 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Aug 21, 2024
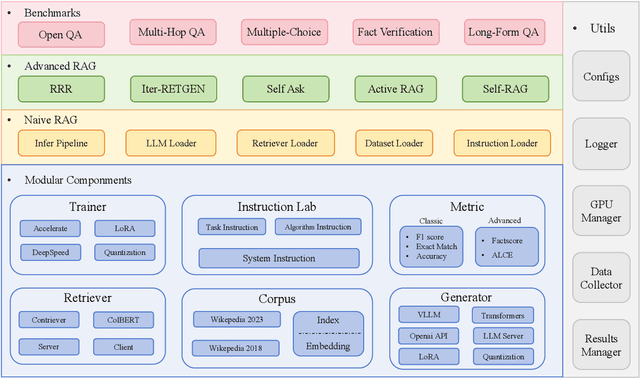

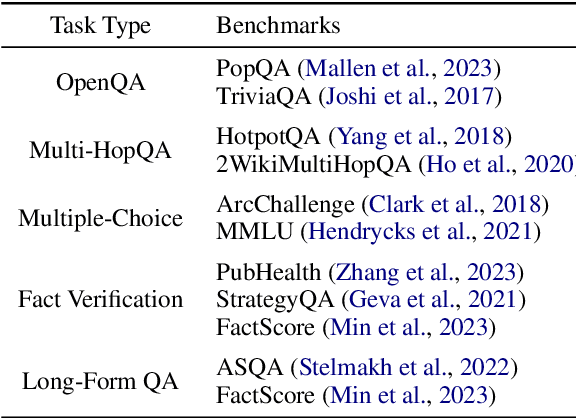
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
Deep Representations for Time-varying Brain Datasets
May 23, 2022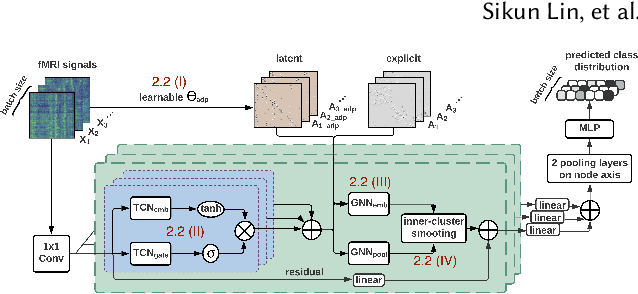

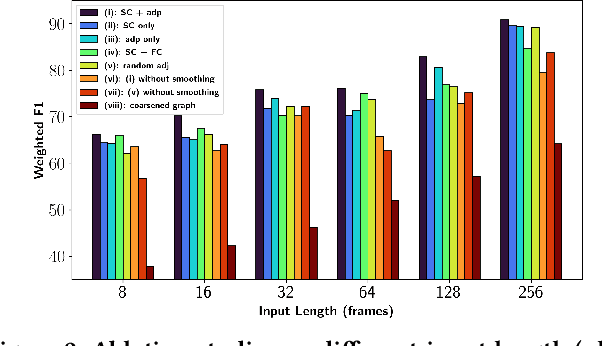
Finding an appropriate representation of dynamic activities in the brain is crucial for many downstream applications. Due to its highly dynamic nature, temporally averaged fMRI (functional magnetic resonance imaging) can only provide a narrow view of underlying brain activities. Previous works lack the ability to learn and interpret the latent dynamics in brain architectures. This paper builds an efficient graph neural network model that incorporates both region-mapped fMRI sequences and structural connectivities obtained from DWI (diffusion-weighted imaging) as inputs. We find good representations of the latent brain dynamics through learning sample-level adaptive adjacency matrices and performing a novel multi-resolution inner cluster smoothing. These modules can be easily adapted to and are potentially useful for other applications outside the neuroscience domain. We also attribute inputs with integrated gradients, which enables us to infer (1) highly involved brain connections and subnetworks for each task, (2) temporal keyframes of imaging sequences that characterize tasks, and (3) subnetworks that discriminate between individual subjects. This ability to identify critical subnetworks that characterize signal states across heterogeneous tasks and individuals is of great importance to neuroscience and other scientific domains. Extensive experiments and ablation studies demonstrate our proposed method's superiority and efficiency in spatial-temporal graph signal modeling with insightful interpretations of brain dynamics.
Fusion with Hierarchical Graphs for Mulitmodal Emotion Recognition
Sep 15, 2021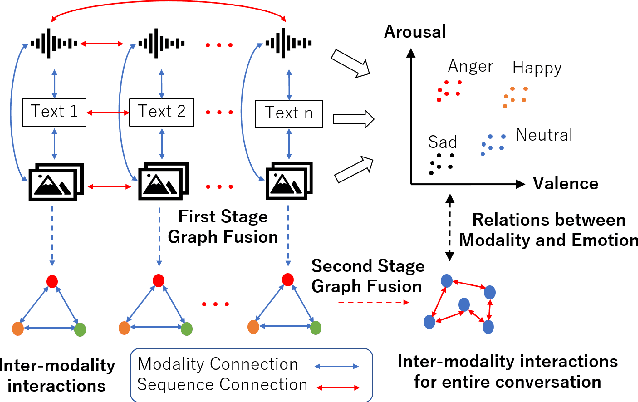
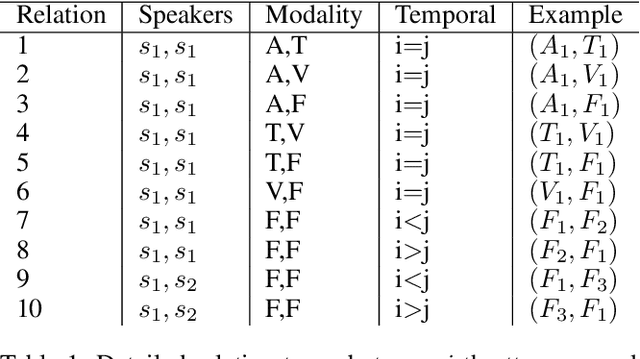
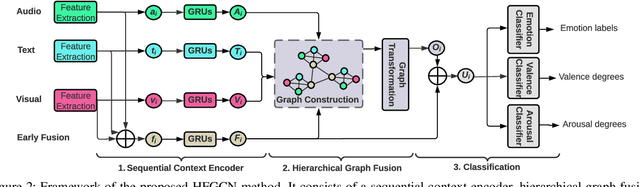
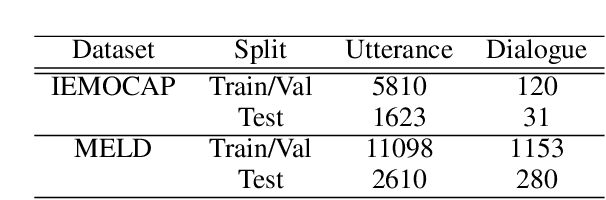
Automatic emotion recognition (AER) based on enriched multimodal inputs, including text, speech, and visual clues, is crucial in the development of emotionally intelligent machines. Although complex modality relationships have been proven effective for AER, they are still largely underexplored because previous works predominantly relied on various fusion mechanisms with simply concatenated features to learn multimodal representations for emotion classification. This paper proposes a novel hierarchical fusion graph convolutional network (HFGCN) model that learns more informative multimodal representations by considering the modality dependencies during the feature fusion procedure. Specifically, the proposed model fuses multimodality inputs using a two-stage graph construction approach and encodes the modality dependencies into the conversation representation. We verified the interpretable capabilities of the proposed method by projecting the emotional states to a 2D valence-arousal (VA) subspace. Extensive experiments showed the effectiveness of our proposed model for more accurate AER, which yielded state-of-the-art results on two public datasets, IEMOCAP and MELD.
U-Net with Hierarchical Bottleneck Attention for Landmark Detection in Fundus Images of the Degenerated Retina
Jul 09, 2021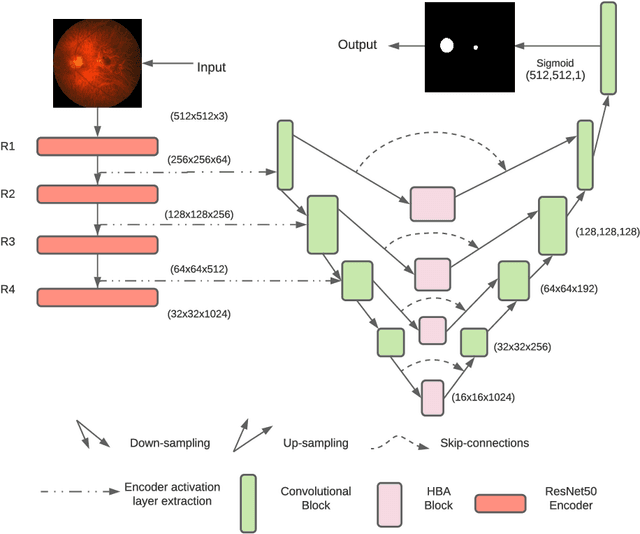

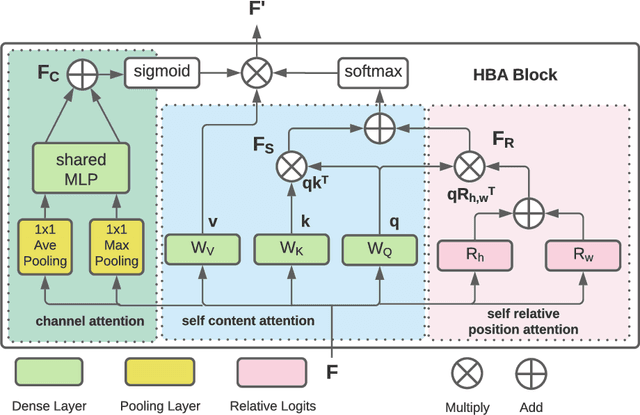

Fundus photography has routinely been used to document the presence and severity of retinal degenerative diseases such as age-related macular degeneration (AMD), glaucoma, and diabetic retinopathy (DR) in clinical practice, for which the fovea and optic disc (OD) are important retinal landmarks. However, the occurrence of lesions, drusen, and other retinal abnormalities during retinal degeneration severely complicates automatic landmark detection and segmentation. Here we propose HBA-U-Net: a U-Net backbone enriched with hierarchical bottleneck attention. The network consists of a novel bottleneck attention block that combines and refines self-attention, channel attention, and relative-position attention to highlight retinal abnormalities that may be important for fovea and OD segmentation in the degenerated retina. HBA-U-Net achieved state-of-the-art results on fovea detection across datasets and eye conditions (ADAM: Euclidean Distance (ED) of 25.4 pixels, REFUGE: 32.5 pixels, IDRiD: 32.1 pixels), on OD segmentation for AMD (ADAM: Dice Coefficient (DC) of 0.947), and on OD detection for DR (IDRiD: ED of 20.5 pixels). Our results suggest that HBA-U-Net may be well suited for landmark detection in the presence of a variety of retinal degenerative diseases.