 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Potential of The Fractal Geometry and The CNNs Ability to Encode it
Jan 07, 2024The fractal dimension provides a statistical index of object complexity by studying how the pattern changes with the measuring scale. Although useful in several classification tasks, the fractal dimension is under-explored in deep learning applications. In this work, we investigate the features that are learned by deep models and we study whether these deep networks are able to encode features as complex and high-level as the fractal dimensions. Specifically, we conduct a correlation analysis experiment to show that deep networks are not able to extract such a feature in none of their layers. We combine our analytical study with a human evaluation to investigate the differences between deep learning networks and models that operate on the fractal feature solely. Moreover, we show the effectiveness of fractal features in applications where the object structure is crucial for the classification task. We empirically show that training a shallow network on fractal features achieves performance comparable, even superior in specific cases, to that of deep networks trained on raw data while requiring less computational resources. Fractals improved the accuracy of the classification by 30% on average while requiring up to 84% less time to train. We couple our empirical study with a complexity analysis of the computational cost of extracting the proposed fractal features, and we study its limitation.
CEnt: An Entropy-based Model-agnostic Explainability Framework to Contrast Classifiers' Decisions
Jan 19, 2023Current interpretability methods focus on explaining a particular model's decision through present input features. Such methods do not inform the user of the sufficient conditions that alter these decisions when they are not desirable. Contrastive explanations circumvent this problem by providing explanations of the form "If the feature $X>x$, the output $Y$ would be different''. While different approaches are developed to find contrasts; these methods do not all deal with mutability and attainability constraints. In this work, we present a novel approach to locally contrast the prediction of any classifier. Our Contrastive Entropy-based explanation method, CEnt, approximates a model locally by a decision tree to compute entropy information of different feature splits. A graph, G, is then built where contrast nodes are found through a one-to-many shortest path search. Contrastive examples are generated from the shortest path to reflect feature splits that alter model decisions while maintaining lower entropy. We perform local sampling on manifold-like distances computed by variational auto-encoders to reflect data density. CEnt is the first non-gradient-based contrastive method generating diverse counterfactuals that do not necessarily exist in the training data while satisfying immutability (ex. race) and semi-immutability (ex. age can only change in an increasing direction). Empirical evaluation on four real-world numerical datasets demonstrates the ability of CEnt in generating counterfactuals that achieve better proximity rates than existing methods without compromising latency, feasibility, and attainability. We further extend CEnt to imagery data to derive visually appealing and useful contrasts between class labels on MNIST and Fashion MNIST datasets. Finally, we show how CEnt can serve as a tool to detect vulnerabilities of textual classifiers.
Beyond Model Interpretability: On the Faithfulness and Adversarial Robustness of Contrastive Textual Explanations
Oct 17, 2022


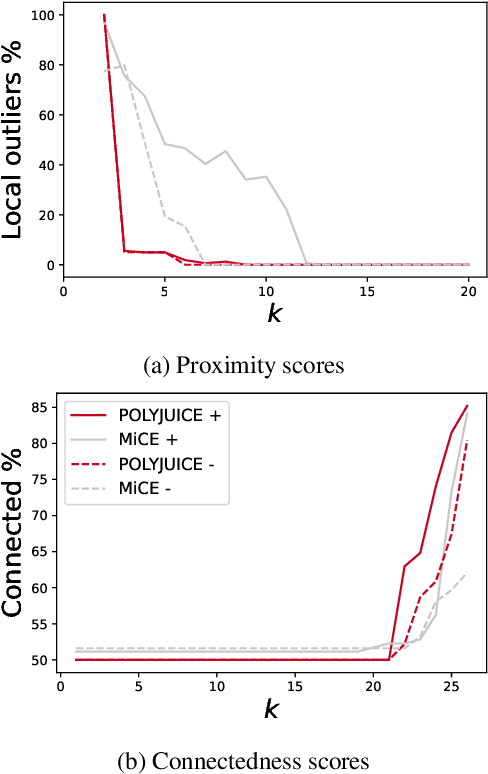
Contrastive explanation methods go beyond transparency and address the contrastive aspect of explanations. Such explanations are emerging as an attractive option to provide actionable change to scenarios adversely impacted by classifiers' decisions. However, their extension to textual data is under-explored and there is little investigation on their vulnerabilities and limitations. This work motivates textual counterfactuals by laying the ground for a novel evaluation scheme inspired by the faithfulness of explanations. Accordingly, we extend the computation of three metrics, proximity,connectedness and stability, to textual data and we benchmark two successful contrastive methods, POLYJUICE and MiCE, on our suggested metrics. Experiments on sentiment analysis data show that the connectedness of counterfactuals to their original counterparts is not obvious in both models. More interestingly, the generated contrastive texts are more attainable with POLYJUICE which highlights the significance of latent representations in counterfactual search. Finally, we perform the first semantic adversarial attack on textual recourse methods. The results demonstrate the robustness of POLYJUICE and the role that latent input representations play in robustness and reliability.
On the Explainability of Natural Language Processing Deep Models
Oct 13, 2022
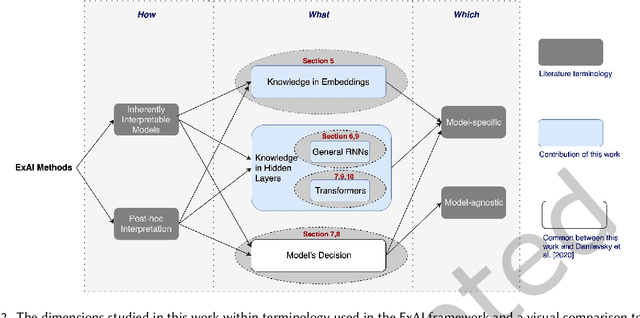


While there has been a recent explosion of work on ExplainableAI ExAI on deep models that operate on imagery and tabular data, textual datasets present new challenges to the ExAI community. Such challenges can be attributed to the lack of input structure in textual data, the use of word embeddings that add to the opacity of the models and the difficulty of the visualization of the inner workings of deep models when they are trained on textual data. Lately, methods have been developed to address the aforementioned challenges and present satisfactory explanations on Natural Language Processing (NLP) models. However, such methods are yet to be studied in a comprehensive framework where common challenges are properly stated and rigorous evaluation practices and metrics are proposed. Motivated to democratize ExAI methods in the NLP field, we present in this work a survey that studies model-agnostic as well as model-specific explainability methods on NLP models. Such methods can either develop inherently interpretable NLP models or operate on pre-trained models in a post-hoc manner. We make this distinction and we further decompose the methods into three categories according to what they explain: (1) word embeddings (input-level), (2) inner workings of NLP models (processing-level) and (3) models' decisions (output-level). We also detail the different evaluation approaches interpretability methods in the NLP field. Finally, we present a case-study on the well-known neural machine translation in an appendix and we propose promising future research directions for ExAI in the NLP field.
On the Evaluation of the Plausibility and Faithfulness of Sentiment Analysis Explanations
Oct 13, 2022Current Explainable AI (ExAI) methods, especially in the NLP field, are conducted on various datasets by employing different metrics to evaluate several aspects. The lack of a common evaluation framework is hindering the progress tracking of such methods and their wider adoption. In this work, inspired by offline information retrieval, we propose different metrics and techniques to evaluate the explainability of SA models from two angles. First, we evaluate the strength of the extracted "rationales" in faithfully explaining the predicted outcome. Second, we measure the agreement between ExAI methods and human judgment on a homegrown dataset1 to reflect on the rationales plausibility. Our conducted experiments comprise four dimensions: (1) the underlying architectures of SA models, (2) the approach followed by the ExAI method, (3) the reasoning difficulty, and (4) the homogeneity of the ground-truth rationales. We empirically demonstrate that anchors explanations are more aligned with the human judgment and can be more confident in extracting supporting rationales. As can be foreseen, the reasoning complexity of sentiment is shown to thwart ExAI methods from extracting supporting evidence. Moreover, a remarkable discrepancy is discerned between the results of different explainability methods on the various architectures suggesting the need for consolidation to observe enhanced performance. Predominantly, transformers are shown to exhibit better explainability than convolutional and recurrent architectures. Our work paves the way towards designing more interpretable NLP models and enabling a common evaluation ground for their relative strengths and robustness.
* 13 pages, 3 figures, conference (AIAI - springer)
An Optimized and Energy-Efficient Parallel Implementation of Non-Iteratively Trained Recurrent Neural Networks
Nov 26, 2019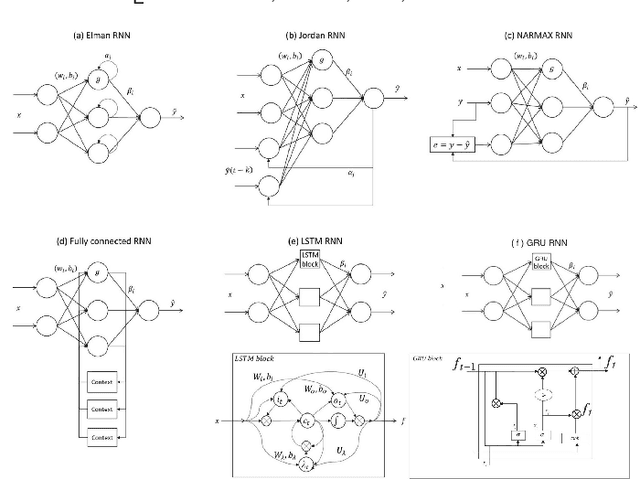

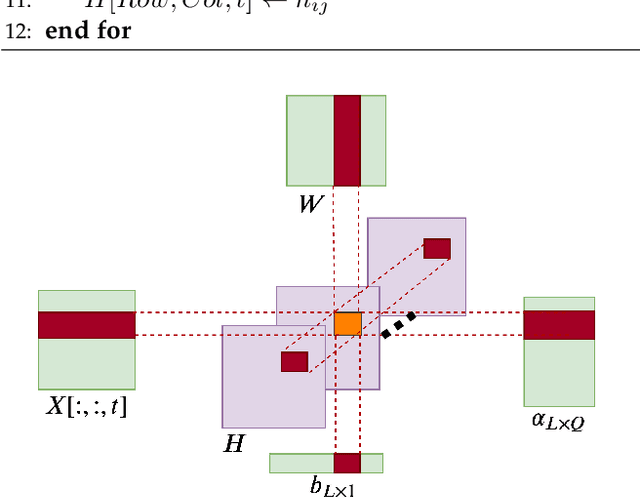

Recurrent neural networks (RNN) have been successfully applied to various sequential decision-making tasks, natural language processing applications, and time-series predictions. Such networks are usually trained through back-propagation through time (BPTT) which is prohibitively expensive, especially when the length of the time dependencies and the number of hidden neurons increase. To reduce the training time, extreme learning machines (ELMs) have been recently applied to RNN training, reaching a 99\% speedup on some applications. Due to its non-iterative nature, ELM training, when parallelized, has the potential to reach higher speedups than BPTT. In this work, we present \opt, an optimized parallel RNN training algorithm based on ELM that takes advantage of the GPU shared memory and of parallel QR factorization algorithms to efficiently reach optimal solutions. The theoretical analysis of the proposed algorithm is presented on six RNN architectures, including LSTM and GRU, and its performance is empirically tested on ten time-series prediction applications. \opt~is shown to reach up to 845 times speedup over its sequential counterpart and to require up to 20x less time to train than parallel BPTT.
Change your singer: a transfer learning generative adversarial framework for song to song conversion
Nov 07, 2019

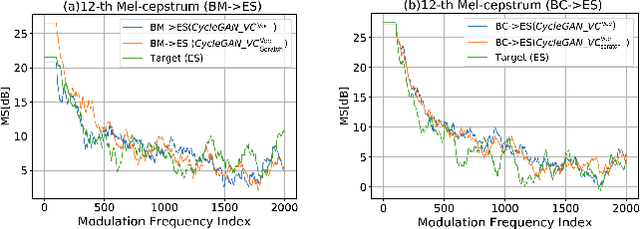

Have you ever wondered how a song might sound if performed by a different artist? In this work, we propose SCM-GAN, an end-to-end non-parallel song conversion system powered by generative adversarial and transfer learning that allows users to listen to a selected target singer singing any song. SCM-GAN first separates songs into vocals and instrumental music using a U-Net network, then converts the vocal segments to the target singer using advanced CycleGAN-VC, before merging the converted vocals with their corresponding background music. SCM-GAN is first initialized with feature representations learned from a state-of-the-art voice-to-voice conversion and then trained on a dataset of non-parallel songs. Furthermore, SCM-GAN is evaluated against a set of metrics including global variance GV and modulation spectra MS on the 24 Mel-cepstral coefficients (MCEPs). Transfer learning improves the GV by 35% and the MS by 13% on average. A subjective comparison is conducted to test the user satisfaction with the quality and the naturalness of the conversion. Results show above par similarity between SCM-GAN's output and the target (70\% on average) as well as great naturalness of the converted songs.