 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limitations of Detecting Machine-Generated Text
Paper and Code
Jun 16, 2024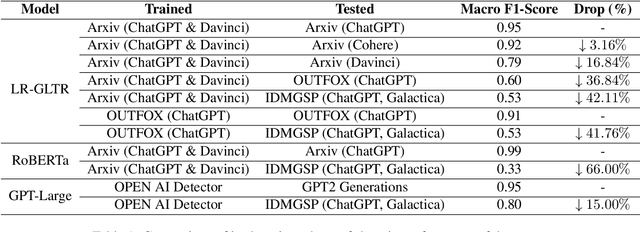



Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.