 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJASMINE: Arabic GPT Models for Few-Shot Learning
Paper and Code
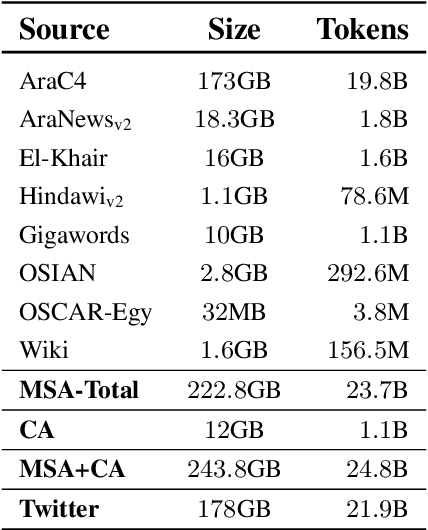
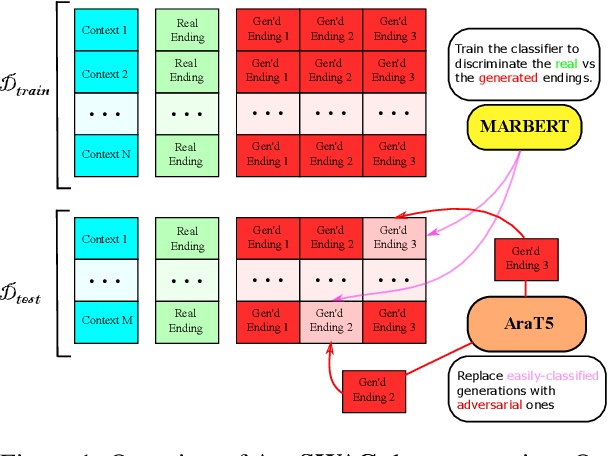
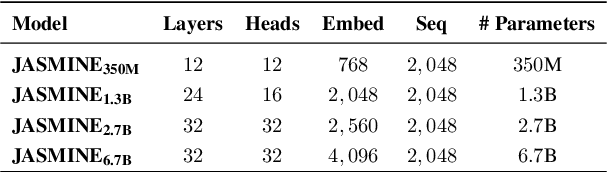
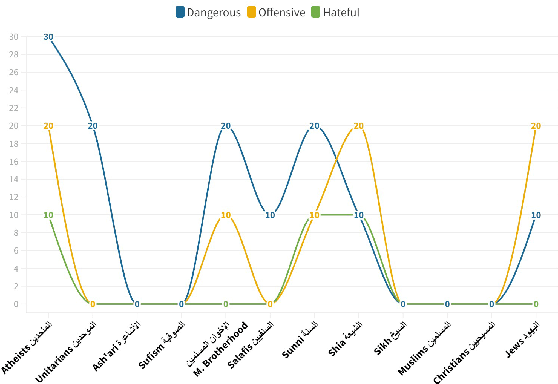
Task agnostic generative pretraining (GPT) has recently proved promising for zero- and few-shot learning, gradually diverting attention from the expensive supervised learning paradigm. Although the community is accumulating knowledge as to capabilities of English-language autoregressive models such as GPT-3 adopting this generative approach, scholarship about these models remains acutely Anglocentric. Consequently, the community currently has serious gaps in its understanding of this class of models, their potential, and their societal impacts in diverse settings, linguistic traditions, and cultures. To alleviate this issue for Arabic, a collection of diverse languages and language varieties with more than $400$ million population, we introduce JASMINE, a suite of powerful Arabic autoregressive Transformer language models ranging in size between 300 million-13 billion parameters. We pretrain our new models with large amounts of diverse data (400GB of text) from different Arabic varieties and domains. We evaluate JASMINE extensively in both intrinsic and extrinsic settings, using a comprehensive benchmark for zero- and few-shot learning across a wide range of NLP tasks. We also carefully develop and release a novel benchmark for both automated and human evaluation of Arabic autoregressive models focused at investigating potential social biases, harms, and toxicity in these models. We aim to responsibly release our models with interested researchers, along with code for experimenting with them