 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis on the Functional Advantages of the Selection-Broadcast Cycle Structure: Global Workspace Theory and Dealing with a Real-Time World
May 20, 2025This paper discusses the functional advantages of the Selection-Broadcast Cycle structure proposed by Global Workspace Theory (GWT), inspired by human consciousness, particularly focusing on its applicability to artificial intelligence and robotics in dynamic, real-time scenarios. While previous studies often examined the Selection and Broadcast processes independently, this research emphasizes their combined cyclic structure and the resulting benefits for real-time cognitive systems. Specifically, the paper identifies three primary benefits: Dynamic Thinking Adaptation, Experience-Based Adaptation, and Immediate Real-Time Adaptation. This work highlights GWT's potential as a cognitive architecture suitable for sophisticated decision-making and adaptive performance in unsupervised, dynamic environments. It suggests new directions for the development and implementation of robust, general-purpose AI and robotics systems capable of managing complex, real-world tasks.
The First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025
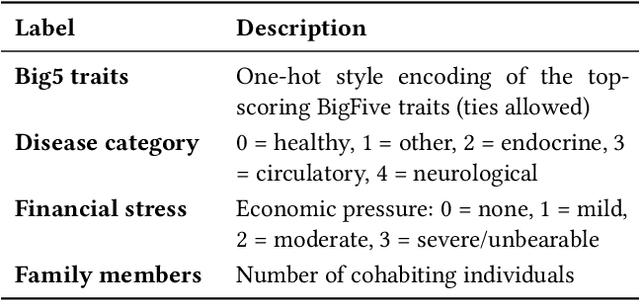


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
Influence of collaborative customer service by service robots and clerks in bakery stores
Dec 20, 2022



In recent years, various service robots have been introduced in stores as recommendation systems. Previous studies attempted to increase the influence of these robots by improving their social acceptance and trust. However, when such service robots recommend a product to customers in real environments, the effect on the customers is influenced not only by the robot itself, but also by the social influence of the surrounding people such as store clerks. Therefore, leveraging the social influence of the clerks may increase the influence of the robots on the customers. Hence, we compared the influence of robots with and without collaborative customer service between the robots and clerks in two bakery stores. The experimental results showed that collaborative customer service increased the purchase rate of the recommended bread and improved the impression regarding the robot and store experience of the customers. Because the results also showed that the workload required for the clerks to collaborate with the robot was not high, this study suggests that all stores with service robots may show high effectiveness in introducing collaborative customer service.
Service Robots in a Bakery Shop: A Field Study
Aug 19, 2022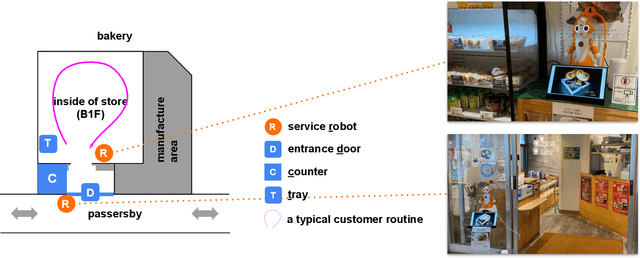
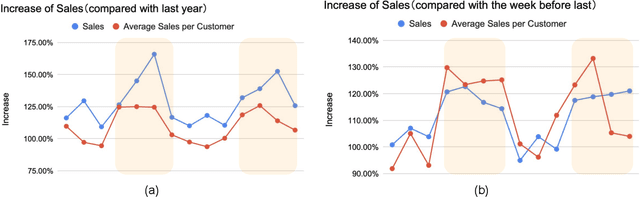
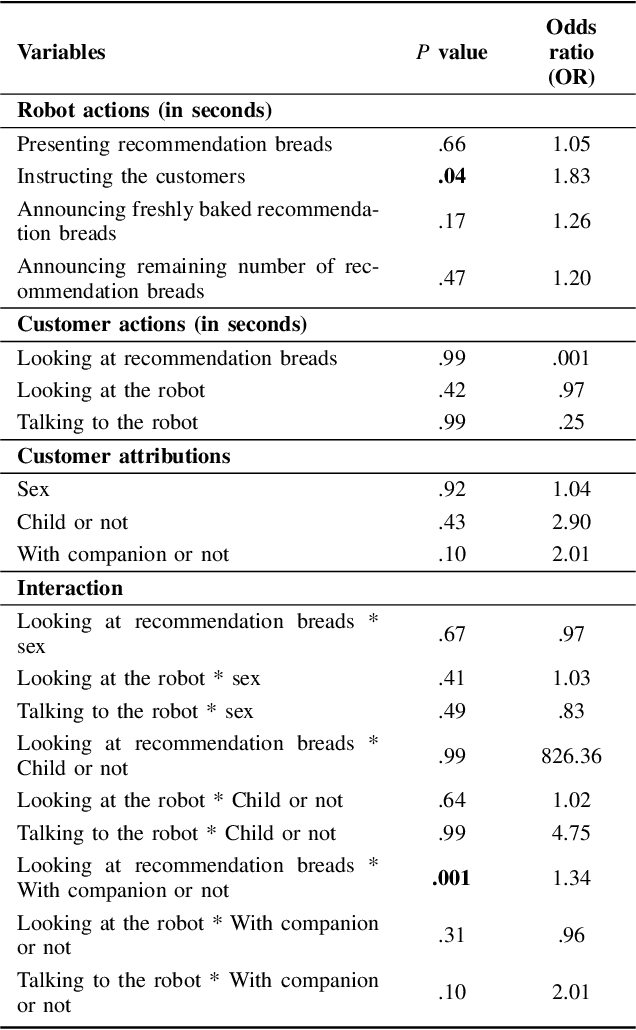
In this paper, we report on a field study in which we employed two service robots in a bakery store as a sales promotion. Previous studies have explored public applications of service robots public such as shopping malls. However, more evidence is needed that service robots can contribute to sales in real stores. Moreover, the behaviors of customers and service robots in the context of sales promotions have not been examined well. Hence, the types of robot behavior that can be considered effective and the customers' responses to these robots remain unclear. To address these issues, we installed two tele-operated service robots in a bakery store for nearly 2 weeks, one at the entrance as a greeter and the other one inside the store to recommend products. The results show a dramatic increase in sales during the days when the robots were applied. Furthermore, we annotated the video recordings of both the robots' and customers' behavior. We found that although the robot placed at the entrance successfully attracted the interest of the passersby, no apparent increase in the number of customers visiting the store was observed. However, we confirmed that the recommendations of the robot operating inside the store did have a positive impact. We discuss our findings in detail and provide both theoretical and practical recommendations for future research and applications.
Decoupling Speaker-Independent Emotions for Voice Conversion Via Source-Filter Networks
Oct 04, 2021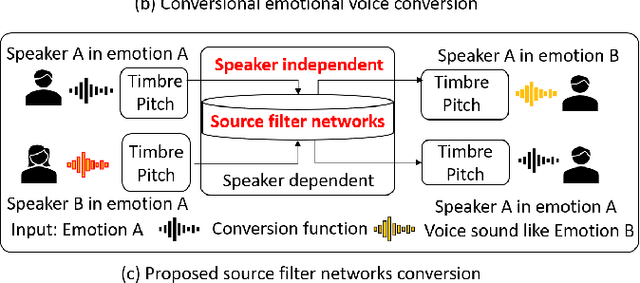
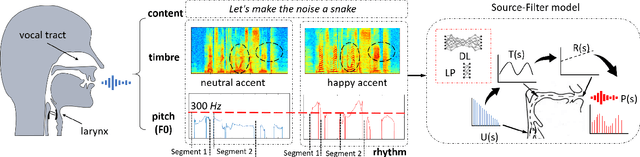
Emotional voice conversion (VC) aims to convert a neutral voice to an emotional (e.g. happy) one while retaining the linguistic information and speaker identity. We note that the decoupling of emotional features from other speech information (such as speaker, content, etc.) is the key to achieving remarkable performance. Some recent attempts about speech representation decoupling on the neutral speech can not work well on the emotional speech, due to the more complex acoustic properties involved in the latter. To address this problem, here we propose a novel Source-Filter-based Emotional VC model (SFEVC) to achieve proper filtering of speaker-independent emotion features from both the timbre and pitch features. Our SFEVC model consists of multi-channel encoders, emotion separate encoders, and one decoder. Note that all encoder modules adopt a designed information bottlenecks auto-encoder. Additionally, to further improve the conversion quality for various emotions, a novel two-stage training strategy based on the 2D Valence-Arousal (VA) space was proposed. Experimental results show that the proposed SFEVC along with a two-stage training strategy outperforms all baselines and achieves the state-of-the-art performance in speaker-independent emotional VC with nonparallel data.
Fusion with Hierarchical Graphs for Mulitmodal Emotion Recognition
Sep 15, 2021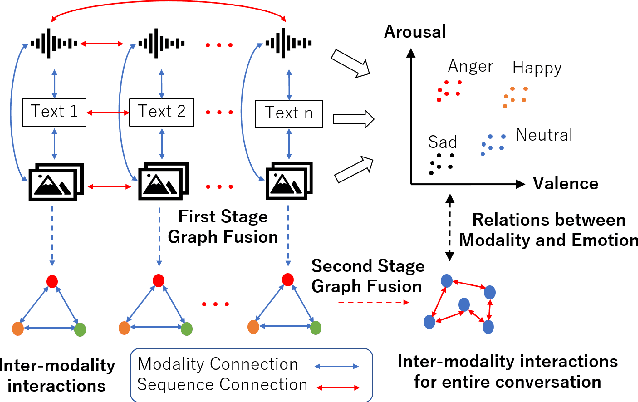
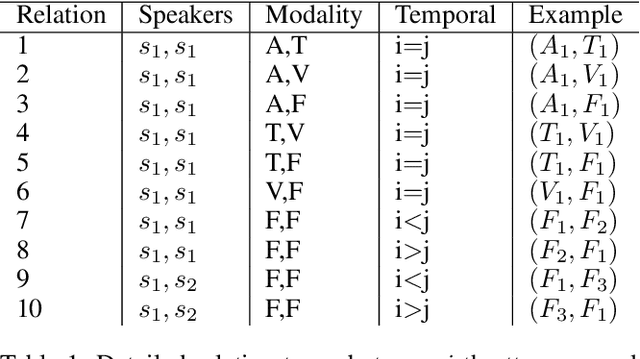
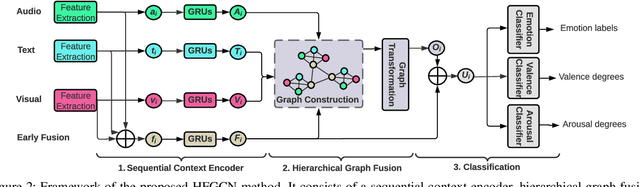
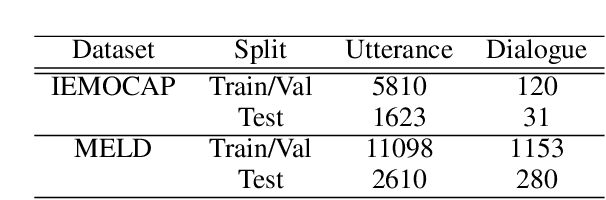
Automatic emotion recognition (AER) based on enriched multimodal inputs, including text, speech, and visual clues, is crucial in the development of emotionally intelligent machines. Although complex modality relationships have been proven effective for AER, they are still largely underexplored because previous works predominantly relied on various fusion mechanisms with simply concatenated features to learn multimodal representations for emotion classification. This paper proposes a novel hierarchical fusion graph convolutional network (HFGCN) model that learns more informative multimodal representations by considering the modality dependencies during the feature fusion procedure. Specifically, the proposed model fuses multimodality inputs using a two-stage graph construction approach and encodes the modality dependencies into the conversation representation. We verified the interpretable capabilities of the proposed method by projecting the emotional states to a 2D valence-arousal (VA) subspace. Extensive experiments showed the effectiveness of our proposed model for more accurate AER, which yielded state-of-the-art results on two public datasets, IEMOCAP and MELD.
Behavioral assessment of a humanoid robot when attracting pedestrians in a mall
Sep 06, 2021

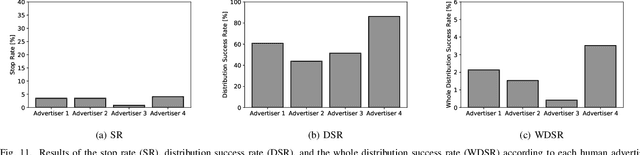
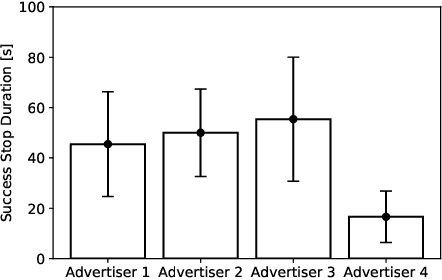
Research currently being conducted on the use of robots as human labor support technology. In particular, the service industry needs to allocate more manpower, and it will be important for robots to support people. This study focuses on using a humanoid robot as a social service robot to convey information in a shopping mall, and the robot's behavioral concepts were analyzed. In order to convey the information, two processes must occur. Pedestrians must stop in front of the robot, and the robot must continue the engagement with them. For the purpose of this study, three types of autonomous behavioral concepts of the robot for the general use were analyzed and compared in these processes in the experiment: active, passive-negative, and passive-positive concepts. After interactions were attempted with 65,000+ pedestrians, this study revealed that the passive-negative concept can make pedestrians stop more and stay longer. In order to evaluate the effectiveness of the robot in a real environment, the comparative results between three behaviors and human advertisers revealed that (1) the results of the active and passive-positive concepts of the robot are comparable to those of the humans, and (2) the performance of the passive-negative concept is higher than that of all participants. These findings demonstrate that the performance of robots is comparable to that of humans in providing information tasks in a limited environment; therefore, it is expected that service robots as a labor support technology will be able to perform well in the real world.
3D Head-Position Prediction in First-Person View by Considering Head Pose for Human-Robot Eye Contact
Mar 11, 2021

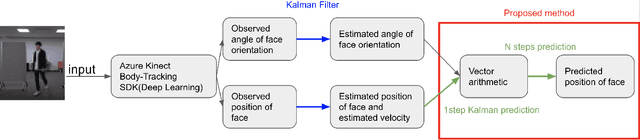

For a humanoid robot to make eye contact to initiate communication with a human, it is necessary to estimate the human's head position.However, eye contact becomes difficult due to the mechanical delay of the robot while the subject with whom the robot is interacting with is moving. Owing to these issues, it is important to perform head-position prediction to mitigate the effect of the delay in the robot's motion. Based on the fact that humans turn their heads before changing direction while walking, we hypothesized that the accuracy of three-dimensional(3D) head-position prediction from the first-person view can be improved by considering the head pose into account.We compared our method with the conventional Kalman filter-based method, and found our method to be more accurate. The experimental results show that considering the head pose helps improve the accuracy of 3D head-position prediction.
SeMemNN: A Semantic Matrix-Based Memory Neural Network for Text Classification
Mar 04, 2020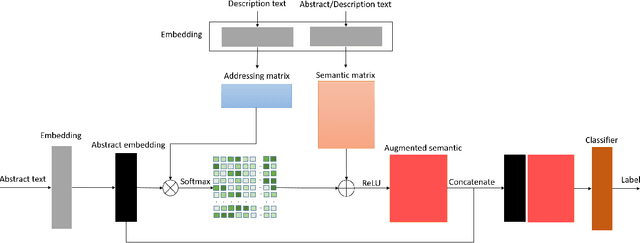
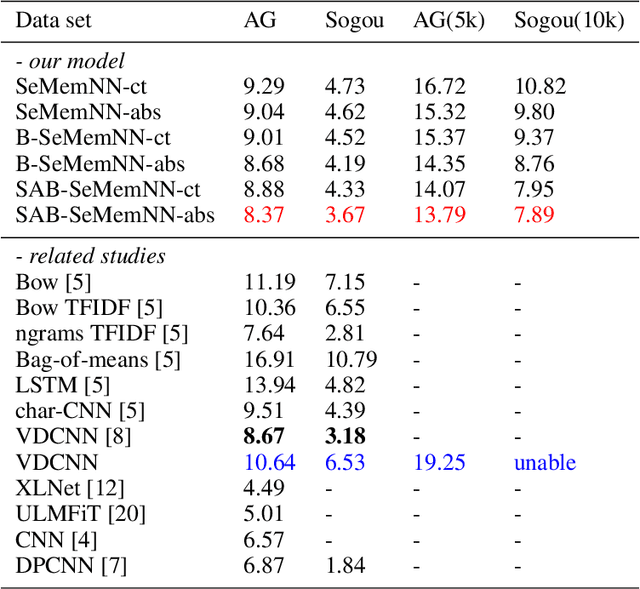
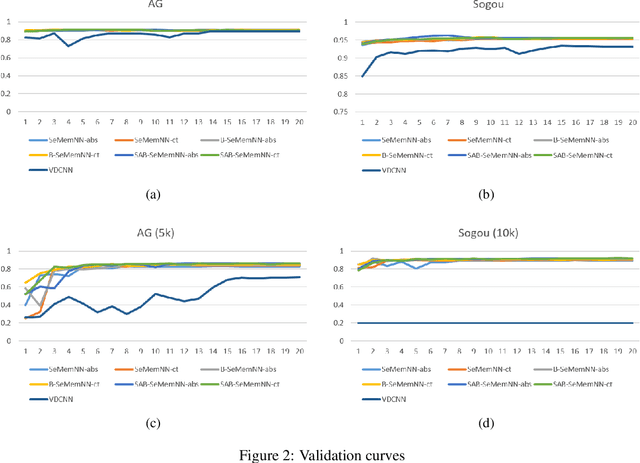
Text categorization is the task of assigning labels to documents written in a natural language, and it has numerous real-world applications including sentiment analysis as well as traditional topic assignment tasks. In this paper, we propose 5 different configurations for the semantic matrix-based memory neural network with end-to-end learning manner and evaluate our proposed method on two corpora of news articles (AG news, Sogou news). The best performance of our proposed method outperforms the baseline VDCNN models on the text classification task and gives a faster speed for learning semantics. Moreover, we also evaluate our model on small scale datasets. The results show that our proposed method can still achieve better results in comparison to VDCNN on the small scale dataset. This paper is to appear in the Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing (ICSC 2020), San Diego, California, 2020.
Intrinsically motivated reinforcement learning for human-robot interaction in the real-world
Apr 14, 2018
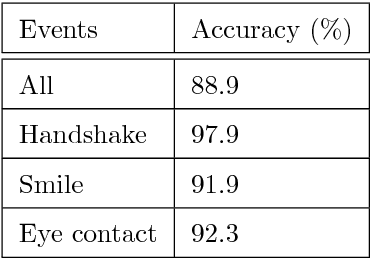
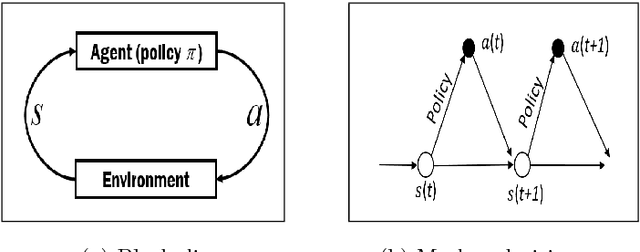

For a natural social human-robot interaction, it is essential for a robot to learn the human-like social skills. However, learning such skills is notoriously hard due to the limited availability of direct instructions from people to teach a robot. In this paper, we propose an intrinsically motivated reinforcement learning framework in which an agent gets the intrinsic motivation-based rewards through the action-conditional predictive model. By using the proposed method, the robot learned the social skills from the human-robot interaction experiences gathered in the real uncontrolled environments. The results indicate that the robot not only acquired human-like social skills but also took more human-like decisions, on a test dataset, than a robot which received direct rewards for the task achievement.