 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Dive into Deep Cluster
Jul 24, 2022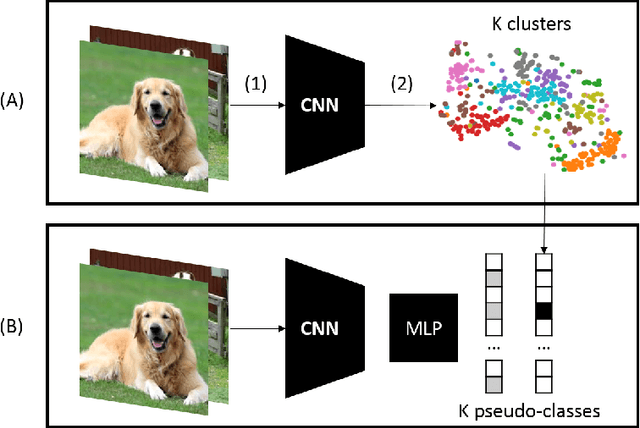

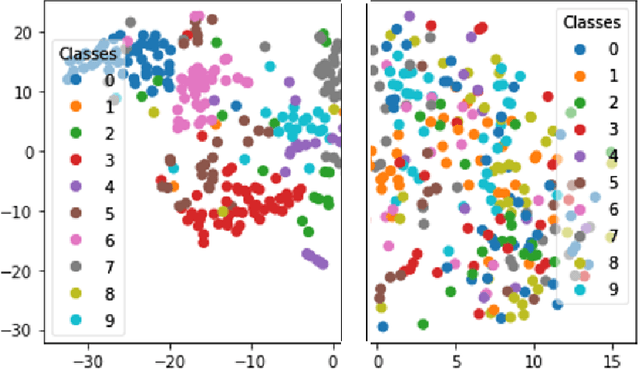
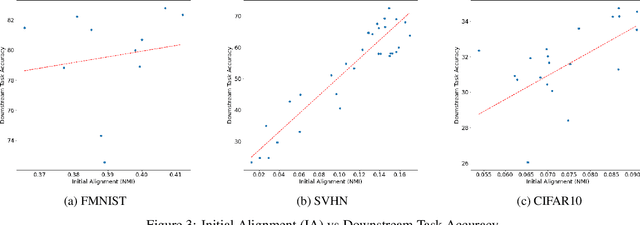
Deep Learning has demonstrated a significant improvement against traditional machine learning approaches in different domains such as image and speech recognition. Their success on benchmark datasets is transferred to the real-world through pretrained models by practitioners. Pretraining visual models using supervised learning requires a significant amount of expensive data annotation. To tackle this limitation, DeepCluster - a simple and scalable unsupervised pretraining of visual representations - has been proposed. However, the underlying work of the model is not yet well understood. In this paper, we analyze DeepCluster internals and exhaustively evaluate the impact of various hyperparameters over a wide range of values on three different datasets. Accordingly, we propose an explanation of why the algorithm works in practice. We also show that DeepCluster convergence and performance highly depend on the interplay between the quality of the randomly initialized filters of the convolutional layer and the selected number of clusters. Furthermore, we demonstrate that continuous clustering is not critical for DeepCluster convergence. Therefore, early stopping of the clustering phase will reduce the training time and allow the algorithm to scale to large datasets. Finally, we derive plausible hyperparameter selection criteria in a semi-supervised setting.