 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Gets Heard? Rethinking Fairness in AI for Music Systems
Nov 08, 2025In recent years, the music research community has examined risks of AI models for music, with generative AI models in particular, raised concerns about copyright, deepfakes, and transparency. In our work, we raise concerns about cultural and genre biases in AI for music systems (music-AI systems) which affect stakeholders including creators, distributors, and listeners shaping representation in AI for music. These biases can misrepresent marginalized traditions, especially from the Global South, producing inauthentic outputs (e.g., distorted ragas) that reduces creators' trust on these systems. Such harms risk reinforcing biases, limiting creativity, and contributing to cultural erasure. To address this, we offer recommendations at dataset, model and interface level in music-AI systems.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Music for All: Exploring Multicultural Representations in Music Generation Models
Feb 12, 2025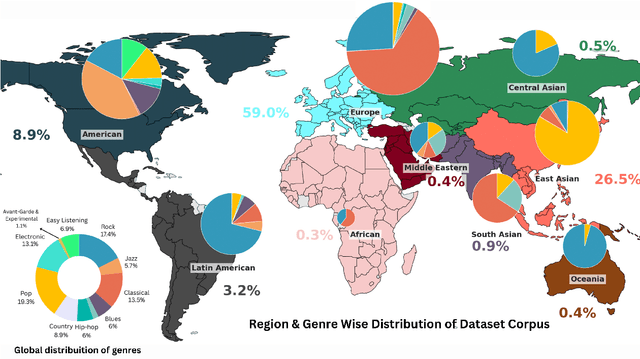

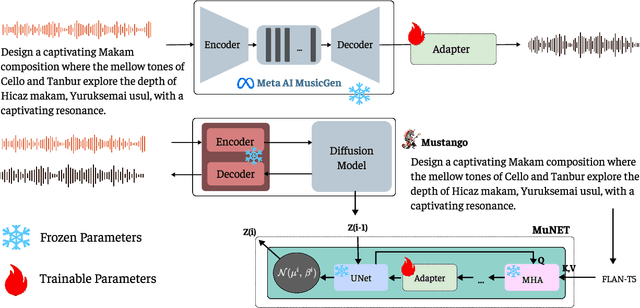
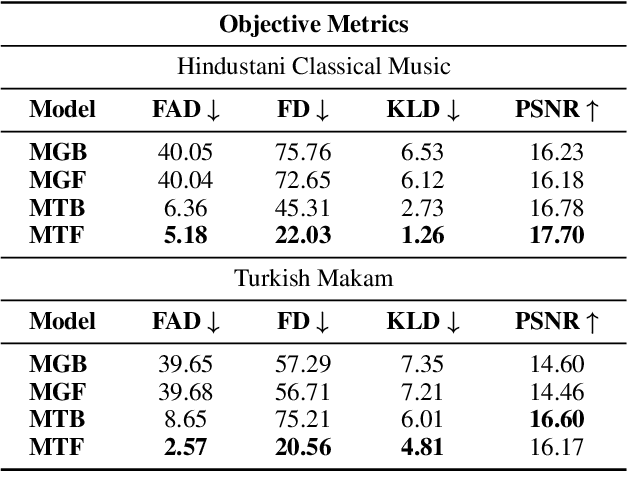
The advent of Music-Language Models has greatly enhanced the automatic music generation capability of AI systems, but they are also limited in their coverage of the musical genres and cultures of the world. We present a study of the datasets and research papers for music generation and quantify the bias and under-representation of genres. We find that only 5.7% of the total hours of existing music datasets come from non-Western genres, which naturally leads to disparate performance of the models across genres. We then investigate the efficacy of Parameter-Efficient Fine-Tuning (PEFT) techniques in mitigating this bias. Our experiments with two popular models -- MusicGen and Mustango, for two underrepresented non-Western music traditions -- Hindustani Classical and Turkish Makam music, highlight the promises as well as the non-triviality of cross-genre adaptation of music through small datasets, implying the need for more equitable baseline music-language models that are designed for cross-cultural transfer learning.
M2M-Gen: A Multimodal Framework for Automated Background Music Generation in Japanese Manga Using Large Language Models
Oct 13, 2024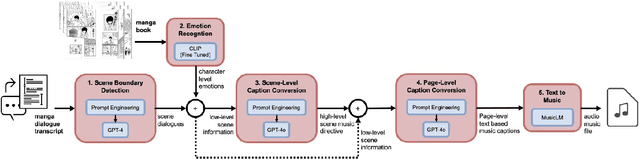

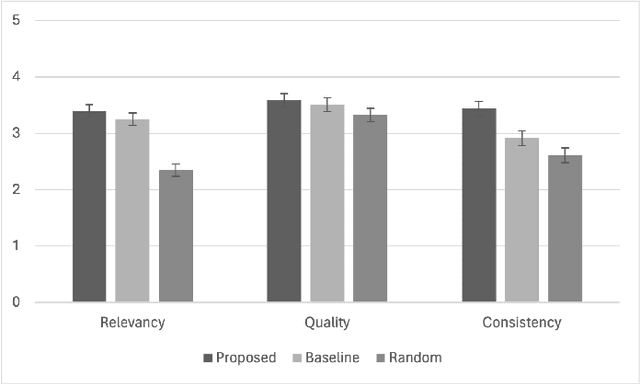
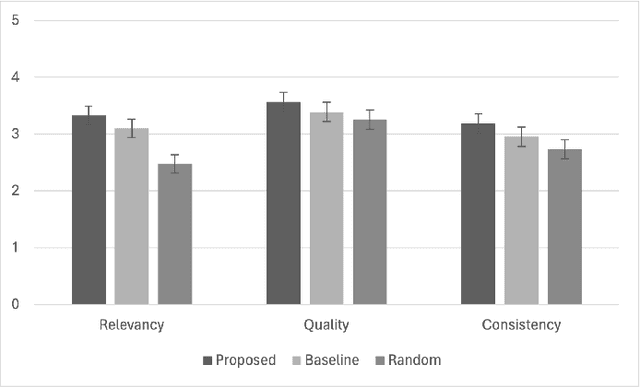
This paper introduces M2M Gen, a multi modal framework for generating background music tailored to Japanese manga. The key challenges in this task are the lack of an available dataset or a baseline. To address these challenges, we propose an automated music generation pipeline that produces background music for an input manga book. Initially, we use the dialogues in a manga to detect scene boundaries and perform emotion classification using the characters faces within a scene. Then, we use GPT4o to translate this low level scene information into a high level music directive. Conditioned on the scene information and the music directive, another instance of GPT 4o generates page level music captions to guide a text to music model. This produces music that is aligned with the mangas evolving narrative. The effectiveness of M2M Gen is confirmed through extensive subjective evaluations, showcasing its capability to generate higher quality, more relevant and consistent music that complements specific scenes when compared to our baselines.
CalliffusionV2: Personalized Natural Calligraphy Generation with Flexible Multi-modal Control
Oct 03, 2024



In this paper, we introduce CalliffusionV2, a novel system designed to produce natural Chinese calligraphy with flexible multi-modal control. Unlike previous approaches that rely solely on image or text inputs and lack fine-grained control, our system leverages both images to guide generations at fine-grained levels and natural language texts to describe the features of generations. CalliffusionV2 excels at creating a broad range of characters and can quickly learn new styles through a few-shot learning approach. It is also capable of generating non-Chinese characters without prior training. Comprehensive tests confirm that our system produces calligraphy that is both stylistically accurate and recognizable by neural network classifiers and human evaluators.
Unlocking Potential in Pre-Trained Music Language Models for Versatile Multi-Track Music Arrangement
Aug 27, 2024



Large language models have shown significant capabilities across various domains, including symbolic music generation. However, leveraging these pre-trained models for controllable music arrangement tasks, each requiring different forms of musical information as control, remains a novel challenge. In this paper, we propose a unified sequence-to-sequence framework that enables the fine-tuning of a symbolic music language model for multiple multi-track arrangement tasks, including band arrangement, piano reduction, drum arrangement, and voice separation. Our experiments demonstrate that the proposed approach consistently achieves higher musical quality compared to task-specific baselines across all four tasks. Furthermore, through additional experiments on probing analysis, we show the pre-training phase equips the model with essential knowledge to understand musical conditions, which is hard to acquired solely through task-specific fine-tuning.
Foundation Models for Music: A Survey
Aug 27, 2024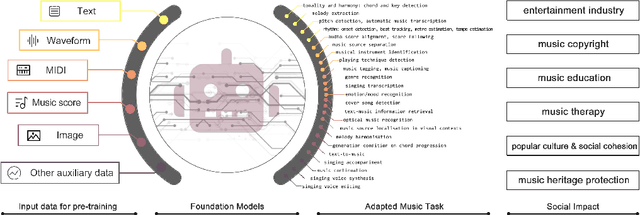

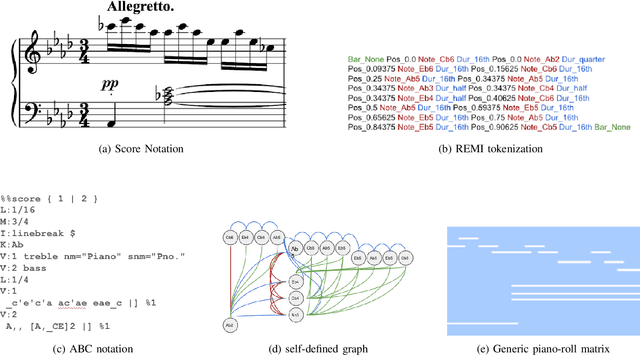
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Emergent Interpretable Symbols and Content-Style Disentanglement via Variance-Invariance Constraints
Jul 04, 2024



We contribute an unsupervised method that effectively learns from raw observation and disentangles its latent space into content and style representations. Unlike most disentanglement algorithms that rely on domain-specific labels and knowledge, our method is based on the insight of domain-general statistical differences between content and style -- content varies more among different fragments within a sample but maintains an invariant vocabulary across data samples, whereas style remains relatively invariant within a sample but exhibits more significant variation across different samples. We integrate such inductive bias into an encoder-decoder architecture and name our method after V3 (variance-versus-invariance). Experimental results show that V3 generalizes across two distinct domains in different modalities, music audio and images of written digits, successfully learning pitch-timbre and digit-color disentanglements, respectively. Also, the disentanglement robustness significantly outperforms baseline unsupervised methods and is even comparable to supervised counterparts. Furthermore, symbolic-level interpretability emerges in the learned codebook of content, forging a near one-to-one alignment between machine representation and human knowledge.
Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
May 29, 2024



Recent advances in text-to-music editing, which employ text queries to modify music (e.g.\ by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
Human-Centered LLM-Agent User Interface: A Position Paper
May 19, 2024Large Language Model (LLM) -in-the-loop applications have been shown to effectively interpret the human user's commands, make plans, and operate external tools/systems accordingly. Still, the operation scope of the LLM agent is limited to passively following the user, requiring the user to frame his/her needs with regard to the underlying tools/systems. We note that the potential of an LLM-Agent User Interface (LAUI) is much greater. A user mostly ignorant to the underlying tools/systems should be able to work with a LAUI to discover an emergent workflow. Contrary to the conventional way of designing an explorable GUI to teach the user a predefined set of ways to use the system, in the ideal LAUI, the LLM agent is initialized to be proficient with the system, proactively studies the user and his/her needs, and proposes new interaction schemes to the user. To illustrate LAUI, we present Flute X GPT, a concrete example using an LLM agent, a prompt manager, and a flute-tutoring multi-modal software-hardware system to facilitate the complex, real-time user experience of learning to play the flute.