 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceSIR: A Multi-Agent Framework for Structured Analysis and Reporting of Agentic Execution Traces
Feb 28, 2026Agentic systems augment large language models with external tools and iterative decision making, enabling complex tasks such as deep research, function calling, and coding. However, their long and intricate execution traces make failure diagnosis and root cause analysis extremely challenging. Manual inspection does not scale, while directly applying LLMs to raw traces is hindered by input length limits and unreliable reasoning. Focusing solely on final task outcomes further discards critical behavioral information required for accurate issue localization. To address these issues, we propose TraceSIR, a multi-agent framework for structured analysis and reporting of agentic execution traces. TraceSIR coordinates three specialized agents: (1) StructureAgent, which introduces a novel abstraction format, TraceFormat, to compress execution traces while preserving essential behavioral information; (2) InsightAgent, which performs fine-grained diagnosis including issue localization, root cause analysis, and optimization suggestions; (3) ReportAgent, which aggregates insights across task instances and generates comprehensive analysis reports. To evaluate TraceSIR, we construct TraceBench, covering three real-world agentic scenarios, and introduce ReportEval, an evaluation protocol for assessing the quality and usability of analysis reports aligned with industry needs. Experiments show that TraceSIR consistently produces coherent, informative, and actionable reports, significantly outperforming existing approaches across all evaluation dimensions. Our project and video are publicly available at https://github.com/SHU-XUN/TraceSIR.
RAVEL: Reasoning Agents for Validating and Evaluating LLM Text Synthesis
Feb 28, 2026Large Language Models have evolved from single-round generators into long-horizon agents, capable of complex text synthesis scenarios. However, current evaluation frameworks lack the ability to assess the actual synthesis operations, such as outlining, drafting, and editing. Consequently, they fail to evaluate the actual and detailed capabilities of LLMs. To bridge this gap, we introduce RAVEL, an agentic framework that enables the LLM testers to autonomously plan and execute typical synthesis operations, including outlining, drafting, reviewing, and refining. Complementing this framework, we present C3EBench, a comprehensive benchmark comprising 1,258 samples derived from professional human writings. We utilize a "reverse-engineering" pipeline to isolate specific capabilities across four tasks: Cloze, Edit, Expand, and End-to-End. Through our analysis of 14 LLMs, we uncover that most LLMs struggle with tasks that demand contextual understanding under limited or under-specified instructions. By augmenting RAVEL with SOTA LLMs as operators, we find that such agentic text synthesis is dominated by the LLM's reasoning capability rather than raw generative capacity. Furthermore, we find that a strong reasoner can guide a weaker generator to yield higher-quality results, whereas the inverse does not hold. Our code and data are available at this link: https://github.com/ZhuoerFeng/RAVEL-Reasoning-Agents-Text-Eval.
RLAR: An Agentic Reward System for Multi-task Reinforcement Learning on Large Language Models
Feb 28, 2026Large language model alignment via reinforcement learning depends critically on reward function quality. However, static, domain-specific reward models are often costly to train and exhibit poor generalization in out-of-distribution scenarios encountered during RL iterations. We present RLAR (Reinforcement Learning from Agent Rewards), an agent-driven framework that dynamically assigns tailored reward functions to individual queries. Specifically, RLAR transforms reward acquisition into a dynamic tool synthesis and invocation task. It leverages LLM agents to autonomously retrieve optimal reward models from the Internet and synthesize programmatic verifiers through code generation. This allows the reward system to self-evolve with the shifting data distributions during training. Experimental results demonstrate that RLAR yields consistent performance gains ranging from 10 to 60 across mathematics, coding, translation, and dialogue tasks. On RewardBench-V2, RLAR significantly outperforms static baselines and approaches the performance upper bound, demonstrating superior generalization through dynamic reward orchestration. The data and code are available on this link: https://github.com/ZhuoerFeng/RLAR.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
MVSS: A Unified Framework for Multi-View Structured Survey Generation
Jan 14, 2026Scientific surveys require not only summarizing large bodies of literature, but also organizing them into clear and coherent conceptual structures. Existing automatic survey generation methods typically focus on linear text generation and struggle to explicitly model hierarchical relations among research topics and structured methodological comparisons, resulting in gaps in structural organization compared to expert-written surveys. We propose MVSS, a multi-view structured survey generation framework that jointly generates and aligns citation-grounded hierarchical trees, structured comparison tables, and survey text. MVSS follows a structure-first paradigm: it first constructs a conceptual tree of the research domain, then generates comparison tables constrained by the tree, and finally uses both as structural constraints for text generation. This enables complementary multi-view representations across structure, comparison, and narrative. We introduce an evaluation framework assessing structural quality, comparative completeness, and citation fidelity. Experiments on 76 computer science topics show MVSS outperforms existing methods in organization and evidence grounding, achieving performance comparable to expert surveys.
DVD: A Robust Method for Detecting Variant Contamination in Large Language Model Evaluation
Jan 08, 2026Evaluating large language models (LLMs) is increasingly confounded by \emph{variant contamination}: the training corpus contains semantically equivalent yet lexically or syntactically altered versions of test items. Unlike verbatim leakage, these paraphrased or structurally transformed variants evade existing detectors based on sampling consistency or perplexity, thereby inflating benchmark scores via memorization rather than genuine reasoning. We formalize this problem and introduce \textbf{DVD} (\textbf{D}etection via \textbf{V}ariance of generation \textbf{D}istribution), a single-sample detector that models the local output distribution induced by temperature sampling. Our key insight is that contaminated items trigger alternation between a \emph{memory-adherence} state and a \emph{perturbation-drift} state, yielding abnormally high variance in the synthetic difficulty of low-probability tokens; uncontaminated items remain in drift with comparatively smooth variance. We construct the first benchmark for variant contamination across two domains Omni-MATH and SuperGPQA by generating and filtering semantically equivalent variants, and simulate contamination via fine-tuning models of different scales and architectures (Qwen2.5 and Llama3.1). Across datasets and models, \textbf{DVD} consistently outperforms perplexity-based, Min-$k$\%++, edit-distance (CDD), and embedding-similarity baselines, while exhibiting strong robustness to hyperparameters. Our results establish variance of the generation distribution as a principled and practical fingerprint for detecting variant contamination in LLM evaluation.
SAEMark: Multi-bit LLM Watermarking with Inference-Time Scaling
Aug 11, 2025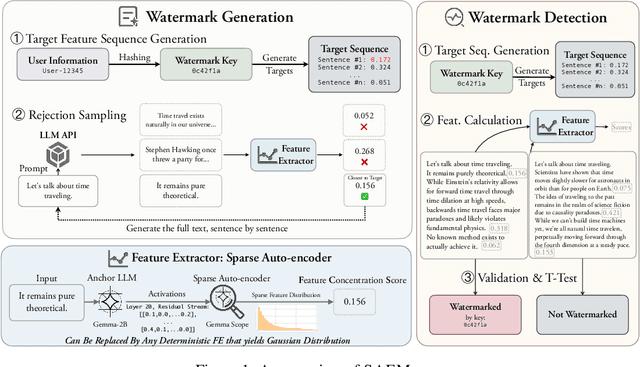


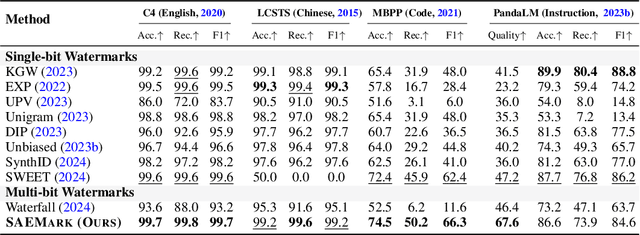
Watermarking LLM-generated text is critical for content attribution and misinformation prevention. However, existing methods compromise text quality, require white-box model access and logit manipulation. These limitations exclude API-based models and multilingual scenarios. We propose SAEMark, a general framework for post-hoc multi-bit watermarking that embeds personalized messages solely via inference-time, feature-based rejection sampling without altering model logits or requiring training. Our approach operates on deterministic features extracted from generated text, selecting outputs whose feature statistics align with key-derived targets. This framework naturally generalizes across languages and domains while preserving text quality through sampling LLM outputs instead of modifying. We provide theoretical guarantees relating watermark success probability and compute budget that hold for any suitable feature extractor. Empirically, we demonstrate the framework's effectiveness using Sparse Autoencoders (SAEs), achieving superior detection accuracy and text quality. Experiments across 4 datasets show SAEMark's consistent performance, with 99.7% F1 on English and strong multi-bit detection accuracy. SAEMark establishes a new paradigm for scalable watermarking that works out-of-the-box with closed-source LLMs while enabling content attribution.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Visual Thoughts: A Unified Perspective of Understanding Multimodal Chain-of-Thought
May 21, 2025Large Vision-Language Models (LVLMs) have achieved significant success in multimodal tasks, with multimodal chain-of-thought (MCoT) further enhancing performance and interpretability. Recent MCoT methods fall into two categories: (i) Textual-MCoT (T-MCoT), which takes multimodal input and produces textual output; and (ii) Interleaved-MCoT (I-MCoT), which generates interleaved image-text outputs. Despite advances in both approaches, the mechanisms driving these improvements are not fully understood. To fill this gap, we first reveal that MCoT boosts LVLMs by incorporating visual thoughts, which convey image information to the reasoning process regardless of the MCoT format, depending only on clarity and conciseness of expression. Furthermore, to explore visual thoughts systematically, we define four distinct forms of visual thought expressions and analyze them comprehensively. Our findings demonstrate that these forms differ in clarity and conciseness, yielding varying levels of MCoT improvement. Additionally, we explore the internal nature of visual thoughts, finding that visual thoughts serve as intermediaries between the input image and reasoning to deeper transformer layers, enabling more advanced visual information transmission. We hope that the visual thoughts can inspire further breakthroughs for future MCoT research.
Reasoning on Multiple Needles In A Haystack
Apr 05, 2025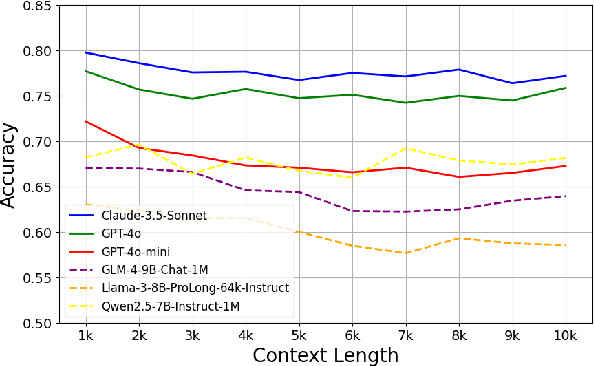



The Needle In A Haystack (NIAH) task has been widely used to evaluate the long-context question-answering capabilities of Large Language Models (LLMs). However, its reliance on simple retrieval limits its effectiveness. To address this limitation, recent studies have introduced the Multiple Needles In A Haystack Reasoning (MNIAH-R) task, which incorporates supporting documents (Multiple needles) of multi-hop reasoning tasks into a distracting context (Haystack}). Despite this advancement, existing approaches still fail to address the issue of models providing direct answers from internal knowledge, and they do not explain or mitigate the decline in accuracy as context length increases. In this paper, we tackle the memory-based answering problem by filtering out direct-answer questions, and we reveal that performance degradation is primarily driven by the reduction in the length of the thinking process as the input length increases. Building on this insight, we decompose the thinking process into retrieval and reasoning stages and introduce a reflection mechanism for multi-round extension. We also train a model using the generated iterative thinking process, which helps mitigate the performance degradation. Furthermore, we demonstrate the application of this retrieval-reflection capability in mathematical reasoning scenarios, improving GPT-4o's performance on AIME2024.