 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveying Professional Writers on AI: Limitations, Expectations, and Fears
Apr 07, 2025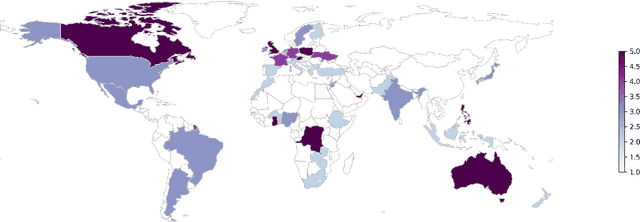
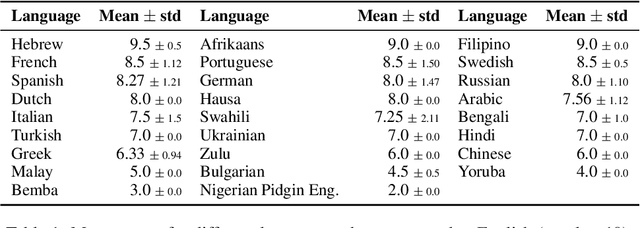
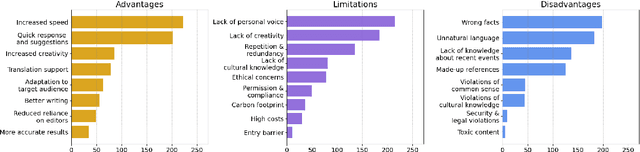
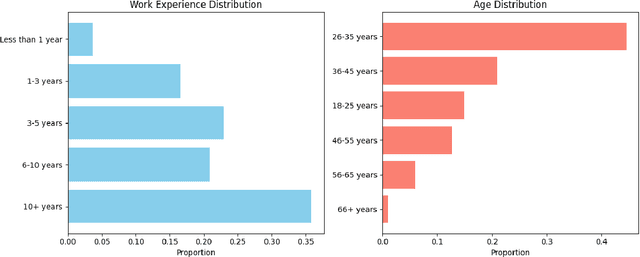
The rapid development of AI-driven tools, particularly large language models (LLMs), is reshaping professional writing. Still, key aspects of their adoption such as languages support, ethics, and long-term impact on writers voice and creativity remain underexplored. In this work, we conducted a questionnaire (N = 301) and an interactive survey (N = 36) targeting professional writers regularly using AI. We examined LLM-assisted writing practices across 25+ languages, ethical concerns, and user expectations. The findings of the survey demonstrate important insights, reflecting upon the importance of: LLMs adoption for non-English speakers; the degree of misinformation, domain and style adaptation; usability and key features of LLMs. These insights can guide further development, benefiting both writers and a broader user base.
JEEM: Vision-Language Understanding in Four Arabic Dialects
Mar 27, 2025We introduce JEEM, a benchmark designed to evaluate Vision-Language Models (VLMs) on visual understanding across four Arabic-speaking countries: Jordan, The Emirates, Egypt, and Morocco. JEEM includes the tasks of image captioning and visual question answering, and features culturally rich and regionally diverse content. This dataset aims to assess the ability of VLMs to generalize across dialects and accurately interpret cultural elements in visual contexts. In an evaluation of five prominent open-source Arabic VLMs and GPT-4V, we find that the Arabic VLMs consistently underperform, struggling with both visual understanding and dialect-specific generation. While GPT-4V ranks best in this comparison, the model's linguistic competence varies across dialects, and its visual understanding capabilities lag behind. This underscores the need for more inclusive models and the value of culturally-diverse evaluation paradigms.
Hands-On Tutorial: Labeling with LLM and Human-in-the-Loop
Nov 07, 2024Training and deploying machine learning models relies on a large amount of human-annotated data. As human labeling becomes increasingly expensive and time-consuming, recent research has developed multiple strategies to speed up annotation and reduce costs and human workload: generating synthetic training data, active learning, and hybrid labeling. This tutorial is oriented toward practical applications: we will present the basics of each strategy, highlight their benefits and limitations, and discuss in detail real-life case studies. Additionally, we will walk through best practices for managing human annotators and controlling the quality of the final dataset. The tutorial includes a hands-on workshop, where attendees will be guided in implementing a hybrid annotation setup. This tutorial is designed for NLP practitioners from both research and industry backgrounds who are involved in or interested in optimizing data labeling projects.
LLMs Simulate Big Five Personality Traits: Further Evidence
Jan 31, 2024An empirical investigation into the simulation of the Big Five personality traits by large language models (LLMs), namely Llama2, GPT4, and Mixtral, is presented. We analyze the personality traits simulated by these models and their stability. This contributes to the broader understanding of the capabilities of LLMs to simulate personality traits and the respective implications for personalized human-computer interaction.
Formatting the Landscape: Spatial conditional GAN for varying population in satellite imagery
Dec 08, 2020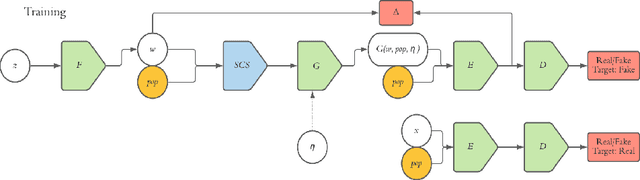
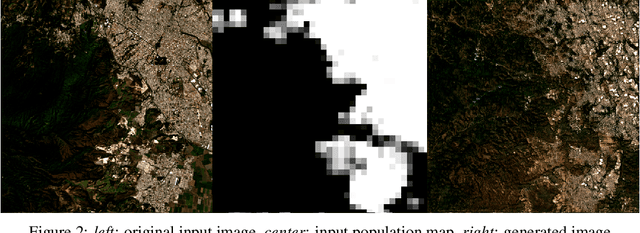

Climate change is expected to reshuffle the settlement landscape: forcing people in affected areas to migrate, to change their lifeways, and continuing to affect demographic change throughout the world. Changes to the geographic distribution of population will have dramatic impacts on land use and land cover and thus constitute one of the major challenges of planning for climate change scenarios. In this paper, we explore a generative model framework for generating satellite imagery conditional on gridded population distributions. We make additions to the existing ALAE architecture, creating a spatially conditional version: SCALAE. This method allows us to explicitly disentangle population from the model's latent space and thus input custom population forecasts into the generated imagery. We postulate that such imagery could then be directly used for land cover and land use change estimation using existing frameworks, as well as for realistic visualisation of expected local change. We evaluate the model by comparing pixel and semantic reconstructions, as well as calculate the standard FID metric. The results suggest the model captures population distributions accurately and delivers a controllable method to generate realistic satellite imagery.