 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparQLe: Speech Queries to Text Translation Through LLMs
Feb 13, 2025



With the growing influence of Large Language Models (LLMs), there is increasing interest in integrating speech representations with them to enable more seamless multi-modal processing and speech understanding. This study introduces a novel approach that leverages self-supervised speech representations in combination with instruction-tuned LLMs for speech-to-text translation. The proposed approach leverages a modality adapter to align extracted speech features with instruction-tuned LLMs using English-language data. Our experiments demonstrate that this method effectively preserves the semantic content of the input speech and serves as an effective bridge between self-supervised speech models and instruction-tuned LLMs, offering a promising solution for various speech understanding applications.
Music for All: Exploring Multicultural Representations in Music Generation Models
Feb 12, 2025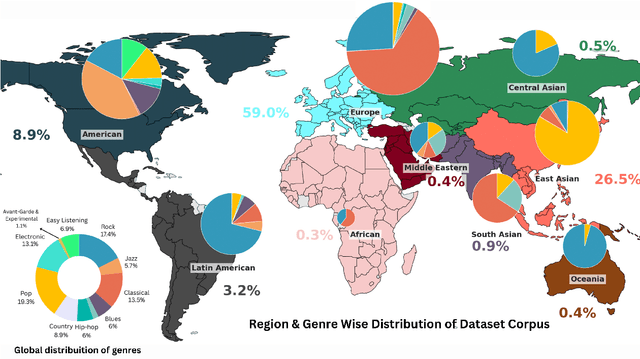

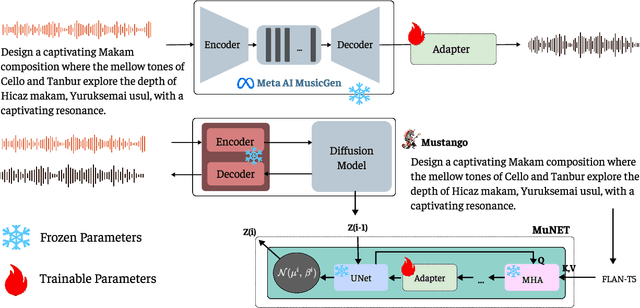
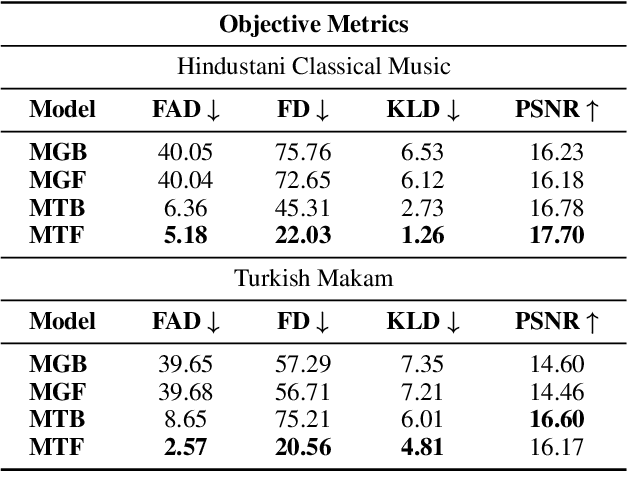
The advent of Music-Language Models has greatly enhanced the automatic music generation capability of AI systems, but they are also limited in their coverage of the musical genres and cultures of the world. We present a study of the datasets and research papers for music generation and quantify the bias and under-representation of genres. We find that only 5.7% of the total hours of existing music datasets come from non-Western genres, which naturally leads to disparate performance of the models across genres. We then investigate the efficacy of Parameter-Efficient Fine-Tuning (PEFT) techniques in mitigating this bias. Our experiments with two popular models -- MusicGen and Mustango, for two underrepresented non-Western music traditions -- Hindustani Classical and Turkish Makam music, highlight the promises as well as the non-triviality of cross-genre adaptation of music through small datasets, implying the need for more equitable baseline music-language models that are designed for cross-cultural transfer learning.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
Dialectal Coverage And Generalization in Arabic Speech Recognition
Nov 07, 2024



Developing robust automatic speech recognition (ASR) systems for Arabic, a language characterized by its rich dialectal diversity and often considered a low-resource language in speech technology, demands effective strategies to manage its complexity. This study explores three critical factors influencing ASR performance: the role of dialectal coverage in pre-training, the effectiveness of dialect-specific fine-tuning compared to a multi-dialectal approach, and the ability to generalize to unseen dialects. Through extensive experiments across different dialect combinations, our findings offer key insights towards advancing the development of ASR systems for pluricentric languages like Arabic.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024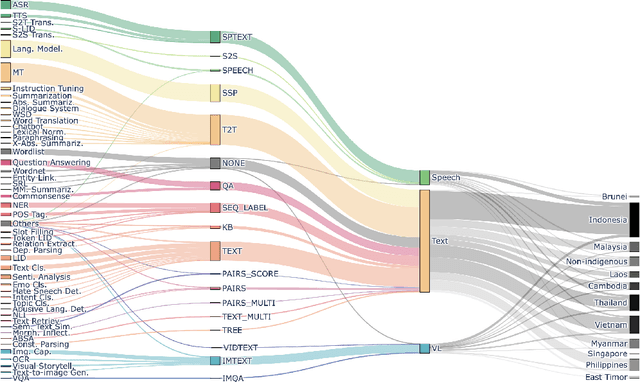
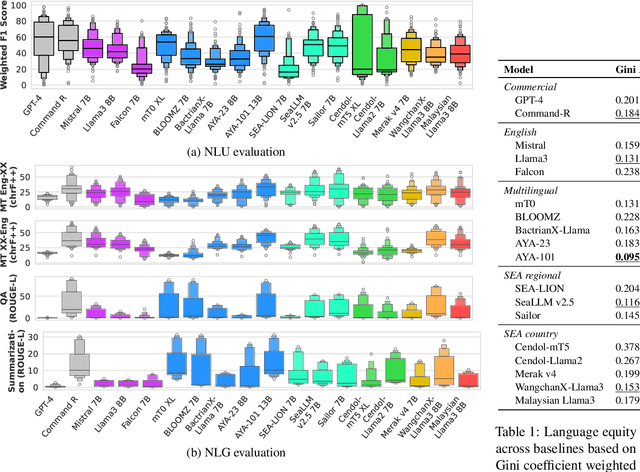
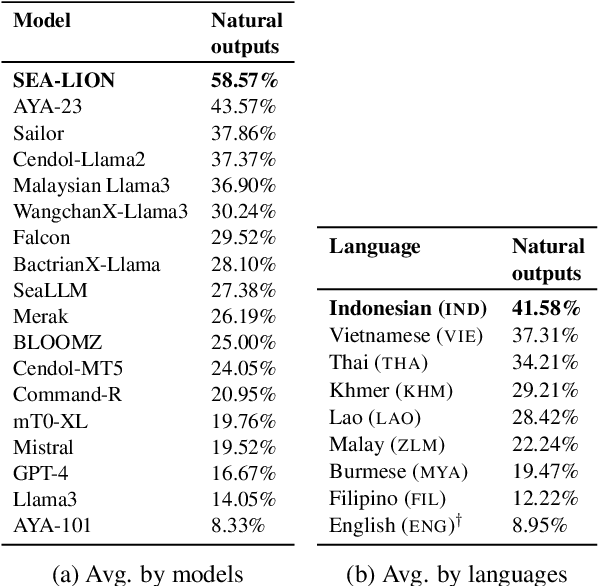
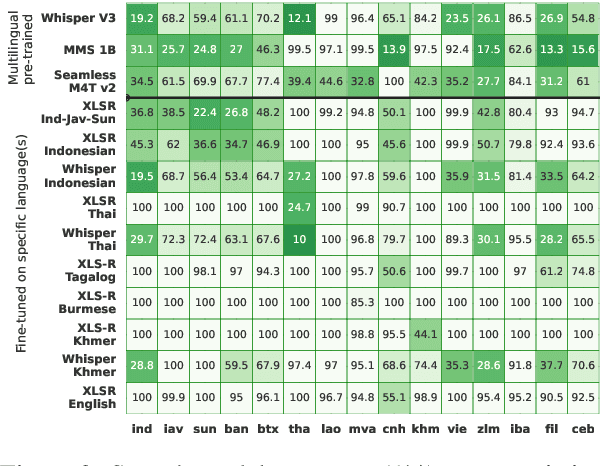
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
ArTST: Arabic Text and Speech Transformer
Oct 25, 2023We present ArTST, a pre-trained Arabic text and speech transformer for supporting open-source speech technologies for the Arabic language. The model architecture follows the unified-modal framework, SpeechT5, that was recently released for English, and is focused on Modern Standard Arabic (MSA), with plans to extend the model for dialectal and code-switched Arabic in future editions. We pre-trained the model from scratch on MSA speech and text data, and fine-tuned it for the following tasks: Automatic Speech Recognition (ASR), Text-To-Speech synthesis (TTS), and spoken dialect identification. In our experiments comparing ArTST with SpeechT5, as well as with previously reported results in these tasks, ArTST performs on a par with or exceeding the current state-of-the-art in all three tasks. Moreover, we find that our pre-training is conducive for generalization, which is particularly evident in the low-resource TTS task. The pre-trained model as well as the fine-tuned ASR and TTS models are released for research use.