 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Explainability of Natural Language Processing Deep Models
Paper and Code
Oct 13, 2022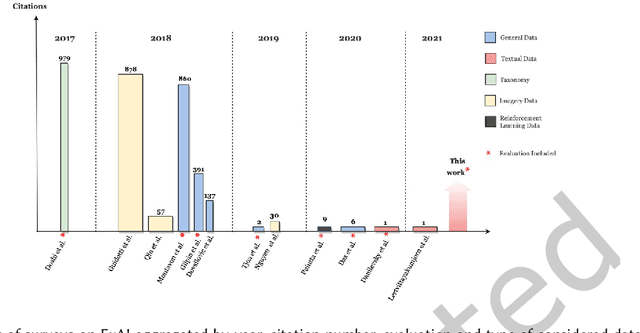
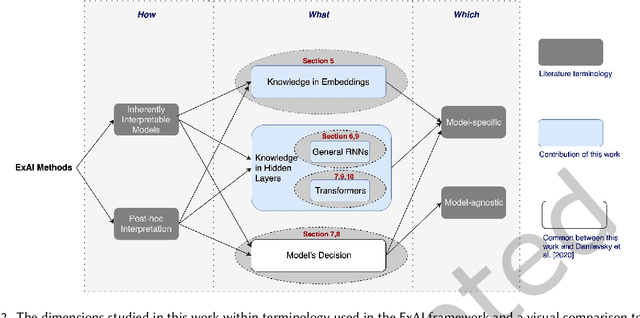


While there has been a recent explosion of work on ExplainableAI ExAI on deep models that operate on imagery and tabular data, textual datasets present new challenges to the ExAI community. Such challenges can be attributed to the lack of input structure in textual data, the use of word embeddings that add to the opacity of the models and the difficulty of the visualization of the inner workings of deep models when they are trained on textual data. Lately, methods have been developed to address the aforementioned challenges and present satisfactory explanations on Natural Language Processing (NLP) models. However, such methods are yet to be studied in a comprehensive framework where common challenges are properly stated and rigorous evaluation practices and metrics are proposed. Motivated to democratize ExAI methods in the NLP field, we present in this work a survey that studies model-agnostic as well as model-specific explainability methods on NLP models. Such methods can either develop inherently interpretable NLP models or operate on pre-trained models in a post-hoc manner. We make this distinction and we further decompose the methods into three categories according to what they explain: (1) word embeddings (input-level), (2) inner workings of NLP models (processing-level) and (3) models' decisions (output-level). We also detail the different evaluation approaches interpretability methods in the NLP field. Finally, we present a case-study on the well-known neural machine translation in an appendix and we propose promising future research directions for ExAI in the NLP field.