 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArab Voices: Mapping Standard and Dialectal Arabic Speech Technology
Jan 19, 2026Dialectal Arabic (DA) speech data vary widely in domain coverage, dialect labeling practices, and recording conditions, complicating cross-dataset comparison and model evaluation. To characterize this landscape, we conduct a computational analysis of linguistic ``dialectness'' alongside objective proxies of audio quality on the training splits of widely used DA corpora. We find substantial heterogeneity both in acoustic conditions and in the strength and consistency of dialectal signals across datasets, underscoring the need for standardized characterization beyond coarse labels. To reduce fragmentation and support reproducible evaluation, we introduce Arab Voices, a standardized framework for DA ASR. Arab Voices provides unified access to 31 datasets spanning 14 dialects, with harmonized metadata and evaluation utilities. We further benchmark a range of recent ASR systems, establishing strong baselines for modern DA ASR.
AI Transparency in Academic Search Systems: An Initial Exploration
Aug 02, 2024
As AI-enhanced academic search systems become increasingly popular among researchers, investigating their AI transparency is crucial to ensure trust in the search outcomes, as well as the reliability and integrity of scholarly work. This study employs a qualitative content analysis approach to examine the websites of a sample of 10 AI-enhanced academic search systems identified through university library guides. The assessed level of transparency varies across these systems: five provide detailed information about their mechanisms, three offer partial information, and two provide little to no information. These findings indicate that the academic community is recommending and using tools with opaque functionalities, raising concerns about research integrity, including issues of reproducibility and researcher responsibility.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 27, 2023



Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
On the Robustness of Arabic Speech Dialect Identification
Jun 01, 2023



Arabic dialect identification (ADI) tools are an important part of the large-scale data collection pipelines necessary for training speech recognition models. As these pipelines require application of ADI tools to potentially out-of-domain data, we aim to investigate how vulnerable the tools may be to this domain shift. With self-supervised learning (SSL) models as a starting point, we evaluate transfer learning and direct classification from SSL features. We undertake our evaluation under rich conditions, with a goal to develop ADI systems from pretrained models and ultimately evaluate performance on newly collected data. In order to understand what factors contribute to model decisions, we carry out a careful human study of a subset of our data. Our analysis confirms that domain shift is a major challenge for ADI models. We also find that while self-training does alleviate this challenges, it may be insufficient for realistic conditions.
Improving Automatic Speech Recognition for Non-Native English with Transfer Learning and Language Model Decoding
Feb 10, 2022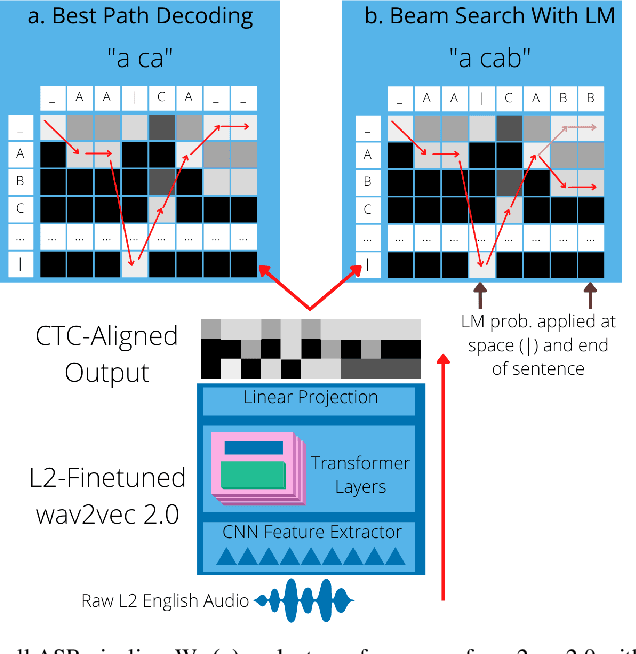

ASR systems designed for native English (L1) usually underperform on non-native English (L2). To address this performance gap, \textbf{(i)} we extend our previous work to investigate fine-tuning of a pre-trained wav2vec 2.0 model \cite{baevski2020wav2vec,xu2021self} under a rich set of L1 and L2 training conditions. We further \textbf{(ii)} incorporate language model decoding in the ASR system, along with the fine-tuning method. Quantifying gains acquired from each of these two approaches separately and an error analysis allows us to identify different sources of improvement within our models. We find that while the large self-trained wav2vec 2.0 may be internalizing sufficient decoding knowledge for clean L1 speech \cite{xu2021self}, this does not hold for L2 speech and accounts for the utility of employing language model decoding on L2 data.
Speech Technology for Everyone: Automatic Speech Recognition for Non-Native English with Transfer Learning
Oct 15, 2021


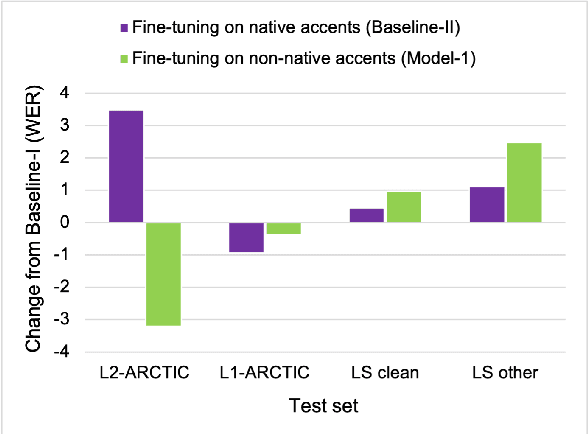
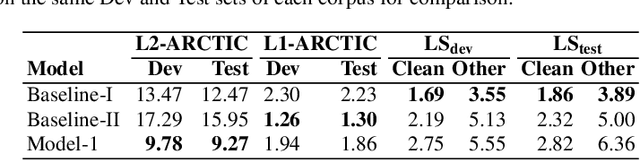
To address the performance gap of English ASR models on L2 English speakers, we evaluate fine-tuning of pretrained wav2vec 2.0 models (Baevski et al., 2020; Xu et al., 2021) on L2-ARCTIC, a non-native English speech corpus (Zhao et al., 2018) under different training settings. We compare \textbf{(a)} models trained with a combination of diverse accents to ones trained with only specific accents and \textbf{(b)} results from different single-accent models. Our experiments demonstrate the promise of developing ASR models for non-native English speakers, even with small amounts of L2 training data and even without a language model. Our models also excel in the zero-shot setting where we train on multiple L2 datasets and test on a blind L2 test set.