 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-model Interpretability: Self-supervised Models as a Case Study
Jul 31, 2022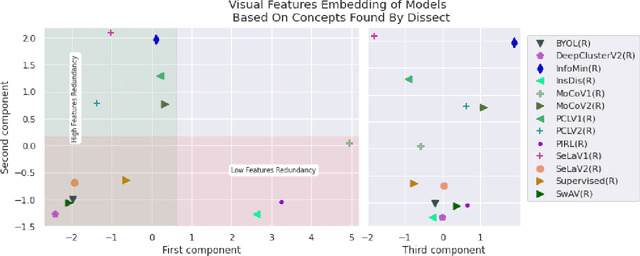
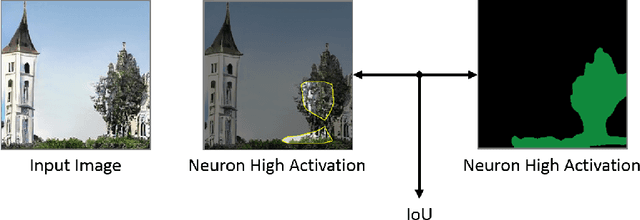

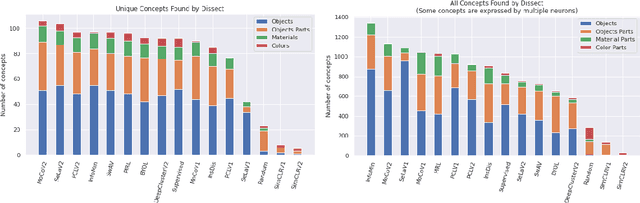
Since early machine learning models, metrics such as accuracy and precision have been the de facto way to evaluate and compare trained models. However, a single metric number doesn't fully capture the similarities and differences between models, especially in the computer vision domain. A model with high accuracy on a certain dataset might provide a lower accuracy on another dataset, without any further insights. To address this problem we build on a recent interpretability technique called Dissect to introduce \textit{inter-model interpretability}, which determines how models relate or complement each other based on the visual concepts they have learned (such as objects and materials). Towards this goal, we project 13 top-performing self-supervised models into a Learned Concepts Embedding (LCE) space that reveals proximities among models from the perspective of learned concepts. We further crossed this information with the performance of these models on four computer vision tasks and 15 datasets. The experiment allowed us to categorize the models into three categories and revealed for the first time the type of visual concepts different tasks requires. This is a step forward for designing cross-task learning algorithms.
A Deep Dive into Deep Cluster
Jul 24, 2022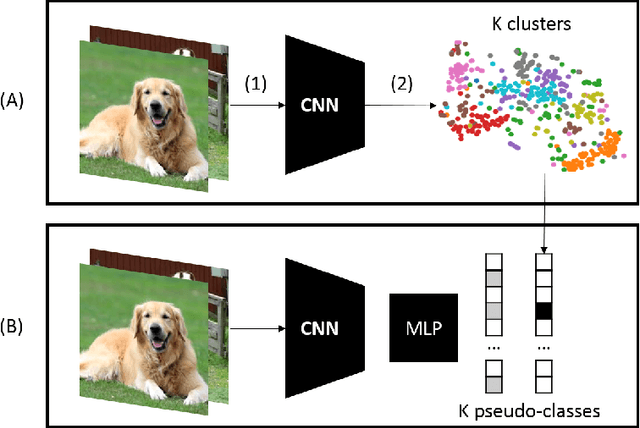

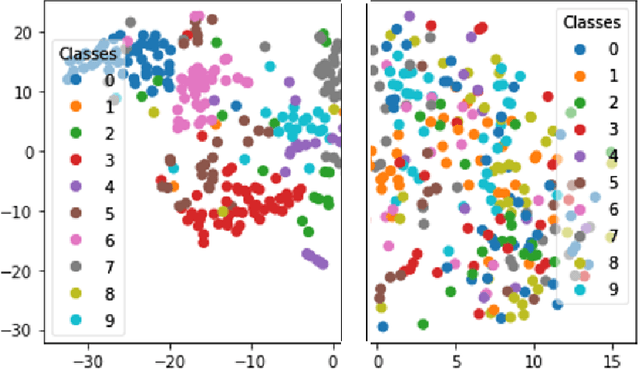
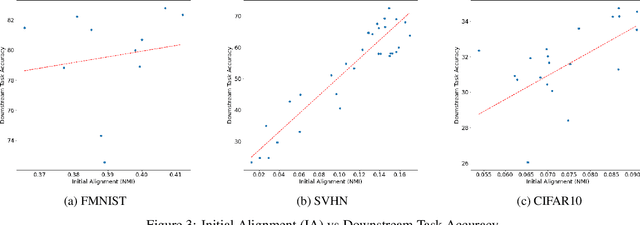
Deep Learning has demonstrated a significant improvement against traditional machine learning approaches in different domains such as image and speech recognition. Their success on benchmark datasets is transferred to the real-world through pretrained models by practitioners. Pretraining visual models using supervised learning requires a significant amount of expensive data annotation. To tackle this limitation, DeepCluster - a simple and scalable unsupervised pretraining of visual representations - has been proposed. However, the underlying work of the model is not yet well understood. In this paper, we analyze DeepCluster internals and exhaustively evaluate the impact of various hyperparameters over a wide range of values on three different datasets. Accordingly, we propose an explanation of why the algorithm works in practice. We also show that DeepCluster convergence and performance highly depend on the interplay between the quality of the randomly initialized filters of the convolutional layer and the selected number of clusters. Furthermore, we demonstrate that continuous clustering is not critical for DeepCluster convergence. Therefore, early stopping of the clustering phase will reduce the training time and allow the algorithm to scale to large datasets. Finally, we derive plausible hyperparameter selection criteria in a semi-supervised setting.
Gender Bias in Text: Labeled Datasets and Lexicons
Jan 21, 2022



Language has a profound impact on our thoughts, perceptions, and conceptions of gender roles. Gender-inclusive language is, therefore, a key tool to promote social inclusion and contribute to achieving gender equality. Consequently, detecting and mitigating gender bias in texts is instrumental in halting its propagation and societal implications. However, there is a lack of gender bias datasets and lexicons for automating the detection of gender bias using supervised and unsupervised machine learning (ML) and natural language processing (NLP) techniques. Therefore, the main contribution of this work is to publicly provide labeled datasets and exhaustive lexicons by collecting, annotating, and augmenting relevant sentences to facilitate the detection of gender bias in English text. Towards this end, we present an updated version of our previously proposed taxonomy by re-formalizing its structure, adding a new bias type, and mapping each bias subtype to an appropriate detection methodology. The released datasets and lexicons span multiple bias subtypes including: Generic He, Generic She, Explicit Marking of Sex, and Gendered Neologisms. We leveraged the use of word embedding models to further augment the collected lexicons. The underlying motivation of our work is to enable the technical community to combat gender bias in text and halt its propagation using ML and NLP techniques.