 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs Good Text Diacritizers? An Arabic and Yorùbá Case Study
Jun 13, 2025We investigate the effectiveness of large language models (LLMs) for text diacritization in two typologically distinct languages: Arabic and Yoruba. To enable a rigorous evaluation, we introduce a novel multilingual dataset MultiDiac, with diverse samples that capture a range of diacritic ambiguities. We evaluate 14 LLMs varying in size, accessibility, and language coverage, and benchmark them against 6 specialized diacritization models. Additionally, we fine-tune four small open-source models using LoRA for Yoruba. Our results show that many off-the-shelf LLMs outperform specialized diacritization models for both Arabic and Yoruba, but smaller models suffer from hallucinations. Fine-tuning on a small dataset can help improve diacritization performance and reduce hallucination rates.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025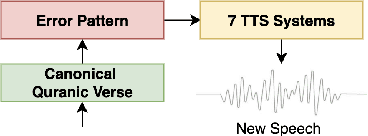
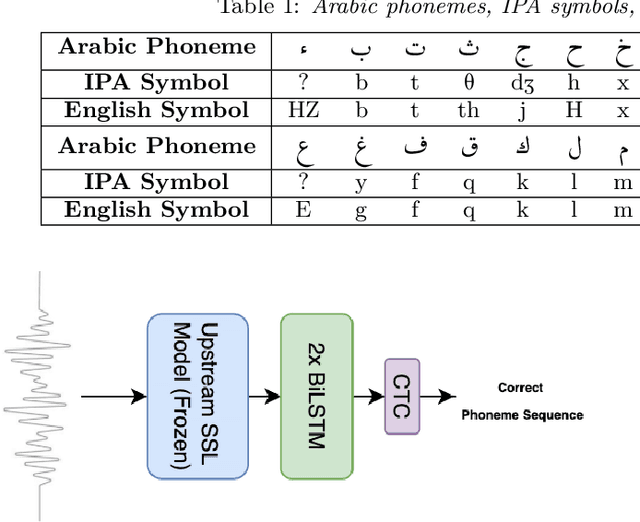

We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.
ArVoice: A Multi-Speaker Dataset for Arabic Speech Synthesis
May 26, 2025We introduce ArVoice, a multi-speaker Modern Standard Arabic (MSA) speech corpus with diacritized transcriptions, intended for multi-speaker speech synthesis, and can be useful for other tasks such as speech-based diacritic restoration, voice conversion, and deepfake detection. ArVoice comprises: (1) a new professionally recorded set from six voice talents with diverse demographics, (2) a modified subset of the Arabic Speech Corpus; and (3) high-quality synthetic speech from two commercial systems. The complete corpus consists of a total of 83.52 hours of speech across 11 voices; around 10 hours consist of human voices from 7 speakers. We train three open-source TTS and two voice conversion systems to illustrate the use cases of the dataset. The corpus is available for research use.
Voice of a Continent: Mapping Africa's Speech Technology Frontier
May 24, 2025Africa's rich linguistic diversity remains significantly underrepresented in speech technologies, creating barriers to digital inclusion. To alleviate this challenge, we systematically map the continent's speech space of datasets and technologies, leading to a new comprehensive benchmark SimbaBench for downstream African speech tasks. Using SimbaBench, we introduce the Simba family of models, achieving state-of-the-art performance across multiple African languages and speech tasks. Our benchmark analysis reveals critical patterns in resource availability, while our model evaluation demonstrates how dataset quality, domain diversity, and language family relationships influence performance across languages. Our work highlights the need for expanded speech technology resources that better reflect Africa's linguistic diversity and provides a solid foundation for future research and development efforts toward more inclusive speech technologies.
Infant Cry Detection Using Causal Temporal Representation
Mar 08, 2025This paper addresses a major challenge in acoustic event detection, in particular infant cry detection in the presence of other sounds and background noises: the lack of precise annotated data. We present two contributions for supervised and unsupervised infant cry detection. The first is an annotated dataset for cry segmentation, which enables supervised models to achieve state-of-the-art performance. Additionally, we propose a novel unsupervised method, Causal Representation Spare Transition Clustering (CRSTC), based on causal temporal representation, which helps address the issue of data scarcity more generally. By integrating the detected cry segments, we significantly improve the performance of downstream infant cry classification, highlighting the potential of this approach for infant care applications.
Where Are We? Evaluating LLM Performance on African Languages
Feb 26, 2025Africa's rich linguistic heritage remains underrepresented in NLP, largely due to historical policies that favor foreign languages and create significant data inequities. In this paper, we integrate theoretical insights on Africa's language landscape with an empirical evaluation using Sahara - a comprehensive benchmark curated from large-scale, publicly accessible datasets capturing the continent's linguistic diversity. By systematically assessing the performance of leading large language models (LLMs) on Sahara, we demonstrate how policy-induced data variations directly impact model effectiveness across African languages. Our findings reveal that while a few languages perform reasonably well, many Indigenous languages remain marginalized due to sparse data. Leveraging these insights, we offer actionable recommendations for policy reforms and inclusive data practices. Overall, our work underscores the urgent need for a dual approach - combining theoretical understanding with empirical evaluation - to foster linguistic diversity in AI for African communities.
Dialectal Coverage And Generalization in Arabic Speech Recognition
Nov 07, 2024



Developing robust automatic speech recognition (ASR) systems for Arabic, a language characterized by its rich dialectal diversity and often considered a low-resource language in speech technology, demands effective strategies to manage its complexity. This study explores three critical factors influencing ASR performance: the role of dialectal coverage in pre-training, the effectiveness of dialect-specific fine-tuning compared to a multi-dialectal approach, and the ability to generalize to unseen dialects. Through extensive experiments across different dialect combinations, our findings offer key insights towards advancing the development of ASR systems for pluricentric languages like Arabic.
STTATTS: Unified Speech-To-Text And Text-To-Speech Model
Oct 24, 2024Speech recognition and speech synthesis models are typically trained separately, each with its own set of learning objectives, training data, and model parameters, resulting in two distinct large networks. We propose a parameter-efficient approach to learning ASR and TTS jointly via a multi-task learning objective and shared parameters. Our evaluation demonstrates that the performance of our multi-task model is comparable to that of individually trained models while significantly saving computational and memory costs ($\sim$50\% reduction in the total number of parameters required for the two tasks combined). We experiment with English as a resource-rich language, and Arabic as a relatively low-resource language due to shortage of TTS data. Our models are trained with publicly available data, and both the training code and model checkpoints are openly available for further research.
Exploring the Limitations of Detecting Machine-Generated Text
Jun 16, 2024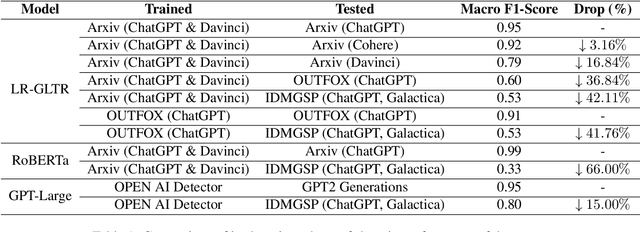



Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
ArTST: Arabic Text and Speech Transformer
Oct 25, 2023We present ArTST, a pre-trained Arabic text and speech transformer for supporting open-source speech technologies for the Arabic language. The model architecture follows the unified-modal framework, SpeechT5, that was recently released for English, and is focused on Modern Standard Arabic (MSA), with plans to extend the model for dialectal and code-switched Arabic in future editions. We pre-trained the model from scratch on MSA speech and text data, and fine-tuned it for the following tasks: Automatic Speech Recognition (ASR), Text-To-Speech synthesis (TTS), and spoken dialect identification. In our experiments comparing ArTST with SpeechT5, as well as with previously reported results in these tasks, ArTST performs on a par with or exceeding the current state-of-the-art in all three tasks. Moreover, we find that our pre-training is conducive for generalization, which is particularly evident in the low-resource TTS task. The pre-trained model as well as the fine-tuned ASR and TTS models are released for research use.