 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral assessment of a humanoid robot when attracting pedestrians in a mall
Sep 06, 2021

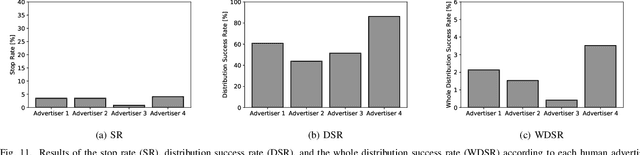
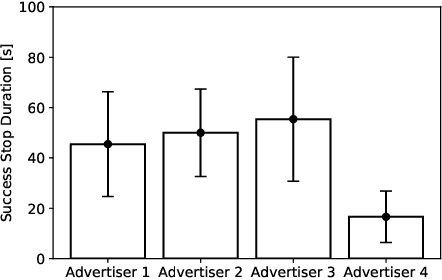
Research currently being conducted on the use of robots as human labor support technology. In particular, the service industry needs to allocate more manpower, and it will be important for robots to support people. This study focuses on using a humanoid robot as a social service robot to convey information in a shopping mall, and the robot's behavioral concepts were analyzed. In order to convey the information, two processes must occur. Pedestrians must stop in front of the robot, and the robot must continue the engagement with them. For the purpose of this study, three types of autonomous behavioral concepts of the robot for the general use were analyzed and compared in these processes in the experiment: active, passive-negative, and passive-positive concepts. After interactions were attempted with 65,000+ pedestrians, this study revealed that the passive-negative concept can make pedestrians stop more and stay longer. In order to evaluate the effectiveness of the robot in a real environment, the comparative results between three behaviors and human advertisers revealed that (1) the results of the active and passive-positive concepts of the robot are comparable to those of the humans, and (2) the performance of the passive-negative concept is higher than that of all participants. These findings demonstrate that the performance of robots is comparable to that of humans in providing information tasks in a limited environment; therefore, it is expected that service robots as a labor support technology will be able to perform well in the real world.
Homotopy Continuation Approaches for Robust SV Classification and Regression
Jul 12, 2015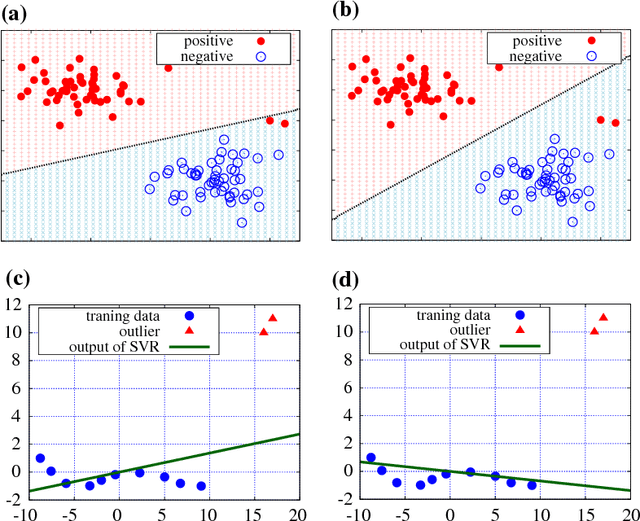
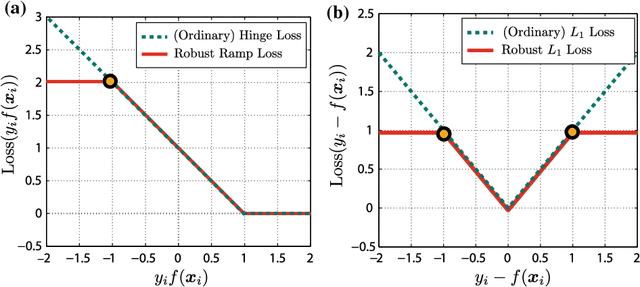
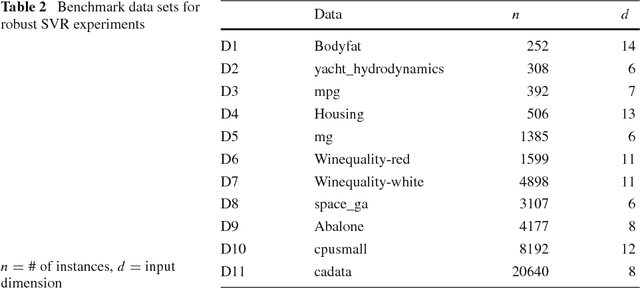
In support vector machine (SVM) applications with unreliable data that contains a portion of outliers, non-robustness of SVMs often causes considerable performance deterioration. Although many approaches for improving the robustness of SVMs have been studied, two major challenges remain in robust SVM learning. First, robust learning algorithms are essentially formulated as non-convex optimization problems. It is thus important to develop a non-convex optimization method for robust SVM that can find a good local optimal solution. The second practical issue is how one can tune the hyperparameter that controls the balance between robustness and efficiency. Unfortunately, due to the non-convexity, robust SVM solutions with slightly different hyper-parameter values can be significantly different, which makes model selection highly unstable. In this paper, we address these two issues simultaneously by introducing a novel homotopy approach to non-convex robust SVM learning. Our basic idea is to introduce parametrized formulations of robust SVM which bridge the standard SVM and fully robust SVM via the parameter that represents the influence of outliers. We characterize the necessary and sufficient conditions of the local optimal solutions of robust SVM, and develop an algorithm that can trace a path of local optimal solutions when the influence of outliers is gradually decreased. An advantage of our homotopy approach is that it can be interpreted as simulated annealing, a common approach for finding a good local optimal solution in non-convex optimization problems. In addition, our homotopy method allows stable and efficient model selection based on the path of local optimal solutions. Empirical performances of the proposed approach are demonstrated through intensive numerical experiments both on robust classification and regression problems.
An Algorithmic Framework for Computing Validation Performance Bounds by Using Suboptimal Models
Feb 10, 2014

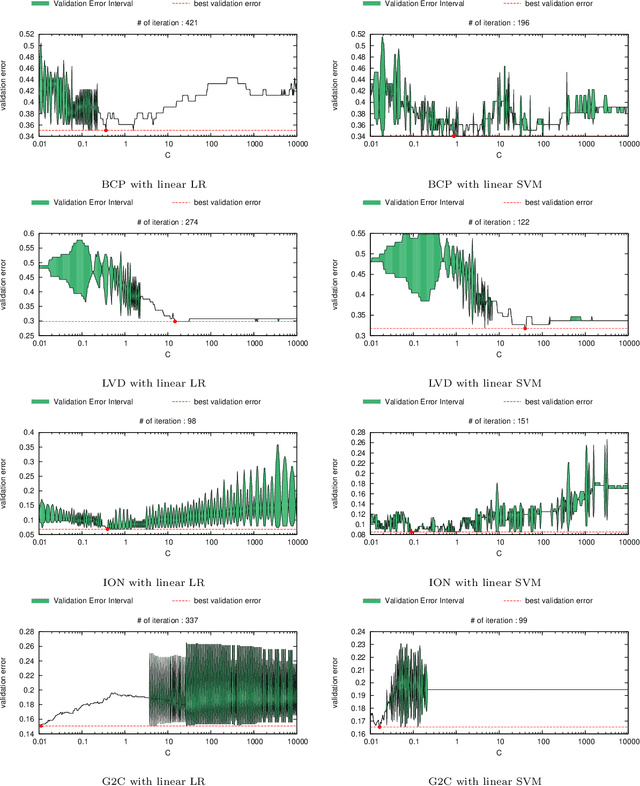
Practical model building processes are often time-consuming because many different models must be trained and validated. In this paper, we introduce a novel algorithm that can be used for computing the lower and the upper bounds of model validation errors without actually training the model itself. A key idea behind our algorithm is using a side information available from a suboptimal model. If a reasonably good suboptimal model is available, our algorithm can compute lower and upper bounds of many useful quantities for making inferences on the unknown target model. We demonstrate the advantage of our algorithm in the context of model selection for regularized learning problems.
Safe Sample Screening for Support Vector Machines
Jan 27, 2014
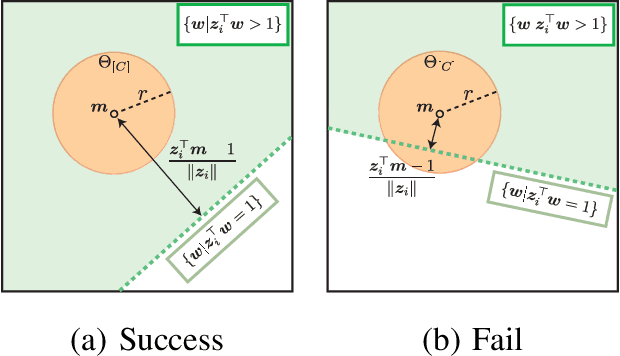

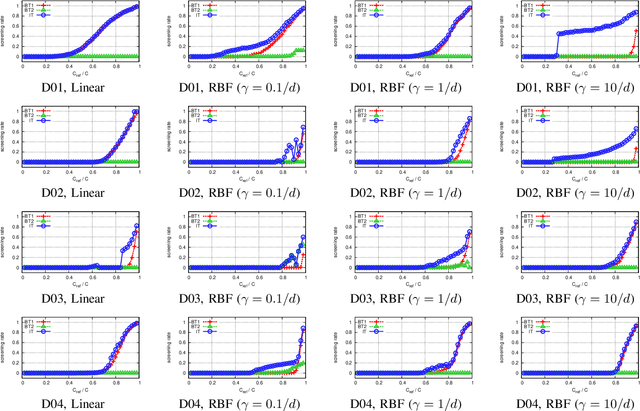
Sparse classifiers such as the support vector machines (SVM) are efficient in test-phases because the classifier is characterized only by a subset of the samples called support vectors (SVs), and the rest of the samples (non SVs) have no influence on the classification result. However, the advantage of the sparsity has not been fully exploited in training phases because it is generally difficult to know which sample turns out to be SV beforehand. In this paper, we introduce a new approach called safe sample screening that enables us to identify a subset of the non-SVs and screen them out prior to the training phase. Our approach is different from existing heuristic approaches in the sense that the screened samples are guaranteed to be non-SVs at the optimal solution. We investigate the advantage of the safe sample screening approach through intensive numerical experiments, and demonstrate that it can substantially decrease the computational cost of the state-of-the-art SVM solvers such as LIBSVM. In the current big data era, we believe that safe sample screening would be of great practical importance since the data size can be reduced without sacrificing the optimality of the final solution.