 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEnt: An Entropy-based Model-agnostic Explainability Framework to Contrast Classifiers' Decisions
Jan 19, 2023Current interpretability methods focus on explaining a particular model's decision through present input features. Such methods do not inform the user of the sufficient conditions that alter these decisions when they are not desirable. Contrastive explanations circumvent this problem by providing explanations of the form "If the feature $X>x$, the output $Y$ would be different''. While different approaches are developed to find contrasts; these methods do not all deal with mutability and attainability constraints. In this work, we present a novel approach to locally contrast the prediction of any classifier. Our Contrastive Entropy-based explanation method, CEnt, approximates a model locally by a decision tree to compute entropy information of different feature splits. A graph, G, is then built where contrast nodes are found through a one-to-many shortest path search. Contrastive examples are generated from the shortest path to reflect feature splits that alter model decisions while maintaining lower entropy. We perform local sampling on manifold-like distances computed by variational auto-encoders to reflect data density. CEnt is the first non-gradient-based contrastive method generating diverse counterfactuals that do not necessarily exist in the training data while satisfying immutability (ex. race) and semi-immutability (ex. age can only change in an increasing direction). Empirical evaluation on four real-world numerical datasets demonstrates the ability of CEnt in generating counterfactuals that achieve better proximity rates than existing methods without compromising latency, feasibility, and attainability. We further extend CEnt to imagery data to derive visually appealing and useful contrasts between class labels on MNIST and Fashion MNIST datasets. Finally, we show how CEnt can serve as a tool to detect vulnerabilities of textual classifiers.
An Explainable Model for EEG Seizure Detection based on Connectivity Features
Sep 26, 2020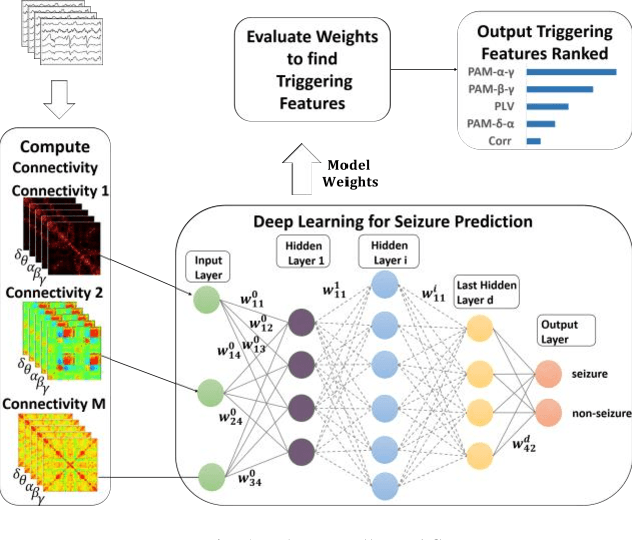

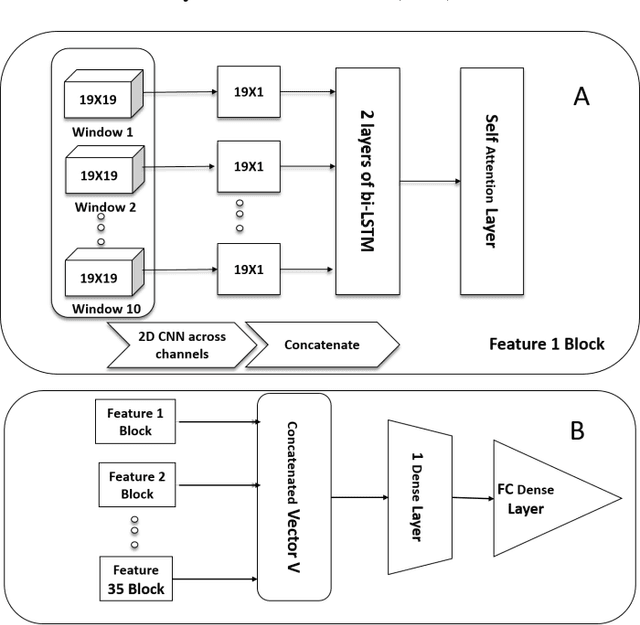
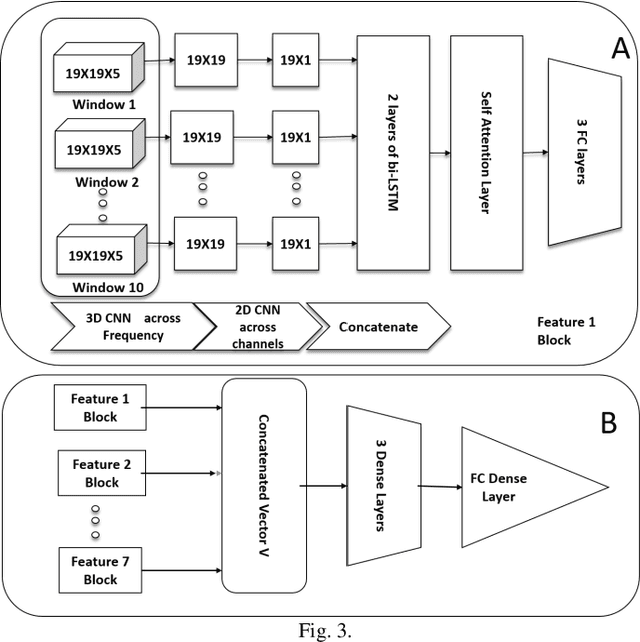
Epilepsy which is characterized by seizures is studied using EEG signals by recording the electrical activity of the brain. Different types of communication between different parts of the brain are characterized by many state of the art connectivity measures which can be directed and undirected. We propose to employ a set of undirected (spectral matrix, the inverse of the spectral matrix, coherence, partial coherence, and phaselocking value) and directed features (directed coherence, the partial directed coherence) to learn a deep neural network that detects whether a particular data window belongs to a seizure or not, which is a new approach to standard seizure classification. Taking our data as a sequence of ten sub-windows, we aim at designing an optimal deep learning model using attention, CNN, BiLstm, and fully connected layers. We also compute the relevance using the weights of the learned model based on the activation values of the receptive fields at a particular layer. Our best model architecture resulted in 97.03% accuracy using balanced MITBIH data subset. Also, we were able to explain the relevance of each feature across all patients. We were able to experimentally validate some of the scientific facts concerning seizures by studying the impact of the contributions of the activations on the decision.