 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsically motivated reinforcement learning for human-robot interaction in the real-world
Apr 14, 2018
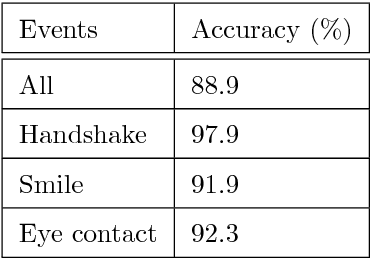
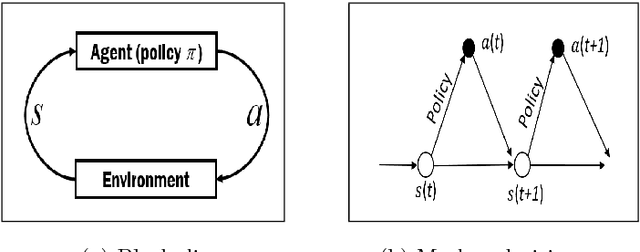

For a natural social human-robot interaction, it is essential for a robot to learn the human-like social skills. However, learning such skills is notoriously hard due to the limited availability of direct instructions from people to teach a robot. In this paper, we propose an intrinsically motivated reinforcement learning framework in which an agent gets the intrinsic motivation-based rewards through the action-conditional predictive model. By using the proposed method, the robot learned the social skills from the human-robot interaction experiences gathered in the real uncontrolled environments. The results indicate that the robot not only acquired human-like social skills but also took more human-like decisions, on a test dataset, than a robot which received direct rewards for the task achievement.
Potential Functions based Sampling Heuristic For Optimal Path Planning
Apr 02, 2017
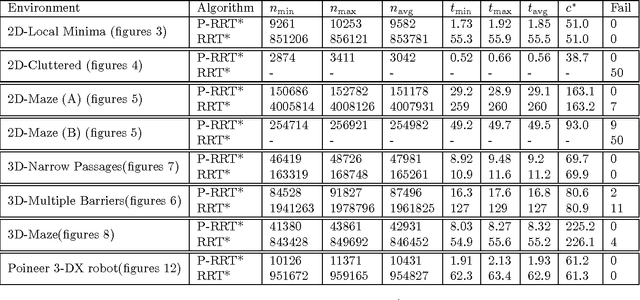


Rapidly-exploring Random Tree Star(RRT*) is a recently proposed extension of Rapidly-exploring Random Tree (RRT) algorithm that provides a collision-free, asymptotically optimal path regardless of obstacle's geometry in a given environment. However, one of the limitations in the RRT* algorithm is slow convergence to optimal path solution. As a result, it consumes high memory as well as time due to a large number of iterations utilised in achieving optimal path solution. To overcome these limitations, we propose the Potential Function Based-RRT* (P-RRT*) that incorporates the Artificial Potential Field Algorithm in RRT*. The proposed algorithm allows a considerable decrease in the number of iterations and thus leads to more efficient memory utilization and an accelerated convergence rate. In order to illustrate the usefulness of the proposed algorithm in terms of space execution and convergence rate, this paper presents rigorous simulation based comparisons between the proposed techniques and RRT* under different environmental conditions. Moreover, both algorithms are also tested and compared under non-holonomic differential constraints.
* This paper introduces a novel algorithm called P-RRT*. The work has been published in Springer Autonomous Robots Journal
Intelligent bidirectional rapidly-exploring random trees for optimal motion planning in complex cluttered environments
Mar 27, 2017
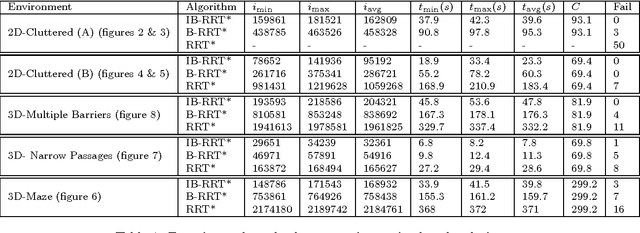


The sampling based motion planning algorithm known as Rapidly-exploring Random Trees (RRT) has gained the attention of many researchers due to their computational efficiency and effectiveness. Recently, a variant of RRT called RRT* has been proposed that ensures asymptotic optimality. Subsequently its bidirectional version has also been introduced in the literature known as Bidirectional-RRT* (B-RRT*). We introduce a new variant called Intelligent Bidirectional-RRT* (IB-RRT*) which is an improved variant of the optimal RRT* and bidirectional version of RRT* (B-RRT*) algorithms and is specially designed for complex cluttered environments. IB-RRT* utilizes the bidirectional trees approach and introduces intelligent sample insertion heuristic for fast convergence to the optimal path solution using uniform sampling heuristics. The proposed algorithm is evaluated theoretically and experimental results are presented that compares IB-RRT* with RRT* and B-RRT*. Moreover, experimental results demonstrate the superior efficiency of IB-RRT* in comparison with RRT* and B-RRT in complex cluttered environments.
* The article is published in Elsevier Journal of Robotics and Autonomous Systems
Show, Attend and Interact: Perceivable Human-Robot Social Interaction through Neural Attention Q-Network
Feb 28, 2017



For a safe, natural and effective human-robot social interaction, it is essential to develop a system that allows a robot to demonstrate the perceivable responsive behaviors to complex human behaviors. We introduce the Multimodal Deep Attention Recurrent Q-Network using which the robot exhibits human-like social interaction skills after 14 days of interacting with people in an uncontrolled real world. Each and every day during the 14 days, the system gathered robot interaction experiences with people through a hit-and-trial method and then trained the MDARQN on these experiences using end-to-end reinforcement learning approach. The results of interaction based learning indicate that the robot has learned to respond to complex human behaviors in a perceivable and socially acceptable manner.
Robot gains Social Intelligence through Multimodal Deep Reinforcement Learning
Feb 24, 2017
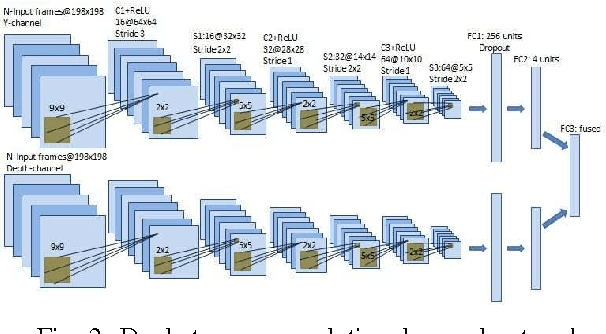

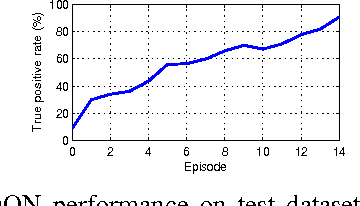
For robots to coexist with humans in a social world like ours, it is crucial that they possess human-like social interaction skills. Programming a robot to possess such skills is a challenging task. In this paper, we propose a Multimodal Deep Q-Network (MDQN) to enable a robot to learn human-like interaction skills through a trial and error method. This paper aims to develop a robot that gathers data during its interaction with a human and learns human interaction behaviour from the high-dimensional sensory information using end-to-end reinforcement learning. This paper demonstrates that the robot was able to learn basic interaction skills successfully, after 14 days of interacting with people.