 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
Feb 20, 2024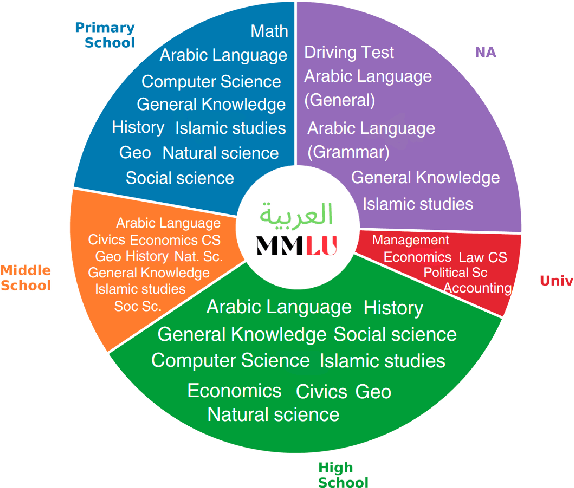



The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.