 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Semantic Segmentation for Low-Resource Spoken Dialects
May 07, 2026Semantic segmentation is a core component of discourse analysis, yet existing models are primarily developed and evaluated on high-resource written text, limiting their effectiveness on low-resource spoken varieties. In particular, dialectal Arabic exhibits informal syntax, code-switching, and weakly marked discourse structure that challenge standard segmentation approaches. In this paper, we introduce a new multi-genre benchmark (more than 1000 samples) for semantic segmentation in conversational Arabic, focusing on dialectal discourse. The benchmark covers transcribed casual telephone conversations, code-switched podcasts, broadcast news, and expressive dialogue from novels, and was annotated and validated by native Arabic annotators. Using this benchmark, we show that segmentation models performing well on MSA news genres degrade on dialectal transcribed speech. We further propose a segmentation model that targets local semantic coherence and robustness to discourse discontinuities, consistently outperforming strong baselines on dialectal non-news genres. The benchmark and approach generalize to other low-resource spoken languages.
Unrequited Emotions: Investigating the Gaps in Motivation and Practice in Speech Emotion Recognition Research
Apr 28, 2026Critical analyses of emotion recognition technology have raised ethical concerns around task validity and potential downstream impacts, urging researchers to ensure alignment between their stated motivations and practice. However, these discussions have not adequately influenced or drawn from research on speech emotion recognition (SER). We address this gap by conducting a systematic survey of SER research to uncover what stated motivations drive this work and if they align with the datasets and emotions studied. We find that while SER research identifies appealing goals, such as well-situated voice-activated systems or healthcare applications, commonly-used datasets do not reflect these proposed deployment contexts, thus presenting a gap between motivations and research practices. We argue that such gaps engender ethical concerns, and that SER research should reassert itself with concrete use-cases to prevent misinterpretations, misuse, and downstream harms.
Aligning Stuttered-Speech Research with End-User Needs: Scoping Review, Survey, and Guidelines
Apr 22, 2026Atypical speech is receiving greater attention in speech technology research, but much of this work unfolds with limited interdisciplinary dialogue. For stuttered speech in particular, it is widely recognised that current speech recognition systems fall short in practice, and current evaluation methods and research priorities are not systematically grounded in end-user experiences and needs. In this work, we analyse these gaps through 1) a scoping review of papers that deal with stuttered speech and 2) a survey of 70 stakeholders, including adults who stutter and speech-language pathologists. By analysing these two perspectives, we propose a taxonomy of stuttered-speech research, identify where current research directions diverge from the needs articulated by stakeholders, and conclude by outlining concrete guidelines and directions towards addressing the real needs of the stuttering community.
Morphemes Without Borders: Evaluating Root-Pattern Morphology in Arabic Tokenizers and LLMs
Mar 16, 2026This work investigates how effectively large language models (LLMs) and their tokenization schemes represent and generate Arabic root-pattern morphology, probing whether they capture genuine morphological structure or rely on surface memorization. Arabic morphological system provides a rich testbed for analyzing how LLMs handle complex, non-concatenative forms and how tokenization choices influence this process. Our study begins with an evaluation of morphological fidelity across Arabic and multilingual tokenizers against gold-standard segmentation, followed by an analysis of LLM performance in productive root-pattern generation using a newly developed test set. Our findings across seven Arabic-centric and multilingual LLMs and their respective tokenizers reveal that tokenizer morphological alignment is not necessary nor sufficient for morphological generation, which questions the role of morphological tokenization in downstream performance.
Code-Switching in End-to-End Automatic Speech Recognition: A Systematic Literature Review
Jul 10, 2025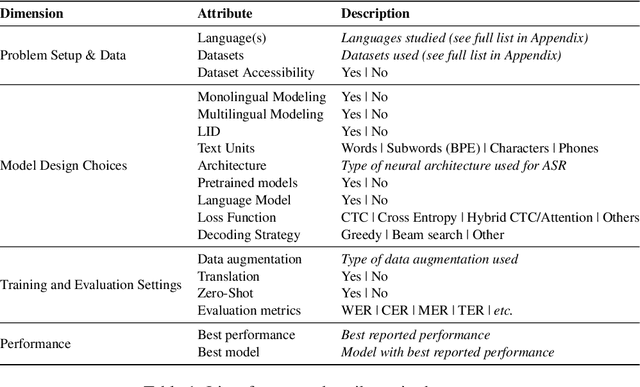
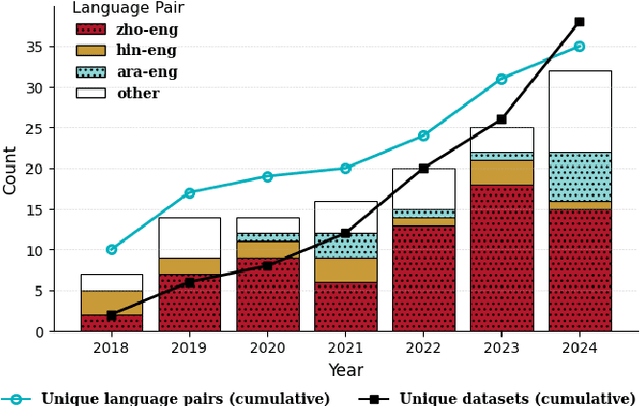
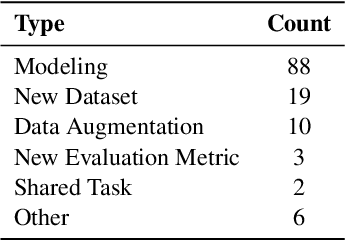
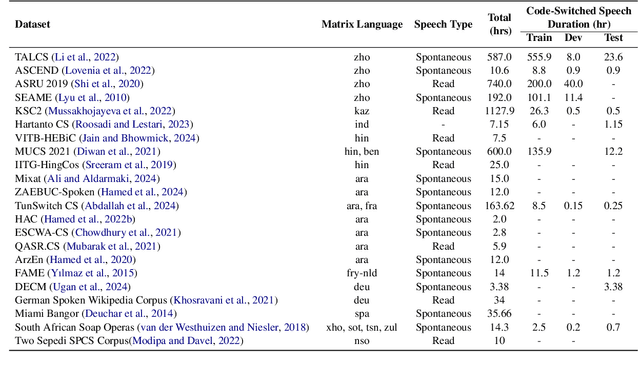
Motivated by a growing research interest into automatic speech recognition (ASR), and the growing body of work for languages in which code-switching (CS) often occurs, we present a systematic literature review of code-switching in end-to-end ASR models. We collect and manually annotate papers published in peer reviewed venues. We document the languages considered, datasets, metrics, model choices, and performance, and present a discussion of challenges in end-to-end ASR for code-switching. Our analysis thus provides insights on current research efforts and available resources as well as opportunities and gaps to guide future research.
Are LLMs Good Text Diacritizers? An Arabic and Yorùbá Case Study
Jun 13, 2025We investigate the effectiveness of large language models (LLMs) for text diacritization in two typologically distinct languages: Arabic and Yoruba. To enable a rigorous evaluation, we introduce a novel multilingual dataset MultiDiac, with diverse samples that capture a range of diacritic ambiguities. We evaluate 14 LLMs varying in size, accessibility, and language coverage, and benchmark them against 6 specialized diacritization models. Additionally, we fine-tune four small open-source models using LoRA for Yoruba. Our results show that many off-the-shelf LLMs outperform specialized diacritization models for both Arabic and Yoruba, but smaller models suffer from hallucinations. Fine-tuning on a small dataset can help improve diacritization performance and reduce hallucination rates.
ArVoice: A Multi-Speaker Dataset for Arabic Speech Synthesis
May 26, 2025We introduce ArVoice, a multi-speaker Modern Standard Arabic (MSA) speech corpus with diacritized transcriptions, intended for multi-speaker speech synthesis, and can be useful for other tasks such as speech-based diacritic restoration, voice conversion, and deepfake detection. ArVoice comprises: (1) a new professionally recorded set from six voice talents with diverse demographics, (2) a modified subset of the Arabic Speech Corpus; and (3) high-quality synthetic speech from two commercial systems. The complete corpus consists of a total of 83.52 hours of speech across 11 voices; around 10 hours consist of human voices from 7 speakers. We train three open-source TTS and two voice conversion systems to illustrate the use cases of the dataset. The corpus is available for research use.
Voice of a Continent: Mapping Africa's Speech Technology Frontier
May 24, 2025Africa's rich linguistic diversity remains significantly underrepresented in speech technologies, creating barriers to digital inclusion. To alleviate this challenge, we systematically map the continent's speech space of datasets and technologies, leading to a new comprehensive benchmark SimbaBench for downstream African speech tasks. Using SimbaBench, we introduce the Simba family of models, achieving state-of-the-art performance across multiple African languages and speech tasks. Our benchmark analysis reveals critical patterns in resource availability, while our model evaluation demonstrates how dataset quality, domain diversity, and language family relationships influence performance across languages. Our work highlights the need for expanded speech technology resources that better reflect Africa's linguistic diversity and provides a solid foundation for future research and development efforts toward more inclusive speech technologies.
JEEM: Vision-Language Understanding in Four Arabic Dialects
Mar 27, 2025We introduce JEEM, a benchmark designed to evaluate Vision-Language Models (VLMs) on visual understanding across four Arabic-speaking countries: Jordan, The Emirates, Egypt, and Morocco. JEEM includes the tasks of image captioning and visual question answering, and features culturally rich and regionally diverse content. This dataset aims to assess the ability of VLMs to generalize across dialects and accurately interpret cultural elements in visual contexts. In an evaluation of five prominent open-source Arabic VLMs and GPT-4V, we find that the Arabic VLMs consistently underperform, struggling with both visual understanding and dialect-specific generation. While GPT-4V ranks best in this comparison, the model's linguistic competence varies across dialects, and its visual understanding capabilities lag behind. This underscores the need for more inclusive models and the value of culturally-diverse evaluation paradigms.
Infant Cry Detection Using Causal Temporal Representation
Mar 08, 2025This paper addresses a major challenge in acoustic event detection, in particular infant cry detection in the presence of other sounds and background noises: the lack of precise annotated data. We present two contributions for supervised and unsupervised infant cry detection. The first is an annotated dataset for cry segmentation, which enables supervised models to achieve state-of-the-art performance. Additionally, we propose a novel unsupervised method, Causal Representation Spare Transition Clustering (CRSTC), based on causal temporal representation, which helps address the issue of data scarcity more generally. By integrating the detected cry segments, we significantly improve the performance of downstream infant cry classification, highlighting the potential of this approach for infant care applications.