 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartComplete: A Taxonomy-based Inclusive Chart Dataset
Jan 16, 2026With advancements in deep learning (DL) and computer vision techniques, the field of chart understanding is evolving rapidly. In particular, multimodal large language models (MLLMs) are proving to be efficient and accurate in understanding charts. To accurately measure the performance of MLLMs, the research community has developed multiple datasets to serve as benchmarks. By examining these datasets, we found that they are all limited to a small set of chart types. To bridge this gap, we propose the ChartComplete dataset. The dataset is based on a chart taxonomy borrowed from the visualization community, and it covers thirty different chart types. The dataset is a collection of classified chart images and does not include a learning signal. We present the ChartComplete dataset as is to the community to build upon it.
Who Wrote This? Identifying Machine vs Human-Generated Text in Hausa
Mar 17, 2025



The advancement of large language models (LLMs) has allowed them to be proficient in various tasks, including content generation. However, their unregulated usage can lead to malicious activities such as plagiarism and generating and spreading fake news, especially for low-resource languages. Most existing machine-generated text detectors are trained on high-resource languages like English, French, etc. In this study, we developed the first large-scale detector that can distinguish between human- and machine-generated content in Hausa. We scrapped seven Hausa-language media outlets for the human-generated text and the Gemini-2.0 flash model to automatically generate the corresponding Hausa-language articles based on the human-generated article headlines. We fine-tuned four pre-trained Afri-centric models (AfriTeVa, AfriBERTa, AfroXLMR, and AfroXLMR-76L) on the resulting dataset and assessed their performance using accuracy and F1-score metrics. AfroXLMR achieved the highest performance with an accuracy of 99.23% and an F1 score of 99.21%, demonstrating its effectiveness for Hausa text detection. Our dataset is made publicly available to enable further research.
AraSTEM: A Native Arabic Multiple Choice Question Benchmark for Evaluating LLMs Knowledge In STEM Subjects
Dec 31, 2024


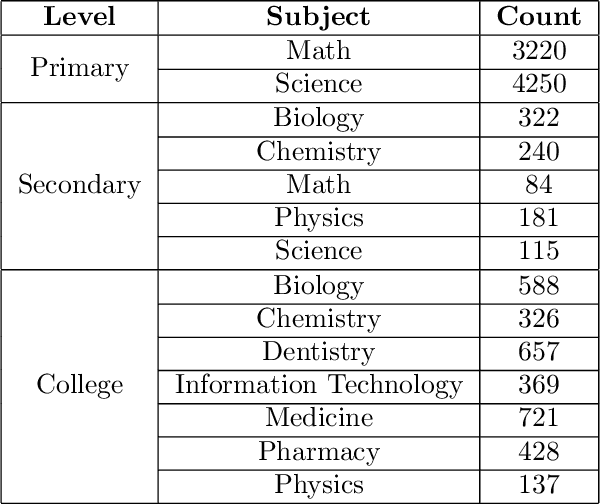
Large Language Models (LLMs) have shown remarkable capabilities, not only in generating human-like text, but also in acquiring knowledge. This highlights the need to go beyond the typical Natural Language Processing downstream benchmarks and asses the various aspects of LLMs including knowledge and reasoning. Numerous benchmarks have been developed to evaluate LLMs knowledge, but they predominantly focus on the English language. Given that many LLMs are multilingual, relying solely on benchmarking English knowledge is insufficient. To address this issue, we introduce AraSTEM, a new Arabic multiple-choice question dataset aimed at evaluating LLMs knowledge in STEM subjects. The dataset spans a range of topics at different levels which requires models to demonstrate a deep understanding of scientific Arabic in order to achieve high accuracy. Our findings show that publicly available models of varying sizes struggle with this dataset, and underscores the need for more localized language models. The dataset is freely accessible on Hugging Face.
Inter-model Interpretability: Self-supervised Models as a Case Study
Jul 31, 2022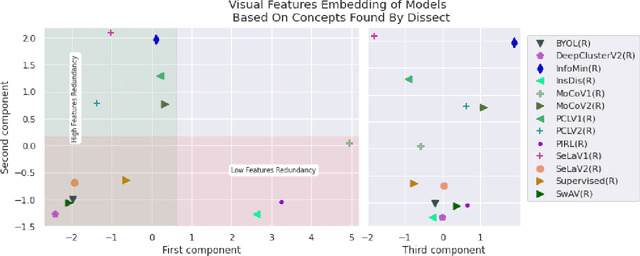
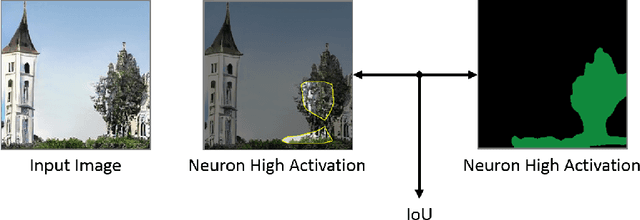

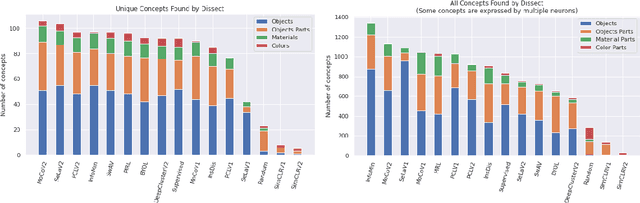
Since early machine learning models, metrics such as accuracy and precision have been the de facto way to evaluate and compare trained models. However, a single metric number doesn't fully capture the similarities and differences between models, especially in the computer vision domain. A model with high accuracy on a certain dataset might provide a lower accuracy on another dataset, without any further insights. To address this problem we build on a recent interpretability technique called Dissect to introduce \textit{inter-model interpretability}, which determines how models relate or complement each other based on the visual concepts they have learned (such as objects and materials). Towards this goal, we project 13 top-performing self-supervised models into a Learned Concepts Embedding (LCE) space that reveals proximities among models from the perspective of learned concepts. We further crossed this information with the performance of these models on four computer vision tasks and 15 datasets. The experiment allowed us to categorize the models into three categories and revealed for the first time the type of visual concepts different tasks requires. This is a step forward for designing cross-task learning algorithms.
A Deep Dive into Deep Cluster
Jul 24, 2022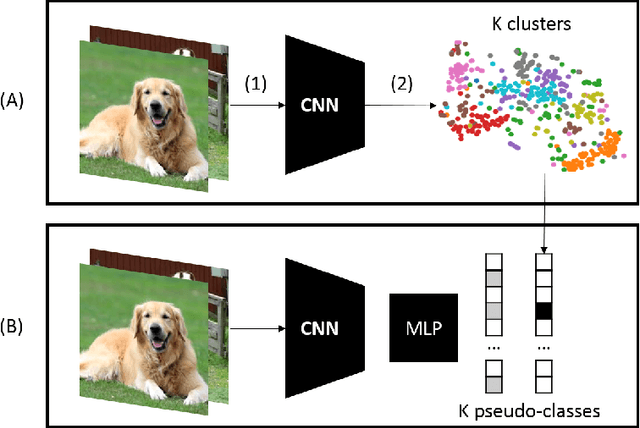

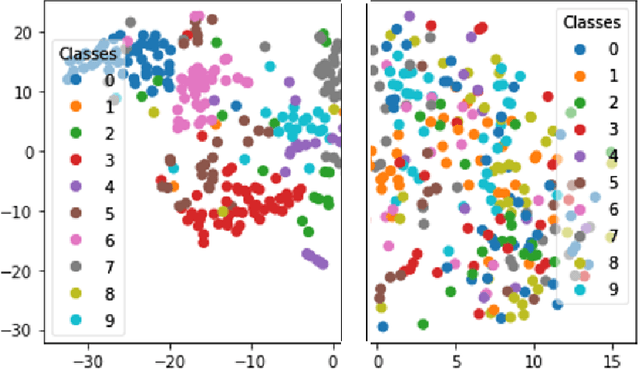
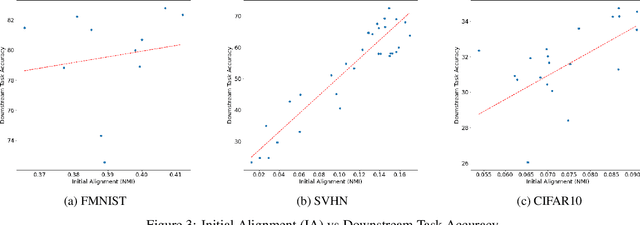
Deep Learning has demonstrated a significant improvement against traditional machine learning approaches in different domains such as image and speech recognition. Their success on benchmark datasets is transferred to the real-world through pretrained models by practitioners. Pretraining visual models using supervised learning requires a significant amount of expensive data annotation. To tackle this limitation, DeepCluster - a simple and scalable unsupervised pretraining of visual representations - has been proposed. However, the underlying work of the model is not yet well understood. In this paper, we analyze DeepCluster internals and exhaustively evaluate the impact of various hyperparameters over a wide range of values on three different datasets. Accordingly, we propose an explanation of why the algorithm works in practice. We also show that DeepCluster convergence and performance highly depend on the interplay between the quality of the randomly initialized filters of the convolutional layer and the selected number of clusters. Furthermore, we demonstrate that continuous clustering is not critical for DeepCluster convergence. Therefore, early stopping of the clustering phase will reduce the training time and allow the algorithm to scale to large datasets. Finally, we derive plausible hyperparameter selection criteria in a semi-supervised setting.