 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome-Refining Process Supervision for Code Generation
Dec 19, 2024



Large Language Models have demonstrated remarkable capabilities in code generation, yet they often struggle with complex programming tasks that require deep algorithmic reasoning. While process supervision through learned reward models shows promise in guiding reasoning steps, it requires expensive training data and suffers from unreliable evaluation. We propose Outcome-Refining Process Supervision, a novel paradigm that treats outcome refinement itself as the process to be supervised. Our framework leverages concrete execution signals to ground the supervision of reasoning steps, while using tree-structured exploration to maintain multiple solution trajectories simultaneously. Experiments demonstrate that our approach enables even smaller models to achieve high success accuracy and performance metrics on competitive programming tasks, creates more reliable verification than traditional reward models without requiring training PRMs. Our approach achieves significant improvements across 5 models and 3 datasets: an average of 26.9% increase in correctness and 42.2% in efficiency. The results suggest that providing structured reasoning space with concrete verification signals is crucial for solving complex programming tasks. We open-source all our code and data at: https://github.com/zhuohaoyu/ORPS
RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Aug 21, 2024
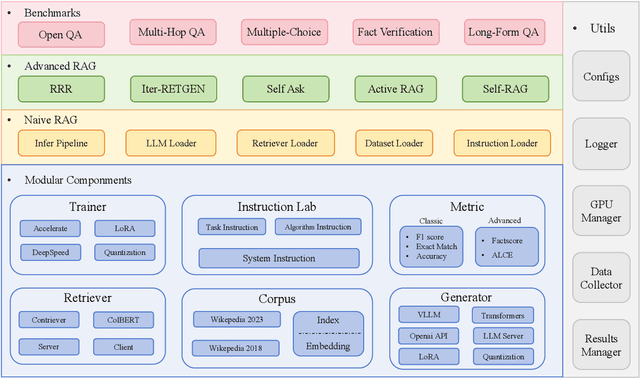

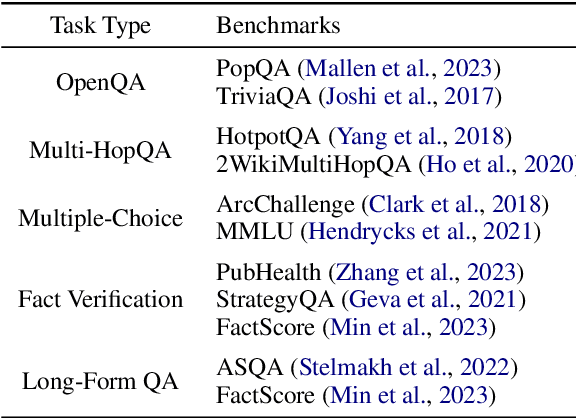
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Apr 09, 2024



The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
CodeShell Technical Report
Mar 23, 2024



Code large language models mark a pivotal breakthrough in artificial intelligence. They are specifically crafted to understand and generate programming languages, significantly boosting the efficiency of coding development workflows. In this technical report, we present CodeShell-Base, a seven billion-parameter foundation model with 8K context length, showcasing exceptional proficiency in code comprehension. By incorporating Grouped-Query Attention and Rotary Positional Embedding into GPT-2, CodeShell-Base integrates the structural merits of StarCoder and CodeLlama and forms its unique architectural design. We then carefully built a comprehensive data pre-processing process, including similar data deduplication, perplexity-based data filtering, and model-based data filtering. Through this process, We have curated 100 billion high-quality pre-training data from GitHub. Benefiting from the high-quality data, CodeShell-Base outperforms CodeLlama in Humaneval after training on just 500 billion tokens (5 epochs). We have conducted extensive experiments across multiple language datasets, including Python, Java, and C++, and the results indicate that our model possesses robust foundational capabilities in code comprehension and generation.
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
Jun 08, 2023



Instruction tuning large language models (LLMs) remains a challenging task, owing to the complexity of hyperparameter selection and the difficulty involved in evaluating the tuned models. To determine the optimal hyperparameters, an automatic, robust, and reliable evaluation benchmark is essential. However, establishing such a benchmark is not a trivial task due to the challenges associated with evaluation accuracy and privacy protection. In response to these challenges, we introduce a judge large language model, named PandaLM, which is trained to distinguish the superior model given several LLMs. PandaLM's focus extends beyond just the objective correctness of responses, which is the main focus of traditional evaluation datasets. It addresses vital subjective factors such as relative conciseness, clarity, adherence to instructions, comprehensiveness, and formality. To ensure the reliability of PandaLM, we collect a diverse human-annotated test dataset, where all contexts are generated by humans and labels are aligned with human preferences. Our results indicate that PandaLM-7B achieves 93.75% of GPT-3.5's evaluation ability and 88.28% of GPT-4's in terms of F1-score on our test dataset. PandaLM enables the evaluation of LLM to be fairer but with less cost, evidenced by significant improvements achieved by models tuned through PandaLM compared to their counterparts trained with default Alpaca's hyperparameters. In addition, PandaLM does not depend on API-based evaluations, thus avoiding potential data leakage. All resources of PandaLM are released at https://github.com/WeOpenML/PandaLM.