 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-model Interpretability: Self-supervised Models as a Case Study
Paper and Code
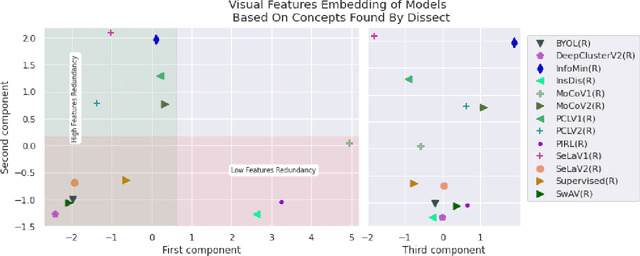
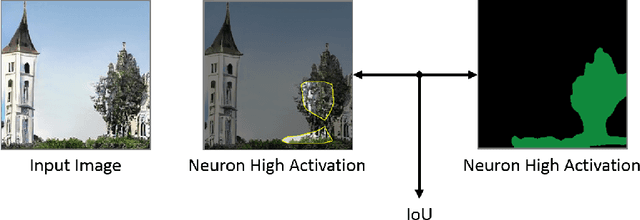

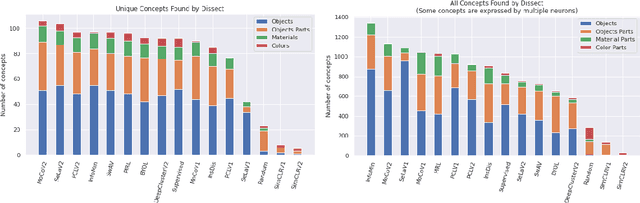
Since early machine learning models, metrics such as accuracy and precision have been the de facto way to evaluate and compare trained models. However, a single metric number doesn't fully capture the similarities and differences between models, especially in the computer vision domain. A model with high accuracy on a certain dataset might provide a lower accuracy on another dataset, without any further insights. To address this problem we build on a recent interpretability technique called Dissect to introduce \textit{inter-model interpretability}, which determines how models relate or complement each other based on the visual concepts they have learned (such as objects and materials). Towards this goal, we project 13 top-performing self-supervised models into a Learned Concepts Embedding (LCE) space that reveals proximities among models from the perspective of learned concepts. We further crossed this information with the performance of these models on four computer vision tasks and 15 datasets. The experiment allowed us to categorize the models into three categories and revealed for the first time the type of visual concepts different tasks requires. This is a step forward for designing cross-task learning algorithms.