 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More Tokens: Efficient Math Reasoning via Difficulty-Aware Chain-of-Thought Distillation
Sep 05, 2025



Chain-of-thought reasoning, while powerful, can produce unnecessarily verbose output for simpler problems. We present a framework for difficulty-aware reasoning that teaches models to dynamically adjust reasoning depth based on problem complexity. Remarkably, we show that models can be endowed with such dynamic inference pathways without any architectural modifications; we simply post-train on data that is carefully curated to include chain-of-thought traces that are proportional in length to problem difficulty. Our analysis reveals that post-training via supervised fine-tuning (SFT) primarily captures patterns like reasoning length and format, while direct preference optimization (DPO) preserves reasoning accuracy, with their combination reducing length and maintaining or improving performance. Both quantitative metrics and qualitative assessments confirm that models can learn to "think proportionally", reasoning minimally on simple problems while maintaining depth for complex ones.
On the Robust Approximation of ASR Metrics
Feb 18, 2025



Recent advances in speech foundation models are largely driven by scaling both model size and data, enabling them to perform a wide range of tasks, including speech recognition. Traditionally, ASR models are evaluated using metrics like Word Error Rate (WER) and Character Error Rate (CER), which depend on ground truth labels. As a result of limited labeled data from diverse domains and testing conditions, the true generalization capabilities of these models beyond standard benchmarks remain unclear. Moreover, labeling data is both costly and time-consuming. To address this, we propose a novel label-free approach for approximating ASR performance metrics, eliminating the need for ground truth labels. Our method utilizes multimodal embeddings in a unified space for speech and transcription representations, combined with a high-quality proxy model to compute proxy metrics. These features are used to train a regression model to predict key ASR metrics like Word Error Rate (WER) and Character Error Rate (CER). We experiment with over 40 models across 14 datasets representing both standard and in-the-wild testing conditions. Our results show that we approximate the metrics within a single-digit absolute difference across all experimental configurations, outperforming the most recent baseline by more than 50\%.
Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models
Feb 18, 2025

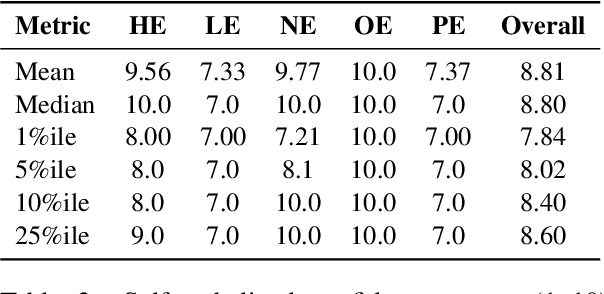
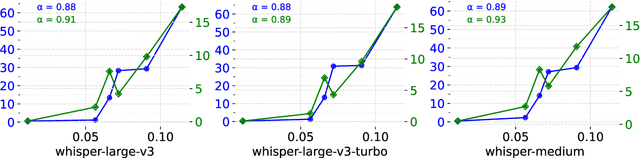
Speech foundation models trained at a massive scale, both in terms of model and data size, result in robust systems capable of performing multiple speech tasks, including automatic speech recognition (ASR). These models transcend language and domain barriers, yet effectively measuring their performance remains a challenge. Traditional metrics like word error rate (WER) and character error rate (CER) are commonly used to evaluate ASR performance but often fail to reflect transcription quality in critical contexts, particularly when detecting fabricated outputs. This phenomenon, known as hallucination, is especially concerning in high-stakes domains such as healthcare, legal, and aviation, where errors can have severe consequences. In our work, we address this gap by investigating hallucination in ASR models. We examine how factors such as distribution shifts, model size, and model architecture influence the hallucination error rate (HER), a metric we introduce to quantify hallucinations. Our analysis of 20 ASR models reveals \numinsights~key insights: (1) High WERs can mask low hallucination rates, while low WERs may conceal dangerous hallucinations. (2) Synthetic noise, both adversarial and common perturbations like white noise, pitch shift, and time stretching, increase HER. (3) Distribution shift correlates strongly with HER ($\alpha = 0.91$). Our findings highlight the importance of incorporating HER alongside traditional metrics like WER to better assess ASR model performance, particularly in high-stakes domains.
On the Diversity of Synthetic Data and its Impact on Training Large Language Models
Oct 19, 2024



The rise of Large Language Models (LLMs) has accentuated the need for diverse, high-quality pre-training data. Synthetic data emerges as a viable solution to the challenges of data scarcity and inaccessibility. While previous literature has focused predominantly on the quality and quantity of real data, our work enables the measurement of diversity in synthetic data and explores its impact on LLM performance. We study the downstream effects of synthetic data diversity during both the pre-training and fine-tuning stages by introducing a new diversity metric, \textit{LLM cluster-agent}, designed to evaluate the diversity of synthetic datasets. Through a series of controlled experiments with models of 350M and 1.4B parameters, we demonstrate that the proposed cluster-based LLM scoring of diversity correlates positively with both pre-training and supervised fine-tuning performance. Our findings also reveal that synthetic data diversity in pre-training affects supervised fine-tuning more significantly than pre-training itself, even for smaller models. We hope this study advances our understanding of the optimal use of synthetic data in LLM training and opens new avenues for efficient data generation processes.
What Do Speech Foundation Models Not Learn About Speech?
Oct 16, 2024



Understanding how speech foundation models capture non-verbal cues is crucial for improving their interpretability and adaptability across diverse tasks. In our work, we analyze several prominent models such as Whisper, Seamless, Wav2Vec, HuBERT, and Qwen2-Audio focusing on their learned representations in both paralinguistic and non-paralinguistic tasks from the Dynamic-SUPERB benchmark. Our study addresses three key questions: (1) What non-verbal cues (e.g., speaker intent, emotion, environmental context) are captured? (2) How are these cues represented across different layers of the models? and (3) To what extent can these representations be effectively adapted to downstream tasks? To answer these questions, we first evaluate the models in a zero-shot setting, followed by fine-tuning on layer-wise features extracted from these models. Our results provide insights into the models' capacity for generalization, the characteristics of their layer-wise representations, and the degree of transformation required for downstream task adaptation. Our findings suggest that some of these models perform well on various tasks in zero-shot settings, despite not being explicitly trained for those tasks. We also observe that zero-shot performance correlates with better-learned representations. The analysis of layer-wise features demonstrates that some models exhibit a convex relationship between the separability of the learned representations and model depth, with different layers capturing task-specific features.
uDistil-Whisper: Label-Free Data Filtering for Knowledge Distillation via Large-Scale Pseudo Labelling
Jul 01, 2024Recent work on distilling Whisper's knowledge into small models using pseudo-labels shows promising performance while reducing the size by up to 50\%. This results in small, efficient, and dedicated models. However, a critical step of distillation from pseudo-labels involves filtering high-quality predictions and using only those during training. This step requires ground truth to compare and filter bad examples making the whole process supervised. In addition to that, the distillation process requires a large amount of data thereby limiting the ability to distil models in low-resource settings. To address this challenge, we propose an unsupervised or label-free framework for distillation, thus eliminating the requirement for labeled data altogether. Through experimentation, we show that our best distilled models outperform the teacher model by 5-7 points in terms of WER. Additionally, our models are on par with or better than similar supervised data filtering setup. When we scale the data, our models significantly outperform all zero-shot and supervised models. In this work, we demonstrate that it's possible to distill large Whisper models into relatively small models without using any labeled data. As a result, our distilled models are 25-50\% more compute and memory efficient while maintaining performance equal to or better than the teacher model.
Towards Zero-Shot Text-To-Speech for Arabic Dialects
Jun 25, 2024



Zero-shot multi-speaker text-to-speech (ZS-TTS) systems have advanced for English, however, it still lags behind due to insufficient resources. We address this gap for Arabic, a language of more than 450 million native speakers, by first adapting a sizeable existing dataset to suit the needs of speech synthesis. Additionally, we employ a set of Arabic dialect identification models to explore the impact of pre-defined dialect labels on improving the ZS-TTS model in a multi-dialect setting. Subsequently, we fine-tune the XTTS\footnote{https://docs.coqui.ai/en/latest/models/xtts.html}\footnote{https://medium.com/machine-learns/xtts-v2-new-version-of-the-open-source-text-to-speech-model-af73914db81f}\footnote{https://medium.com/@erogol/xtts-v1-techincal-notes-eb83ff05bdc} model, an open-source architecture. We then evaluate our models on a dataset comprising 31 unseen speakers and an in-house dialectal dataset. Our automated and human evaluation results show convincing performance while capable of generating dialectal speech. Our study highlights significant potential for improvements in this emerging area of research in Arabic.
To Distill or Not to Distill? On the Robustness of Robust Knowledge Distillation
Jun 06, 2024Arabic is known to present unique challenges for Automatic Speech Recognition (ASR). On one hand, its rich linguistic diversity and wide range of dialects complicate the development of robust, inclusive models. On the other, current multilingual ASR models are compute-intensive and lack proper comprehensive evaluations. In light of these challenges, we distill knowledge from large teacher models into smaller student variants that are more efficient. We also introduce a novel human-annotated dataset covering five under-represented Arabic dialects for evaluation. We further evaluate both our models and existing SoTA multilingual models on both standard available benchmarks and our new dialectal data. Our best-distilled model's overall performance ($45.0$\% WER) surpasses that of a SoTA model twice its size (SeamlessM4T-large-v2, WER=$47.0$\%) and its teacher model (Whisper-large-v2, WER=$55.1$\%), and its average performance on our new dialectal data ($56.9$\% WER) outperforms all other models. To gain more insight into the poor performance of these models on dialectal data, we conduct an error analysis and report the main types of errors the different models tend to make. The GitHub repository for the project is available at \url{https://github.com/UBC-NLP/distill-whisper-ar}.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 27, 2023



Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
TARJAMAT: Evaluation of Bard and ChatGPT on Machine Translation of Ten Arabic Varieties
Aug 06, 2023



Large language models (LLMs) finetuned to follow human instructions have recently emerged as a breakthrough in AI. Models such as Google Bard and OpenAI ChatGPT, for example, are surprisingly powerful tools for question answering, code debugging, and dialogue generation. Despite the purported multilingual proficiency of these models, their linguistic inclusivity remains insufficiently explored. Considering this constraint, we present a thorough assessment of Bard and ChatGPT (encompassing both GPT-3.5 and GPT-4) regarding their machine translation proficiencies across ten varieties of Arabic. Our evaluation covers diverse Arabic varieties such as Classical Arabic, Modern Standard Arabic, and several nuanced dialectal variants. Furthermore, we undertake a human-centric study to scrutinize the efficacy of the most recent model, Bard, in following human instructions during translation tasks. Our exhaustive analysis indicates that LLMs may encounter challenges with certain Arabic dialects, particularly those for which minimal public data exists, such as Algerian and Mauritanian dialects. However, they exhibit satisfactory performance with more prevalent dialects, albeit occasionally trailing behind established commercial systems like Google Translate. Additionally, our analysis reveals a circumscribed capability of Bard in aligning with human instructions in translation contexts. Collectively, our findings underscore that prevailing LLMs remain far from inclusive, with only limited ability to cater for the linguistic and cultural intricacies of diverse communities.