in magnitude because it normalizes embeddings within each token. It is difficult for Transformers to capture inductive bias such as the positional context in an image with LN. We tackle this problem by proposing a new normalizer, termed Dynamic Token Normalization (DTN), where normalization is performed both within each token (intra-token) and across different tokens (inter-token). DTN has several merits. Firstly, it is built on a unified formulation and thus can represent various existing normalization methods. Secondly, DTN learns to normalize tokens in both intra-token and inter-token manners, enabling Transformers to capture both the global contextual information and the local positional context. {Thirdly, by simply replacing LN layers, DTN can be readily plugged into various vision transformers, such as ViT, Swin, PVT, LeViT, T2T-ViT, BigBird and Reformer. Extensive experiments show that the transformer equipped with DTN consistently outperforms baseline model with minimal extra parameters and computational overhead. For example, DTN outperforms LN by $0.5\%$ - $1.2\%$ top-1 accuracy on ImageNet, by $1.2$ - $1.4$ box AP in object detection on COCO benchmark, by $2.3\%$ - $3.9\%$ mCE in robustness experiments on ImageNet-C, and by $0.5\%$ - $0.8\%$ accuracy in Long ListOps on Long-Range Arena.} Codes will be made public at \url{https://github.com/wqshao126/DTN}