 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Automatic Speech Recognition for Non-Native English with Transfer Learning and Language Model Decoding
Paper and Code
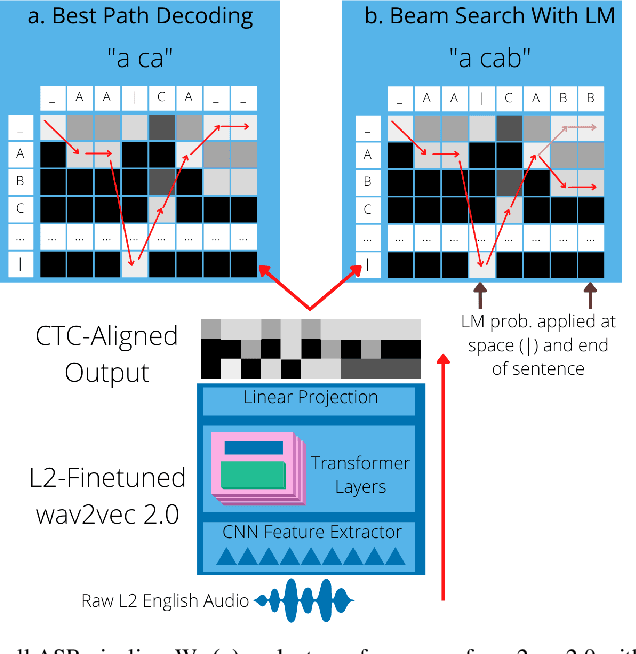

ASR systems designed for native English (L1) usually underperform on non-native English (L2). To address this performance gap, \textbf{(i)} we extend our previous work to investigate fine-tuning of a pre-trained wav2vec 2.0 model \cite{baevski2020wav2vec,xu2021self} under a rich set of L1 and L2 training conditions. We further \textbf{(ii)} incorporate language model decoding in the ASR system, along with the fine-tuning method. Quantifying gains acquired from each of these two approaches separately and an error analysis allows us to identify different sources of improvement within our models. We find that while the large self-trained wav2vec 2.0 may be internalizing sufficient decoding knowledge for clean L1 speech \cite{xu2021self}, this does not hold for L2 speech and accounts for the utility of employing language model decoding on L2 data.