 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic for All: Exploring Multicultural Representations in Music Generation Models
Paper and Code
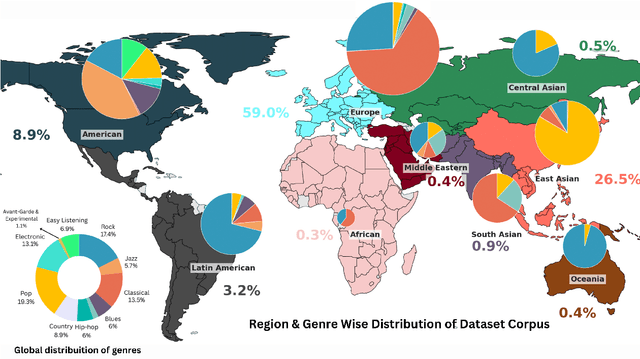

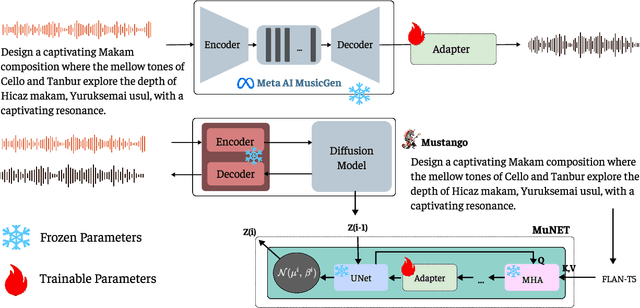
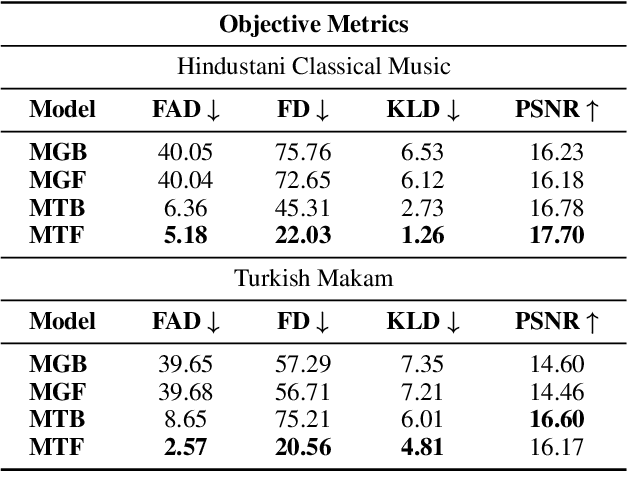
The advent of Music-Language Models has greatly enhanced the automatic music generation capability of AI systems, but they are also limited in their coverage of the musical genres and cultures of the world. We present a study of the datasets and research papers for music generation and quantify the bias and under-representation of genres. We find that only 5.7% of the total hours of existing music datasets come from non-Western genres, which naturally leads to disparate performance of the models across genres. We then investigate the efficacy of Parameter-Efficient Fine-Tuning (PEFT) techniques in mitigating this bias. Our experiments with two popular models -- MusicGen and Mustango, for two underrepresented non-Western music traditions -- Hindustani Classical and Turkish Makam music, highlight the promises as well as the non-triviality of cross-genre adaptation of music through small datasets, implying the need for more equitable baseline music-language models that are designed for cross-cultural transfer learning.