 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Embedding-based Retrieval at Tencent
Feb 17, 2023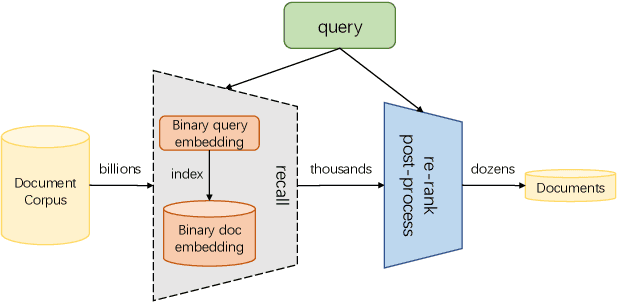

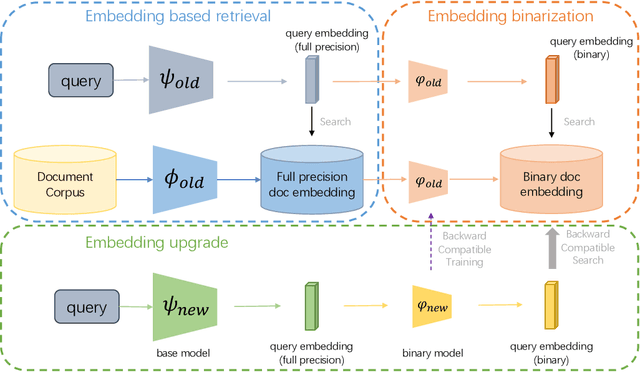

Large-scale embedding-based retrieval (EBR) is the cornerstone of search-related industrial applications. Given a user query, the system of EBR aims to identify relevant information from a large corpus of documents that may be tens or hundreds of billions in size. The storage and computation turn out to be expensive and inefficient with massive documents and high concurrent queries, making it difficult to further scale up. To tackle the challenge, we propose a binary embedding-based retrieval (BEBR) engine equipped with a recurrent binarization algorithm that enables customized bits per dimension. Specifically, we compress the full-precision query and document embeddings, formulated as float vectors in general, into a composition of multiple binary vectors using a lightweight transformation model with residual multilayer perception (MLP) blocks. We can therefore tailor the number of bits for different applications to trade off accuracy loss and cost savings. Importantly, we enable task-agnostic efficient training of the binarization model using a new embedding-to-embedding strategy. We also exploit the compatible training of binary embeddings so that the BEBR engine can support indexing among multiple embedding versions within a unified system. To further realize efficient search, we propose Symmetric Distance Calculation (SDC) to achieve lower response time than Hamming codes. We successfully employed the introduced BEBR to Tencent products, including Sogou, Tencent Video, QQ World, etc. The binarization algorithm can be seamlessly generalized to various tasks with multiple modalities. Extensive experiments on offline benchmarks and online A/B tests demonstrate the efficiency and effectiveness of our method, significantly saving 30%~50% index costs with almost no loss of accuracy at the system level.
Darwinian Model Upgrades: Model Evolving with Selective Compatibility
Oct 13, 2022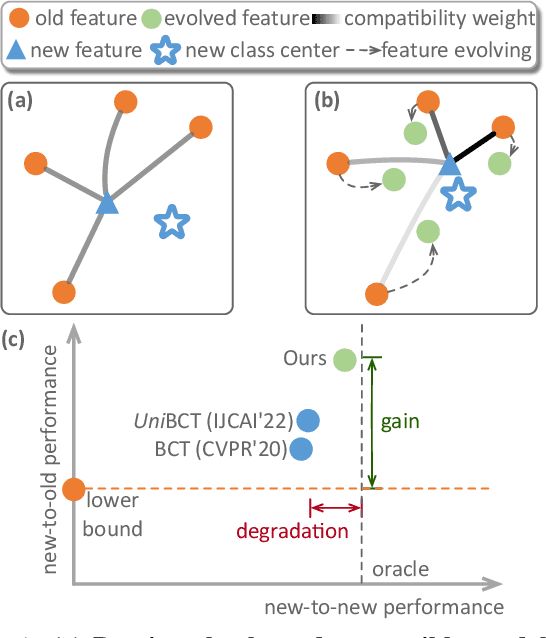
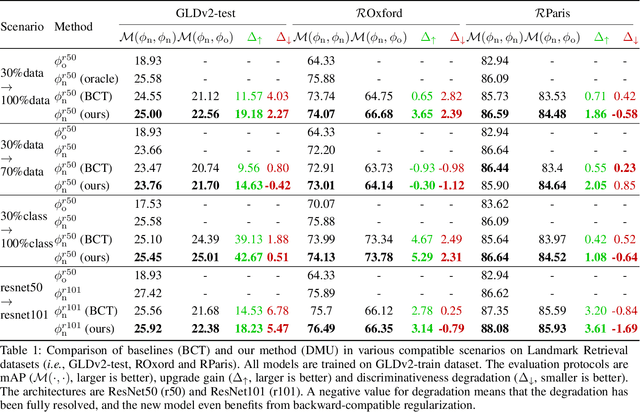
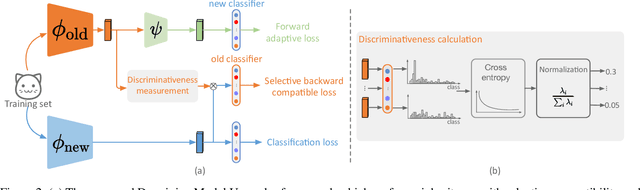
The traditional model upgrading paradigm for retrieval requires recomputing all gallery embeddings before deploying the new model (dubbed as "backfilling"), which is quite expensive and time-consuming considering billions of instances in industrial applications. BCT presents the first step towards backward-compatible model upgrades to get rid of backfilling. It is workable but leaves the new model in a dilemma between new feature discriminativeness and new-to-old compatibility due to the undifferentiated compatibility constraints. In this work, we propose Darwinian Model Upgrades (DMU), which disentangle the inheritance and variation in the model evolving with selective backward compatibility and forward adaptation, respectively. The old-to-new heritable knowledge is measured by old feature discriminativeness, and the gallery features, especially those of poor quality, are evolved in a lightweight manner to become more adaptive in the new latent space. We demonstrate the superiority of DMU through comprehensive experiments on large-scale landmark retrieval and face recognition benchmarks. DMU effectively alleviates the new-to-new degradation and improves new-to-old compatibility, rendering a more proper model upgrading paradigm in large-scale retrieval systems.
Privacy-Preserving Model Upgrades with Bidirectional Compatible Training in Image Retrieval
Apr 29, 2022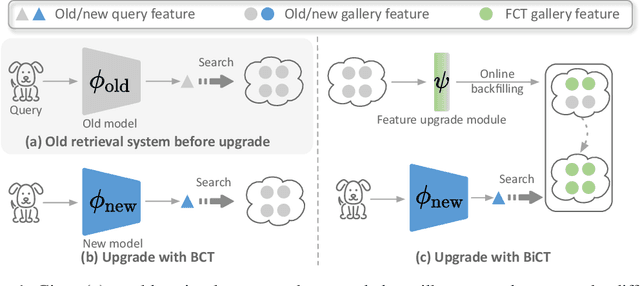

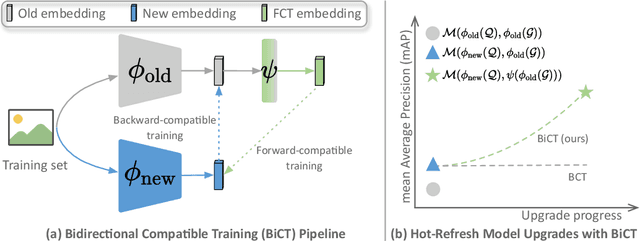

The task of privacy-preserving model upgrades in image retrieval desires to reap the benefits of rapidly evolving new models without accessing the raw gallery images. A pioneering work introduced backward-compatible training, where the new model can be directly deployed in a backfill-free manner, i.e., the new query can be directly compared to the old gallery features. Despite a possible solution, its improvement in sequential model upgrades is gradually limited by the fixed and under-quality old gallery embeddings. To this end, we propose a new model upgrade paradigm, termed Bidirectional Compatible Training (BiCT), which will upgrade the old gallery embeddings by forward-compatible training towards the embedding space of the backward-compatible new model. We conduct comprehensive experiments to verify the prominent improvement by BiCT and interestingly observe that the inconspicuous loss weight of backward compatibility actually plays an essential role for both backward and forward retrieval performance. To summarize, we introduce a new and valuable problem named privacy-preserving model upgrades, with a proper solution BiCT. Several intriguing insights are further proposed to get the most out of our method.
Towards Universal Backward-Compatible Representation Learning
Mar 18, 2022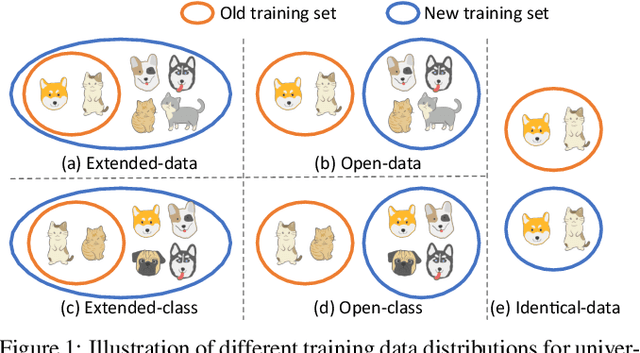
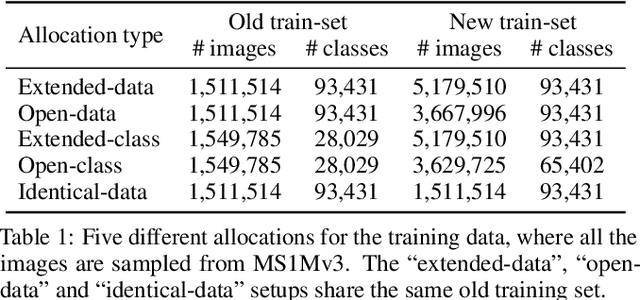
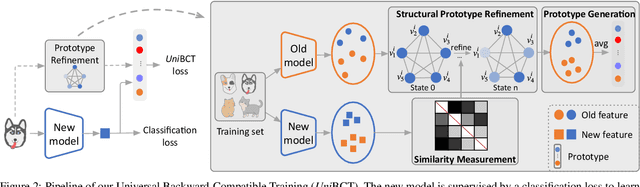
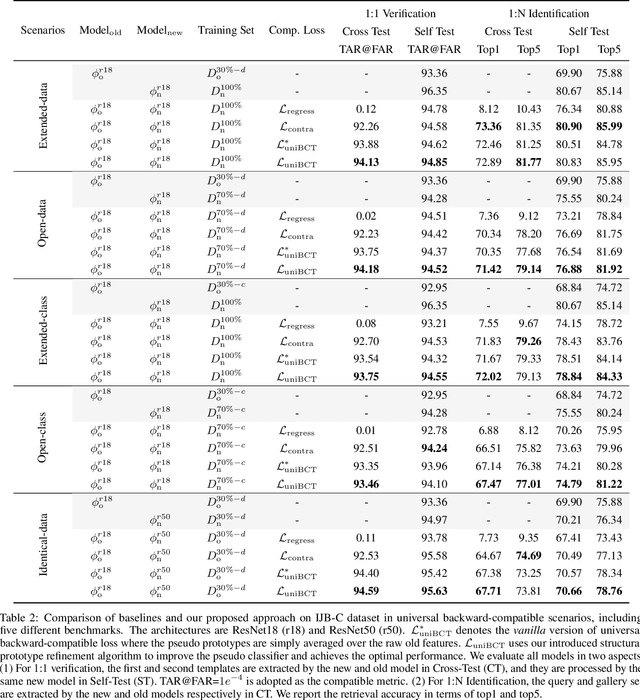
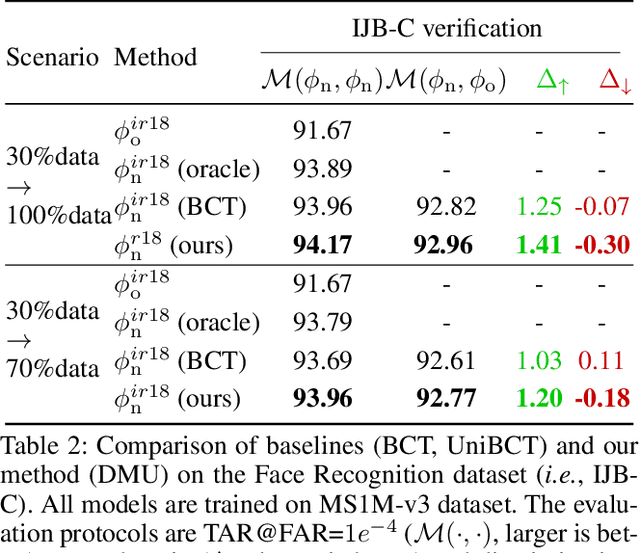
Conventional model upgrades for visual search systems require offline refresh of gallery features by feeding gallery images into new models (dubbed as "backfill"), which is time-consuming and expensive, especially in large-scale applications. The task of backward-compatible representation learning is therefore introduced to support backfill-free model upgrades, where the new query features are interoperable with the old gallery features. Despite the success, previous works only investigated a close-set training scenario (i.e., the new training set shares the same classes as the old one), and are limited by more realistic and challenging open-set scenarios. To this end, we first introduce a new problem of universal backward-compatible representation learning, covering all possible data split in model upgrades. We further propose a simple yet effective method, dubbed as Universal Backward-Compatible Training (UniBCT) with a novel structural prototype refinement algorithm, to learn compatible representations in all kinds of model upgrading benchmarks in a unified manner. Comprehensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C fully demonstrate the effectiveness of our method.