 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEEM: Vision-Language Understanding in Four Arabic Dialects
Mar 27, 2025We introduce JEEM, a benchmark designed to evaluate Vision-Language Models (VLMs) on visual understanding across four Arabic-speaking countries: Jordan, The Emirates, Egypt, and Morocco. JEEM includes the tasks of image captioning and visual question answering, and features culturally rich and regionally diverse content. This dataset aims to assess the ability of VLMs to generalize across dialects and accurately interpret cultural elements in visual contexts. In an evaluation of five prominent open-source Arabic VLMs and GPT-4V, we find that the Arabic VLMs consistently underperform, struggling with both visual understanding and dialect-specific generation. While GPT-4V ranks best in this comparison, the model's linguistic competence varies across dialects, and its visual understanding capabilities lag behind. This underscores the need for more inclusive models and the value of culturally-diverse evaluation paradigms.
On the Robust Approximation of ASR Metrics
Feb 18, 2025



Recent advances in speech foundation models are largely driven by scaling both model size and data, enabling them to perform a wide range of tasks, including speech recognition. Traditionally, ASR models are evaluated using metrics like Word Error Rate (WER) and Character Error Rate (CER), which depend on ground truth labels. As a result of limited labeled data from diverse domains and testing conditions, the true generalization capabilities of these models beyond standard benchmarks remain unclear. Moreover, labeling data is both costly and time-consuming. To address this, we propose a novel label-free approach for approximating ASR performance metrics, eliminating the need for ground truth labels. Our method utilizes multimodal embeddings in a unified space for speech and transcription representations, combined with a high-quality proxy model to compute proxy metrics. These features are used to train a regression model to predict key ASR metrics like Word Error Rate (WER) and Character Error Rate (CER). We experiment with over 40 models across 14 datasets representing both standard and in-the-wild testing conditions. Our results show that we approximate the metrics within a single-digit absolute difference across all experimental configurations, outperforming the most recent baseline by more than 50\%.
Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models
Feb 18, 2025

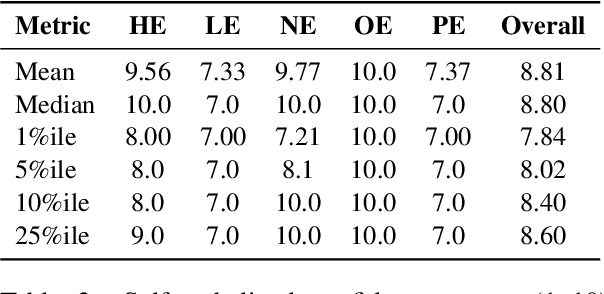
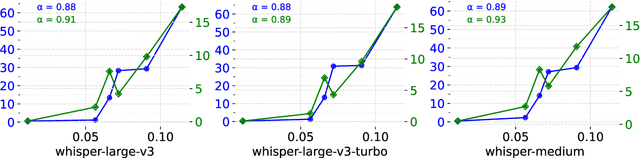
Speech foundation models trained at a massive scale, both in terms of model and data size, result in robust systems capable of performing multiple speech tasks, including automatic speech recognition (ASR). These models transcend language and domain barriers, yet effectively measuring their performance remains a challenge. Traditional metrics like word error rate (WER) and character error rate (CER) are commonly used to evaluate ASR performance but often fail to reflect transcription quality in critical contexts, particularly when detecting fabricated outputs. This phenomenon, known as hallucination, is especially concerning in high-stakes domains such as healthcare, legal, and aviation, where errors can have severe consequences. In our work, we address this gap by investigating hallucination in ASR models. We examine how factors such as distribution shifts, model size, and model architecture influence the hallucination error rate (HER), a metric we introduce to quantify hallucinations. Our analysis of 20 ASR models reveals \numinsights~key insights: (1) High WERs can mask low hallucination rates, while low WERs may conceal dangerous hallucinations. (2) Synthetic noise, both adversarial and common perturbations like white noise, pitch shift, and time stretching, increase HER. (3) Distribution shift correlates strongly with HER ($\alpha = 0.91$). Our findings highlight the importance of incorporating HER alongside traditional metrics like WER to better assess ASR model performance, particularly in high-stakes domains.
What Do Speech Foundation Models Not Learn About Speech?
Oct 16, 2024



Understanding how speech foundation models capture non-verbal cues is crucial for improving their interpretability and adaptability across diverse tasks. In our work, we analyze several prominent models such as Whisper, Seamless, Wav2Vec, HuBERT, and Qwen2-Audio focusing on their learned representations in both paralinguistic and non-paralinguistic tasks from the Dynamic-SUPERB benchmark. Our study addresses three key questions: (1) What non-verbal cues (e.g., speaker intent, emotion, environmental context) are captured? (2) How are these cues represented across different layers of the models? and (3) To what extent can these representations be effectively adapted to downstream tasks? To answer these questions, we first evaluate the models in a zero-shot setting, followed by fine-tuning on layer-wise features extracted from these models. Our results provide insights into the models' capacity for generalization, the characteristics of their layer-wise representations, and the degree of transformation required for downstream task adaptation. Our findings suggest that some of these models perform well on various tasks in zero-shot settings, despite not being explicitly trained for those tasks. We also observe that zero-shot performance correlates with better-learned representations. The analysis of layer-wise features demonstrates that some models exhibit a convex relationship between the separability of the learned representations and model depth, with different layers capturing task-specific features.