 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion with Hierarchical Graphs for Mulitmodal Emotion Recognition
Paper and Code
Sep 15, 2021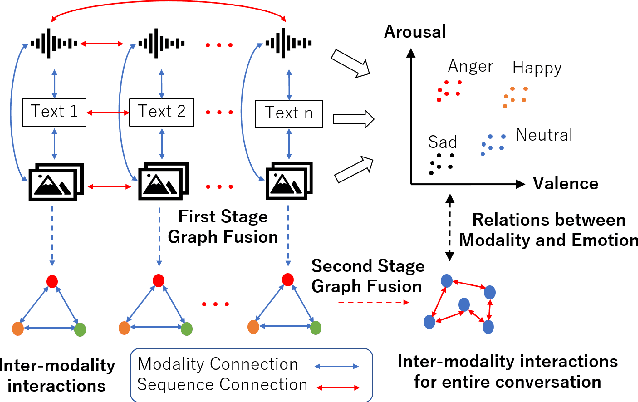
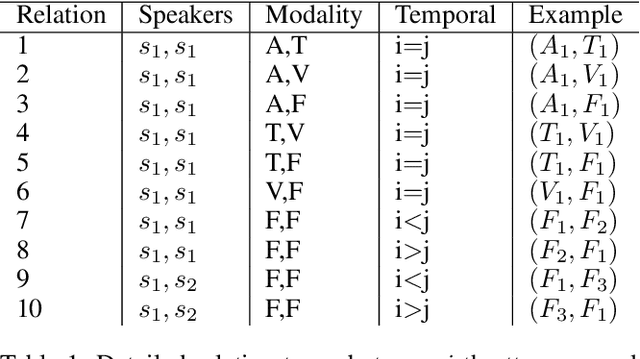
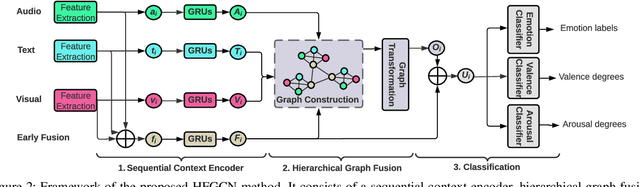
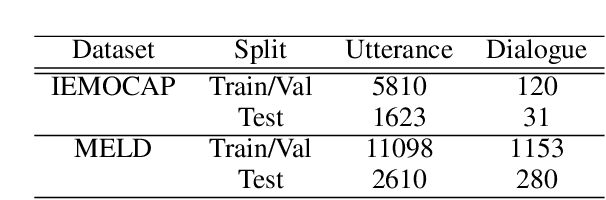
Automatic emotion recognition (AER) based on enriched multimodal inputs, including text, speech, and visual clues, is crucial in the development of emotionally intelligent machines. Although complex modality relationships have been proven effective for AER, they are still largely underexplored because previous works predominantly relied on various fusion mechanisms with simply concatenated features to learn multimodal representations for emotion classification. This paper proposes a novel hierarchical fusion graph convolutional network (HFGCN) model that learns more informative multimodal representations by considering the modality dependencies during the feature fusion procedure. Specifically, the proposed model fuses multimodality inputs using a two-stage graph construction approach and encodes the modality dependencies into the conversation representation. We verified the interpretable capabilities of the proposed method by projecting the emotional states to a 2D valence-arousal (VA) subspace. Extensive experiments showed the effectiveness of our proposed model for more accurate AER, which yielded state-of-the-art results on two public datasets, IEMOCAP and MELD.