 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Speaker-Independent Emotions for Voice Conversion Via Source-Filter Networks
Oct 04, 2021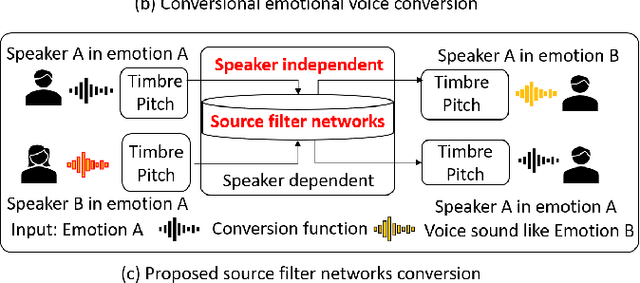
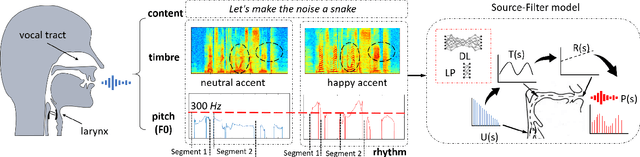
Emotional voice conversion (VC) aims to convert a neutral voice to an emotional (e.g. happy) one while retaining the linguistic information and speaker identity. We note that the decoupling of emotional features from other speech information (such as speaker, content, etc.) is the key to achieving remarkable performance. Some recent attempts about speech representation decoupling on the neutral speech can not work well on the emotional speech, due to the more complex acoustic properties involved in the latter. To address this problem, here we propose a novel Source-Filter-based Emotional VC model (SFEVC) to achieve proper filtering of speaker-independent emotion features from both the timbre and pitch features. Our SFEVC model consists of multi-channel encoders, emotion separate encoders, and one decoder. Note that all encoder modules adopt a designed information bottlenecks auto-encoder. Additionally, to further improve the conversion quality for various emotions, a novel two-stage training strategy based on the 2D Valence-Arousal (VA) space was proposed. Experimental results show that the proposed SFEVC along with a two-stage training strategy outperforms all baselines and achieves the state-of-the-art performance in speaker-independent emotional VC with nonparallel data.