 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNurseLLM: The First Specialized Language Model for Nursing
Oct 08, 2025Recent advancements in large language models (LLMs) have significantly transformed medical systems. However, their potential within specialized domains such as nursing remains largely underexplored. In this work, we introduce NurseLLM, the first nursing-specialized LLM tailored for multiple choice question-answering (MCQ) tasks. We develop a multi-stage data generation pipeline to build the first large scale nursing MCQ dataset to train LLMs on a broad spectrum of nursing topics. We further introduce multiple nursing benchmarks to enable rigorous evaluation. Our extensive experiments demonstrate that NurseLLM outperforms SoTA general-purpose and medical-specialized LLMs of comparable size on different benchmarks, underscoring the importance of a specialized LLM for the nursing domain. Finally, we explore the role of reasoning and multi-agent collaboration systems in nursing, highlighting their promise for future research and applications.
GreenLLaMA: A Framework for Detoxification with Explanations
Feb 25, 2024



Prior works on detoxification are scattered in the sense that they do not cover all aspects of detoxification needed in a real-world scenario. Notably, prior works restrict the task of developing detoxification models to only a seen subset of platforms, leaving the question of how the models would perform on unseen platforms unexplored. Additionally, these works do not address non-detoxifiability, a phenomenon whereby the toxic text cannot be detoxified without altering the meaning. We propose GreenLLaMA, the first comprehensive end-to-end detoxification framework, which attempts to alleviate the aforementioned limitations. We first introduce a cross-platform pseudo-parallel corpus applying multi-step data processing and generation strategies leveraging ChatGPT. We then train a suite of detoxification models with our cross-platform corpus. We show that our detoxification models outperform the SoTA model trained with human-annotated parallel corpus. We further introduce explanation to promote transparency and trustworthiness. GreenLLaMA additionally offers a unique paraphrase detector especially dedicated for the detoxification task to tackle the non-detoxifiable cases. Through experimental analysis, we demonstrate the effectiveness of our cross-platform corpus and the robustness of GreenLLaMA against adversarial toxicity.
TARJAMAT: Evaluation of Bard and ChatGPT on Machine Translation of Ten Arabic Varieties
Aug 06, 2023



Large language models (LLMs) finetuned to follow human instructions have recently emerged as a breakthrough in AI. Models such as Google Bard and OpenAI ChatGPT, for example, are surprisingly powerful tools for question answering, code debugging, and dialogue generation. Despite the purported multilingual proficiency of these models, their linguistic inclusivity remains insufficiently explored. Considering this constraint, we present a thorough assessment of Bard and ChatGPT (encompassing both GPT-3.5 and GPT-4) regarding their machine translation proficiencies across ten varieties of Arabic. Our evaluation covers diverse Arabic varieties such as Classical Arabic, Modern Standard Arabic, and several nuanced dialectal variants. Furthermore, we undertake a human-centric study to scrutinize the efficacy of the most recent model, Bard, in following human instructions during translation tasks. Our exhaustive analysis indicates that LLMs may encounter challenges with certain Arabic dialects, particularly those for which minimal public data exists, such as Algerian and Mauritanian dialects. However, they exhibit satisfactory performance with more prevalent dialects, albeit occasionally trailing behind established commercial systems like Google Translate. Additionally, our analysis reveals a circumscribed capability of Bard in aligning with human instructions in translation contexts. Collectively, our findings underscore that prevailing LLMs remain far from inclusive, with only limited ability to cater for the linguistic and cultural intricacies of diverse communities.
GPTAraEval: A Comprehensive Evaluation of ChatGPT on Arabic NLP
May 24, 2023



The recent emergence of ChatGPT has brought a revolutionary change in the landscape of NLP. Although ChatGPT has consistently shown impressive performance on English benchmarks, its exact capabilities on most other languages remain largely unknown. To better understand ChatGPT's capabilities on Arabic, we present a large-scale evaluation of the model on a broad range of Arabic NLP tasks. Namely, we evaluate ChatGPT on 32 diverse natural language understanding and generation tasks on over 60 different datasets. To the best of our knowledge, our work offers the first performance analysis of ChatGPT on Arabic NLP at such a massive scale. Our results show that, despite its success on English benchmarks, ChatGPT trained in-context (few-shot) is consistently outperformed by much smaller dedicated models finetuned on Arabic. These results suggest that there is significant place for improvement for instruction-tuned LLMs such as ChatGPT.
JASMINE: Arabic GPT Models for Few-Shot Learning
Dec 21, 2022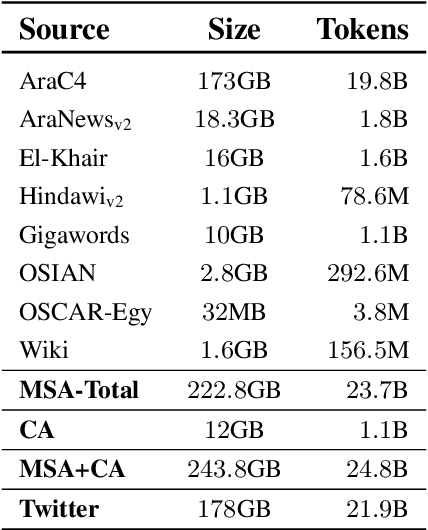
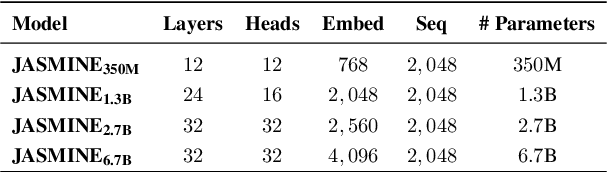
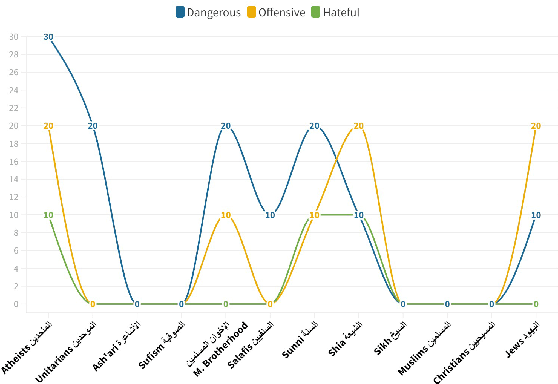
Task agnostic generative pretraining (GPT) has recently proved promising for zero- and few-shot learning, gradually diverting attention from the expensive supervised learning paradigm. Although the community is accumulating knowledge as to capabilities of English-language autoregressive models such as GPT-3 adopting this generative approach, scholarship about these models remains acutely Anglocentric. Consequently, the community currently has serious gaps in its understanding of this class of models, their potential, and their societal impacts in diverse settings, linguistic traditions, and cultures. To alleviate this issue for Arabic, a collection of diverse languages and language varieties with more than $400$ million population, we introduce JASMINE, a suite of powerful Arabic autoregressive Transformer language models ranging in size between 300 million-13 billion parameters. We pretrain our new models with large amounts of diverse data (400GB of text) from different Arabic varieties and domains. We evaluate JASMINE extensively in both intrinsic and extrinsic settings, using a comprehensive benchmark for zero- and few-shot learning across a wide range of NLP tasks. We also carefully develop and release a novel benchmark for both automated and human evaluation of Arabic autoregressive models focused at investigating potential social biases, harms, and toxicity in these models. We aim to responsibly release our models with interested researchers, along with code for experimenting with them
Cross-Platform and Cross-Domain Abusive Language Detection with Supervised Contrastive Learning
Nov 11, 2022



The prevalence of abusive language on different online platforms has been a major concern that raises the need for automated cross-platform abusive language detection. However, prior works focus on concatenating data from multiple platforms, inherently adopting Empirical Risk Minimization (ERM) method. In this work, we address this challenge from the perspective of domain generalization objective. We design SCL-Fish, a supervised contrastive learning integrated meta-learning algorithm to detect abusive language on unseen platforms. Our experimental analysis shows that SCL-Fish achieves better performance over ERM and the existing state-of-the-art models. We also show that SCL-Fish is data-efficient and achieves comparable performance with the large-scale pre-trained models upon finetuning for the abusive language detection task.