 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObscuring Data Contamination Through Translation: Evidence from Arabic Corpora
Jan 21, 2026Data contamination undermines the validity of Large Language Model evaluation by enabling models to rely on memorized benchmark content rather than true generalization. While prior work has proposed contamination detection methods, these approaches are largely limited to English benchmarks, leaving multilingual contamination poorly understood. In this work, we investigate contamination dynamics in multilingual settings by fine-tuning several open-weight LLMs on varying proportions of Arabic datasets and evaluating them on original English benchmarks. To detect memorization, we extend the Tested Slot Guessing method with a choice-reordering strategy and incorporate Min-K% probability analysis, capturing both behavioral and distributional contamination signals. Our results show that translation into Arabic suppresses conventional contamination indicators, yet models still benefit from exposure to contaminated data, particularly those with stronger Arabic capabilities. This effect is consistently reflected in rising Mink% scores and increased cross-lingual answer consistency as contamination levels grow. To address this blind spot, we propose Translation-Aware Contamination Detection, which identifies contamination by comparing signals across multiple translated benchmark variants rather than English alone. The Translation-Aware Contamination Detection reliably exposes contamination even when English-only methods fail. Together, our findings highlight the need for multilingual, translation-aware evaluation pipelines to ensure fair, transparent, and reproducible assessment of LLMs.
ChartComplete: A Taxonomy-based Inclusive Chart Dataset
Jan 16, 2026With advancements in deep learning (DL) and computer vision techniques, the field of chart understanding is evolving rapidly. In particular, multimodal large language models (MLLMs) are proving to be efficient and accurate in understanding charts. To accurately measure the performance of MLLMs, the research community has developed multiple datasets to serve as benchmarks. By examining these datasets, we found that they are all limited to a small set of chart types. To bridge this gap, we propose the ChartComplete dataset. The dataset is based on a chart taxonomy borrowed from the visualization community, and it covers thirty different chart types. The dataset is a collection of classified chart images and does not include a learning signal. We present the ChartComplete dataset as is to the community to build upon it.
A Benchmark and Agentic Framework for Omni-Modal Reasoning and Tool Use in Long Videos
Dec 18, 2025Long-form multimodal video understanding requires integrating vision, speech, and ambient audio with coherent long-range reasoning. Existing benchmarks emphasize either temporal length or multimodal richness, but rarely both and while some incorporate open-ended questions and advanced metrics, they mostly rely on single-score accuracy, obscuring failure modes. We introduce LongShOTBench, a diagnostic benchmark with open-ended, intent-driven questions; single- and multi-turn dialogues; and tasks requiring multimodal reasoning and agentic tool use across video, audio, and speech. Each item includes a reference answer and graded rubric for interpretable, and traceable evaluation. LongShOTBench is produced via a scalable, human-validated pipeline to ensure coverage and reproducibility. All samples in our LongShOTBench are human-verified and corrected. Furthermore, we present LongShOTAgent, an agentic system that analyzes long videos via preprocessing, search, and iterative refinement. On LongShOTBench, state-of-the-art MLLMs show large gaps: Gemini-2.5-Flash achieves 52.95%, open-source models remain below 30%, and LongShOTAgent attains 44.66%. These results underscore the difficulty of real-world long-form video understanding. LongShOTBench provides a practical, reproducible foundation for evaluating and improving MLLMs. All resources are available on GitHub: https://github.com/mbzuai-oryx/longshot.
Cultural Rights and the Rights to Development in the Age of AI: Implications for Global Human Rights Governance
Dec 15, 2025Cultural rights and the right to development are essential norms within the wider framework of international human rights law. However, recent technological advances in artificial intelligence (AI) and adjacent digital frontier technologies pose significant challenges to the protection and realization of these rights. This owes to the increasing influence of AI systems on the creation and depiction of cultural content, affect the use and distribution of the intellectual property of individuals and communities, and influence cultural participation and expression worldwide. In addition, the growing influence of AI thus risks exacerbating preexisting economic, social and digital divides and reinforcing inequities for marginalized communities. This dynamic challenges the existing interplay between cultural rights and the right to development, and raises questions about the integration of cultural and developmental considerations into emerging AI governance frameworks. To address these challenges, the paper examines the impact of AI on both categories of rights. Conceptually, it analyzes the epistemic and normative limitations of AI with respect to cultural and developmental assumptions embedded in algorithmic design and deployment, but also individual and structural impacts of AI on both rights. On this basis, the paper identifies gaps and tensions in existing AI governance frameworks with respect to cultural rights and the right to development. By situating cultural rights and the right to development within the broader landscape of AI and human rights, this paper contributes to the academic discourse on AI ethics, legal frameworks, and international human rights law. Finally, it outlines avenues for future research and policy development based on existing conversations in global AI governance.
AraSTEM: A Native Arabic Multiple Choice Question Benchmark for Evaluating LLMs Knowledge In STEM Subjects
Dec 31, 2024


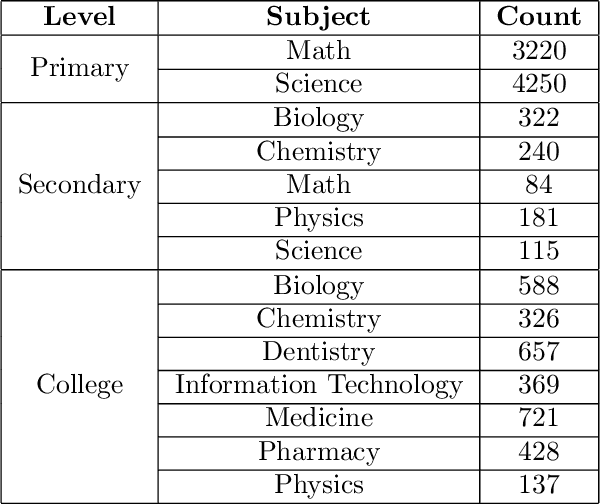
Large Language Models (LLMs) have shown remarkable capabilities, not only in generating human-like text, but also in acquiring knowledge. This highlights the need to go beyond the typical Natural Language Processing downstream benchmarks and asses the various aspects of LLMs including knowledge and reasoning. Numerous benchmarks have been developed to evaluate LLMs knowledge, but they predominantly focus on the English language. Given that many LLMs are multilingual, relying solely on benchmarking English knowledge is insufficient. To address this issue, we introduce AraSTEM, a new Arabic multiple-choice question dataset aimed at evaluating LLMs knowledge in STEM subjects. The dataset spans a range of topics at different levels which requires models to demonstrate a deep understanding of scientific Arabic in order to achieve high accuracy. Our findings show that publicly available models of varying sizes struggle with this dataset, and underscores the need for more localized language models. The dataset is freely accessible on Hugging Face.
An Unsupervised Anomaly Detection in Electricity Consumption Using Reinforcement Learning and Time Series Forest Based Framework
Dec 30, 2024Anomaly detection (AD) plays a crucial role in time series applications, primarily because time series data is employed across real-world scenarios. Detecting anomalies poses significant challenges since anomalies take diverse forms making them hard to pinpoint accurately. Previous research has explored different AD models, making specific assumptions with varying sensitivity toward particular anomaly types. To address this issue, we propose a novel model selection for unsupervised AD using a combination of time series forest (TSF) and reinforcement learning (RL) approaches that dynamically chooses an AD technique. Our approach allows for effective AD without explicitly depending on ground truth labels that are often scarce and expensive to obtain. Results from the real-time series dataset demonstrate that the proposed model selection approach outperforms all other AD models in terms of the F1 score metric. For the synthetic dataset, our proposed model surpasses all other AD models except for KNN, with an impressive F1 score of 0.989. The proposed model selection framework also exceeded the performance of GPT-4 when prompted to act as an anomaly detector on the synthetic dataset. Exploring different reward functions revealed that the original reward function in our proposed AD model selection approach yielded the best overall scores. We evaluated the performance of the six AD models on an additional three datasets, having global, local, and clustered anomalies respectively, showing that each AD model exhibited distinct performance depending on the type of anomalies. This emphasizes the significance of our proposed AD model selection framework, maintaining high performance across all datasets, and showcasing superior performance across different anomaly types.
On The Potential of The Fractal Geometry and The CNNs Ability to Encode it
Jan 07, 2024The fractal dimension provides a statistical index of object complexity by studying how the pattern changes with the measuring scale. Although useful in several classification tasks, the fractal dimension is under-explored in deep learning applications. In this work, we investigate the features that are learned by deep models and we study whether these deep networks are able to encode features as complex and high-level as the fractal dimensions. Specifically, we conduct a correlation analysis experiment to show that deep networks are not able to extract such a feature in none of their layers. We combine our analytical study with a human evaluation to investigate the differences between deep learning networks and models that operate on the fractal feature solely. Moreover, we show the effectiveness of fractal features in applications where the object structure is crucial for the classification task. We empirically show that training a shallow network on fractal features achieves performance comparable, even superior in specific cases, to that of deep networks trained on raw data while requiring less computational resources. Fractals improved the accuracy of the classification by 30% on average while requiring up to 84% less time to train. We couple our empirical study with a complexity analysis of the computational cost of extracting the proposed fractal features, and we study its limitation.
An Asymmetric Loss with Anomaly Detection LSTM Framework for Power Consumption Prediction
Feb 05, 2023
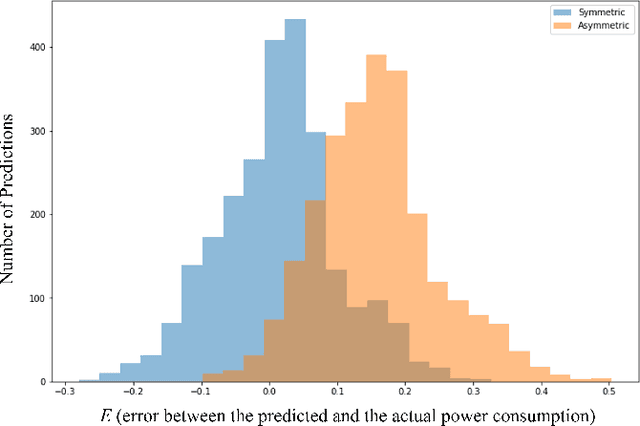


Building an accurate load forecasting model with minimal underpredictions is vital to prevent any undesired power outages due to underproduction of electricity. However, the power consumption patterns of the residential sector contain fluctuations and anomalies making them challenging to predict. In this paper, we propose multiple Long Short-Term Memory (LSTM) frameworks with different asymmetric loss functions to impose a higher penalty on underpredictions. We also apply a density-based spatial clustering of applications with noise (DBSCAN) anomaly detection approach, prior to the load forecasting task, to remove any present oultiers. Considering the effect of weather and social factors, seasonality splitting is performed on the three considered datasets from France, Germany, and Hungary containing hourly power consumption, weather, and calendar features. Root-mean-square error (RMSE) results show that removing the anomalies efficiently reduces the underestimation and overestimation errors in all the seasonal datasets. Additionally, asymmetric loss functions and seasonality splitting effectively minimize underestimations despite increasing the overestimation error to some degree. Reducing underpredictions of electricity consumption is essential to prevent power outages that can be damaging to the community.
Spatio-Temporal Graph Neural Networks: A Survey
Jan 25, 2023Graph Neural Networks have gained huge interest in the past few years. These powerful algorithms expanded deep learning models to non-Euclidean space and were able to achieve state of art performance in various applications including recommender systems and social networks. However, this performance is based on static graph structures assumption which limits the Graph Neural Networks performance when the data varies with time. Temporal Graph Neural Networks are extension of Graph Neural Networks that takes the time factor into account. Recently, various Temporal Graph Neural Network algorithms were proposed and achieved superior performance compared to other deep learning algorithms in several time dependent applications. This survey discusses interesting topics related to Spatio temporal Graph Neural Networks, including algorithms, application, and open challenges.
CEnt: An Entropy-based Model-agnostic Explainability Framework to Contrast Classifiers' Decisions
Jan 19, 2023Current interpretability methods focus on explaining a particular model's decision through present input features. Such methods do not inform the user of the sufficient conditions that alter these decisions when they are not desirable. Contrastive explanations circumvent this problem by providing explanations of the form "If the feature $X>x$, the output $Y$ would be different''. While different approaches are developed to find contrasts; these methods do not all deal with mutability and attainability constraints. In this work, we present a novel approach to locally contrast the prediction of any classifier. Our Contrastive Entropy-based explanation method, CEnt, approximates a model locally by a decision tree to compute entropy information of different feature splits. A graph, G, is then built where contrast nodes are found through a one-to-many shortest path search. Contrastive examples are generated from the shortest path to reflect feature splits that alter model decisions while maintaining lower entropy. We perform local sampling on manifold-like distances computed by variational auto-encoders to reflect data density. CEnt is the first non-gradient-based contrastive method generating diverse counterfactuals that do not necessarily exist in the training data while satisfying immutability (ex. race) and semi-immutability (ex. age can only change in an increasing direction). Empirical evaluation on four real-world numerical datasets demonstrates the ability of CEnt in generating counterfactuals that achieve better proximity rates than existing methods without compromising latency, feasibility, and attainability. We further extend CEnt to imagery data to derive visually appealing and useful contrasts between class labels on MNIST and Fashion MNIST datasets. Finally, we show how CEnt can serve as a tool to detect vulnerabilities of textual classifiers.