 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Automatic Speech Recognition for Non-Native English with Transfer Learning and Language Model Decoding
Feb 10, 2022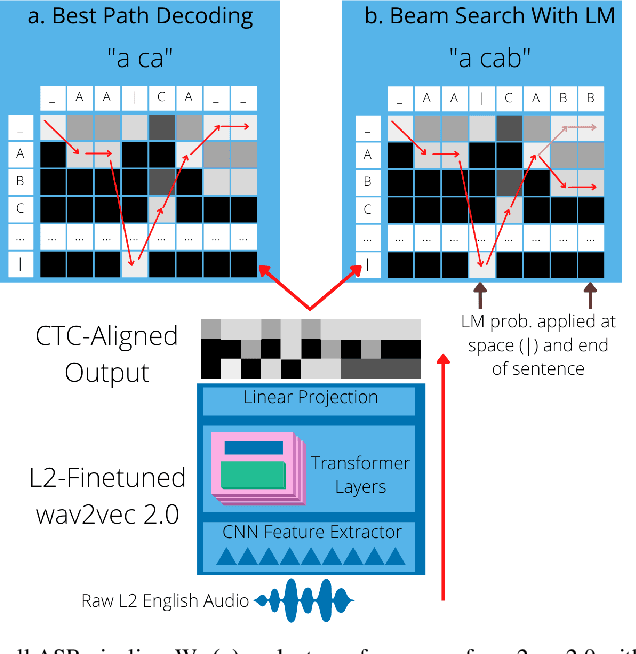

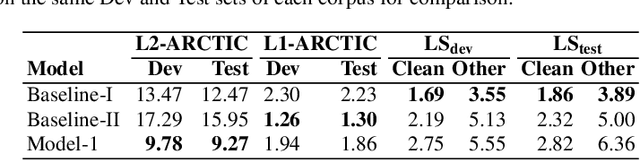
ASR systems designed for native English (L1) usually underperform on non-native English (L2). To address this performance gap, \textbf{(i)} we extend our previous work to investigate fine-tuning of a pre-trained wav2vec 2.0 model \cite{baevski2020wav2vec,xu2021self} under a rich set of L1 and L2 training conditions. We further \textbf{(ii)} incorporate language model decoding in the ASR system, along with the fine-tuning method. Quantifying gains acquired from each of these two approaches separately and an error analysis allows us to identify different sources of improvement within our models. We find that while the large self-trained wav2vec 2.0 may be internalizing sufficient decoding knowledge for clean L1 speech \cite{xu2021self}, this does not hold for L2 speech and accounts for the utility of employing language model decoding on L2 data.
Speech Technology for Everyone: Automatic Speech Recognition for Non-Native English with Transfer Learning
Oct 15, 2021


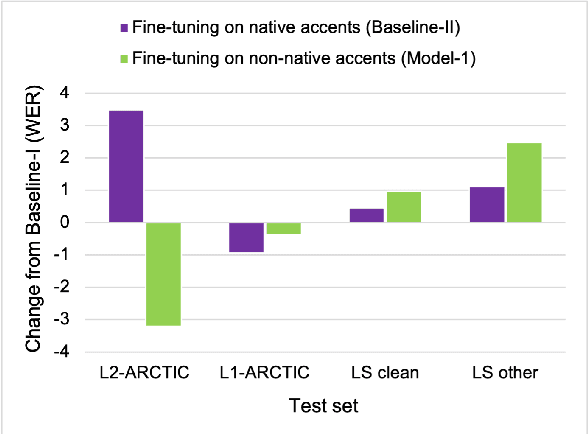
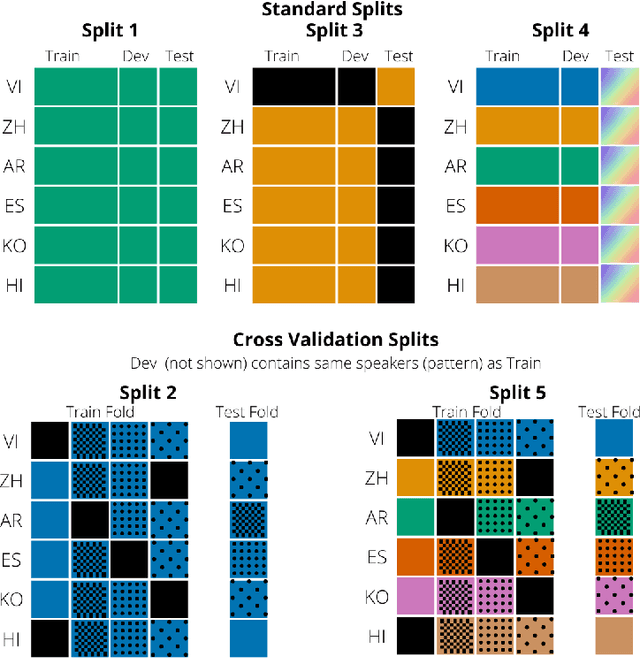
To address the performance gap of English ASR models on L2 English speakers, we evaluate fine-tuning of pretrained wav2vec 2.0 models (Baevski et al., 2020; Xu et al., 2021) on L2-ARCTIC, a non-native English speech corpus (Zhao et al., 2018) under different training settings. We compare \textbf{(a)} models trained with a combination of diverse accents to ones trained with only specific accents and \textbf{(b)} results from different single-accent models. Our experiments demonstrate the promise of developing ASR models for non-native English speakers, even with small amounts of L2 training data and even without a language model. Our models also excel in the zero-shot setting where we train on multiple L2 datasets and test on a blind L2 test set.