 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTendem: A Hybrid AI+Human Platform
Feb 01, 2026Tendem is a hybrid system where AI handles structured, repeatable work and Human Experts step in when the models fail or to verify results. Each result undergoes a comprehensive quality review before delivery to the Client. To assess Tendem's performance, we conducted a series of in-house evaluations on 94 real-world tasks, comparing it with AI-only agents and human-only workflows carried out by Upwork freelancers. The results show that Tendem consistently delivers higher-quality outputs with faster turnaround times. At the same time, its operational costs remain comparable to human-only execution. On third-party agentic benchmarks, Tendem's AI Agent (operating autonomously, without human involvement) performs near state-of-the-art on web browsing and tool-use tasks while demonstrating strong results in frontier domain knowledge and reasoning.
JEEM: Vision-Language Understanding in Four Arabic Dialects
Mar 27, 2025We introduce JEEM, a benchmark designed to evaluate Vision-Language Models (VLMs) on visual understanding across four Arabic-speaking countries: Jordan, The Emirates, Egypt, and Morocco. JEEM includes the tasks of image captioning and visual question answering, and features culturally rich and regionally diverse content. This dataset aims to assess the ability of VLMs to generalize across dialects and accurately interpret cultural elements in visual contexts. In an evaluation of five prominent open-source Arabic VLMs and GPT-4V, we find that the Arabic VLMs consistently underperform, struggling with both visual understanding and dialect-specific generation. While GPT-4V ranks best in this comparison, the model's linguistic competence varies across dialects, and its visual understanding capabilities lag behind. This underscores the need for more inclusive models and the value of culturally-diverse evaluation paradigms.
U-MATH: A University-Level Benchmark for Evaluating Mathematical Skills in LLMs
Dec 04, 2024
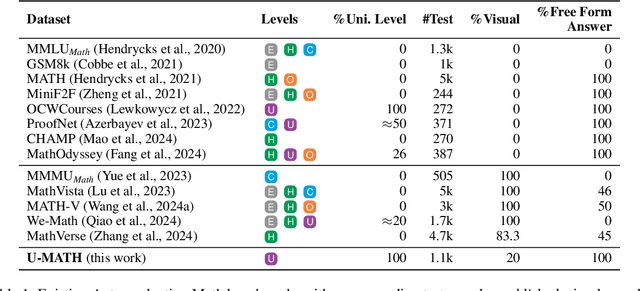
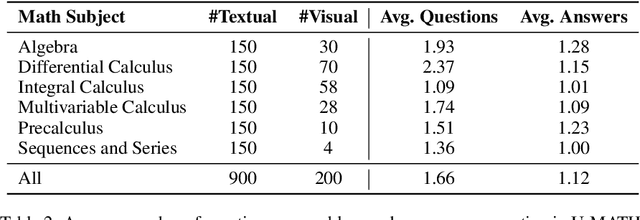
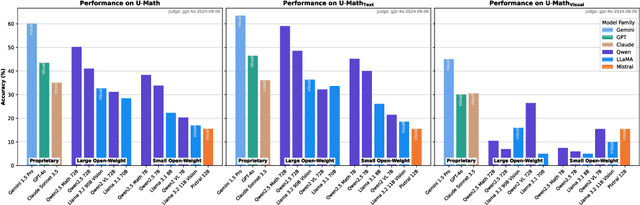
The current evaluation of mathematical skills in LLMs is limited, as existing benchmarks are either relatively small, primarily focus on elementary and high-school problems, or lack diversity in topics. Additionally, the inclusion of visual elements in tasks remains largely under-explored. To address these gaps, we introduce U-MATH, a novel benchmark of 1,100 unpublished open-ended university-level problems sourced from teaching materials. It is balanced across six core subjects, with 20% of multimodal problems. Given the open-ended nature of U-MATH problems, we employ an LLM to judge the correctness of generated solutions. To this end, we release $\mu$-MATH, a dataset to evaluate the LLMs' capabilities in judging solutions. The evaluation of general domain, math-specific, and multimodal LLMs highlights the challenges presented by U-MATH. Our findings reveal that LLMs achieve a maximum accuracy of only 63% on text-based tasks, with even lower 45% on visual problems. The solution assessment proves challenging for LLMs, with the best LLM judge having an F1-score of 80% on $\mu$-MATH.
Hands-On Tutorial: Labeling with LLM and Human-in-the-Loop
Nov 07, 2024Training and deploying machine learning models relies on a large amount of human-annotated data. As human labeling becomes increasingly expensive and time-consuming, recent research has developed multiple strategies to speed up annotation and reduce costs and human workload: generating synthetic training data, active learning, and hybrid labeling. This tutorial is oriented toward practical applications: we will present the basics of each strategy, highlight their benefits and limitations, and discuss in detail real-life case studies. Additionally, we will walk through best practices for managing human annotators and controlling the quality of the final dataset. The tutorial includes a hands-on workshop, where attendees will be guided in implementing a hybrid annotation setup. This tutorial is designed for NLP practitioners from both research and industry backgrounds who are involved in or interested in optimizing data labeling projects.
Beemo: Benchmark of Expert-edited Machine-generated Outputs
Nov 06, 2024The rapid proliferation of large language models (LLMs) has increased the volume of machine-generated texts (MGTs) and blurred text authorship in various domains. However, most existing MGT benchmarks include single-author texts (human-written and machine-generated). This conventional design fails to capture more practical multi-author scenarios, where the user refines the LLM response for natural flow, coherence, and factual correctness. Our paper introduces the Benchmark of Expert-edited Machine-generated Outputs (Beemo), which includes 6.5k texts written by humans, generated by ten instruction-finetuned LLMs, and edited by experts for various use cases, ranging from creative writing to summarization. Beemo additionally comprises 13.1k machine-generated and LLM-edited texts, allowing for diverse MGT detection evaluation across various edit types. We document Beemo's creation protocol and present the results of benchmarking 33 configurations of MGT detectors in different experimental setups. We find that expert-based editing evades MGT detection, while LLM-edited texts are unlikely to be recognized as human-written. Beemo and all materials are publicly available.