 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-to-symbolic Arrangement via Cross-modal Music Representation Learning
Dec 30, 2021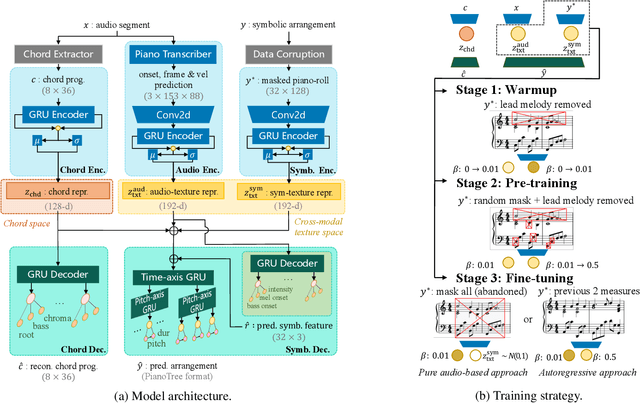
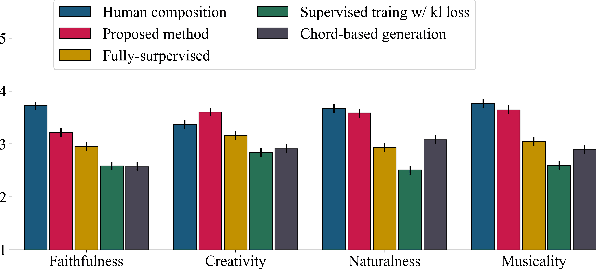
Could we automatically derive the score of a piano accompaniment based on the audio of a pop song? This is the audio-to-symbolic arrangement problem we tackle in this paper. A good arrangement model should not only consider the audio content but also have prior knowledge of piano composition (so that the generation "sounds like" the audio and meanwhile maintains musicality.) To this end, we contribute a cross-modal representation-learning model, which 1) extracts chord and melodic information from the audio, and 2) learns texture representation from both audio and a corrupted ground truth arrangement. We further introduce a tailored training strategy that gradually shifts the source of texture information from corrupted score to audio. In the end, the score-based texture posterior is reduced to a standard normal distribution, and only audio is needed for inference. Experiments show that our model captures major audio information and outperforms baselines in generation quality.
A Simple Yet Effective Method for Video Temporal Grounding with Cross-Modality Attention
Sep 23, 2020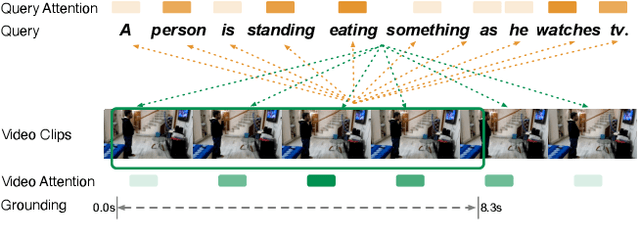
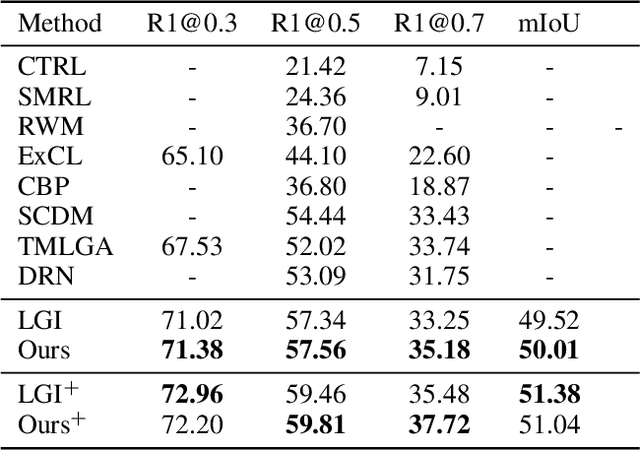
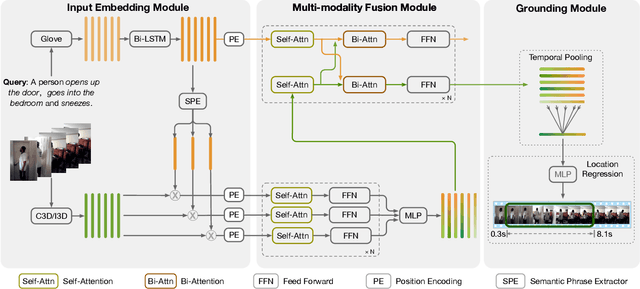
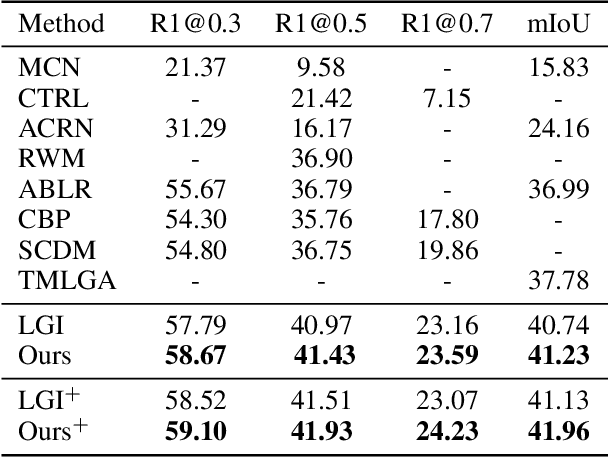
The task of language-guided video temporal grounding is to localize the particular video clip corresponding to a query sentence in an untrimmed video. Though progress has been made continuously in this field, some issues still need to be resolved. First, most of the existing methods rely on the combination of multiple complicated modules to solve the task. Second, due to the semantic gaps between the two different modalities, aligning the information at different granularities (local and global) between the video and the language is significant, which is less addressed. Last, previous works do not consider the inevitable annotation bias due to the ambiguities of action boundaries. To address these limitations, we propose a simple two-branch Cross-Modality Attention (CMA) module with intuitive structure design, which alternatively modulates two modalities for better matching the information both locally and globally. In addition, we introduce a new task-specific regression loss function, which improves the temporal grounding accuracy by alleviating the impact of annotation bias. We conduct extensive experiments to validate our method, and the results show that just with this simple model, it can outperform the state of the arts on both Charades-STA and ActivityNet Captions datasets.
ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering
Jun 06, 2019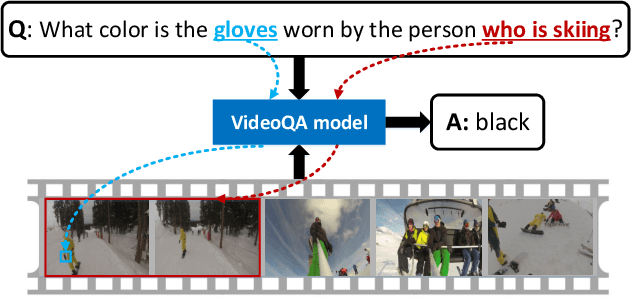

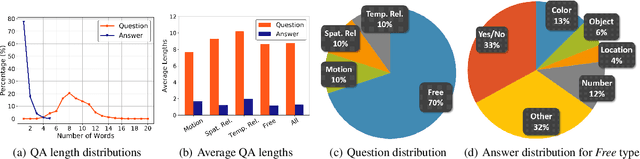
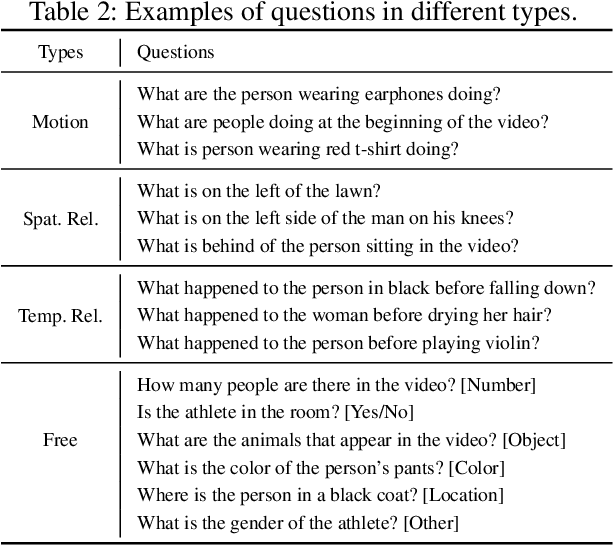
Recent developments in modeling language and vision have been successfully applied to image question answering. It is both crucial and natural to extend this research direction to the video domain for video question answering (VideoQA). Compared to the image domain where large scale and fully annotated benchmark datasets exists, VideoQA datasets are limited to small scale and are automatically generated, etc. These limitations restrict their applicability in practice. Here we introduce ActivityNet-QA, a fully annotated and large scale VideoQA dataset. The dataset consists of 58,000 QA pairs on 5,800 complex web videos derived from the popular ActivityNet dataset. We present a statistical analysis of our ActivityNet-QA dataset and conduct extensive experiments on it by comparing existing VideoQA baselines. Moreover, we explore various video representation strategies to improve VideoQA performance, especially for long videos. The dataset is available at https://github.com/MILVLG/activitynet-qa