 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limitations of Detecting Machine-Generated Text
Jun 16, 2024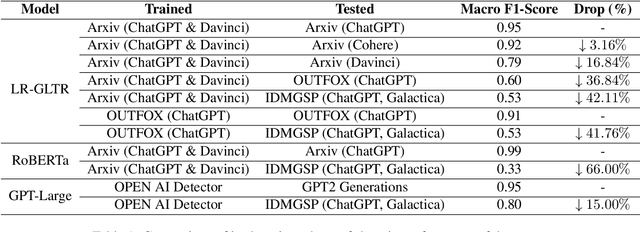



Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
Feb 20, 2024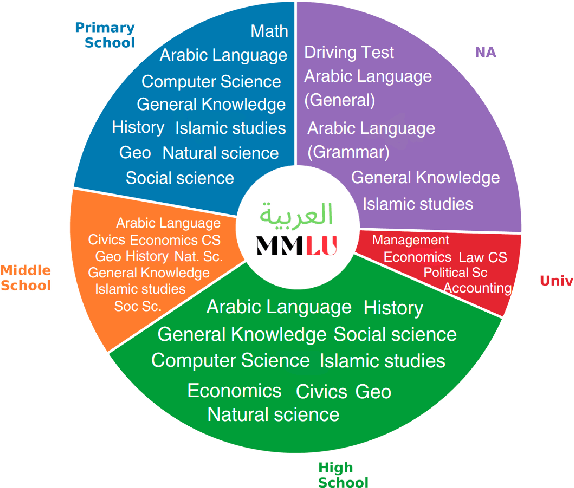



The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.
Gender Bias in Text: Labeled Datasets and Lexicons
Jan 21, 2022



Language has a profound impact on our thoughts, perceptions, and conceptions of gender roles. Gender-inclusive language is, therefore, a key tool to promote social inclusion and contribute to achieving gender equality. Consequently, detecting and mitigating gender bias in texts is instrumental in halting its propagation and societal implications. However, there is a lack of gender bias datasets and lexicons for automating the detection of gender bias using supervised and unsupervised machine learning (ML) and natural language processing (NLP) techniques. Therefore, the main contribution of this work is to publicly provide labeled datasets and exhaustive lexicons by collecting, annotating, and augmenting relevant sentences to facilitate the detection of gender bias in English text. Towards this end, we present an updated version of our previously proposed taxonomy by re-formalizing its structure, adding a new bias type, and mapping each bias subtype to an appropriate detection methodology. The released datasets and lexicons span multiple bias subtypes including: Generic He, Generic She, Explicit Marking of Sex, and Gendered Neologisms. We leveraged the use of word embedding models to further augment the collected lexicons. The underlying motivation of our work is to enable the technical community to combat gender bias in text and halt its propagation using ML and NLP techniques.
DiaLex: A Benchmark for Evaluating Multidialectal Arabic Word Embeddings
Nov 22, 2020
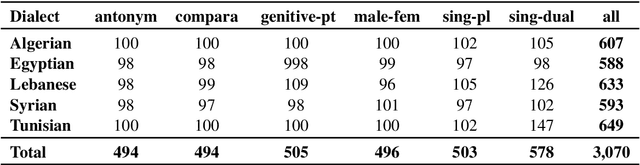
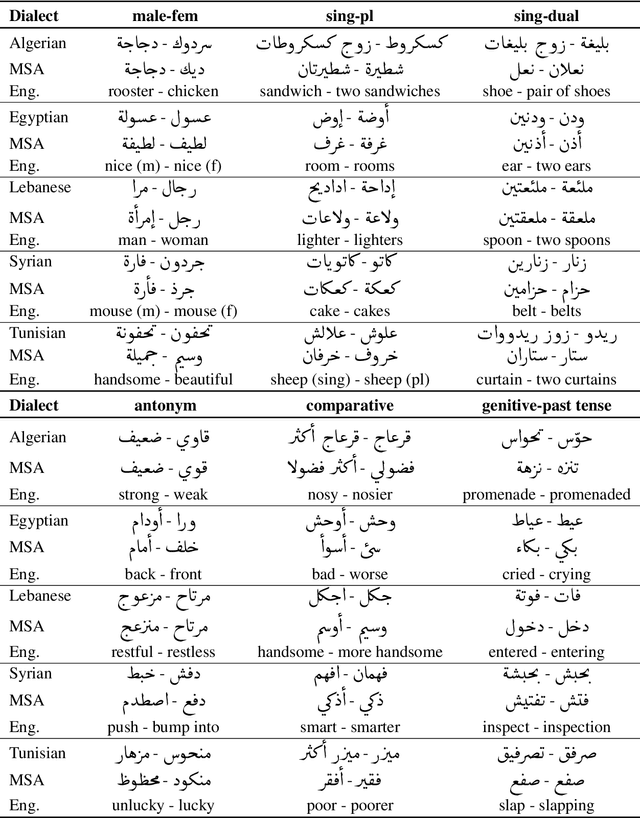
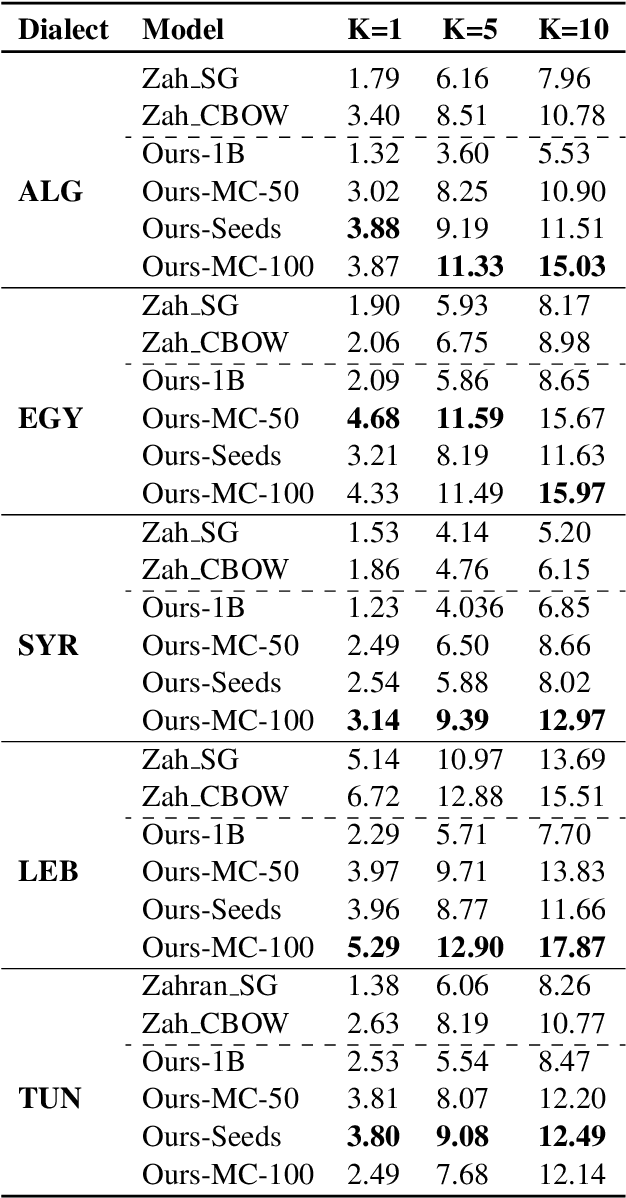
Word embeddings are a core component of modern natural language processing systems, making the ability to thoroughly evaluate them a vital task. We describe DiaLex, a benchmark for intrinsic evaluation of dialectal Arabic word embedding. DiaLex covers five important Arabic dialects: Algerian, Egyptian, Lebanese, Syrian, and Tunisian. Across these dialects, DiaLex provides a testbank for six syntactic and semantic relations, namely male to female, singular to dual, singular to plural, antonym, comparative, and genitive to past tense. DiaLex thus consists of a collection of word pairs representing each of the six relations in each of the five dialects. To demonstrate the utility of DiaLex, we use it to evaluate a set of existing and new Arabic word embeddings that we developed. Our benchmark, evaluation code, and new word embedding models will be publicly available.