 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization Path of Cross-Validation Error Lower Bounds
Jun 22, 2015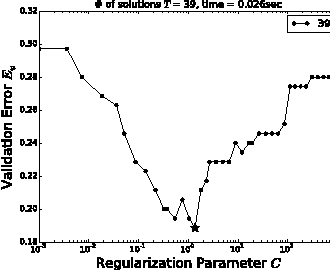
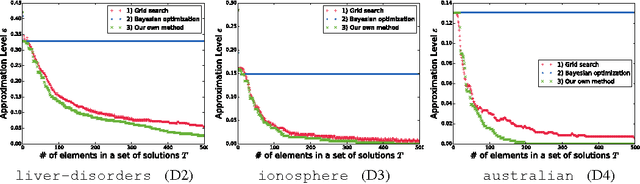

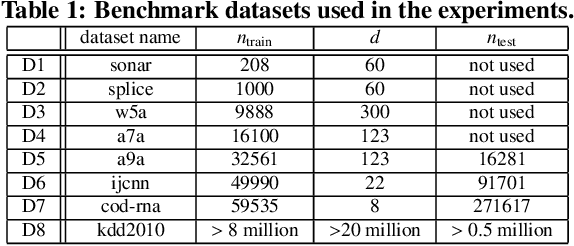
Careful tuning of a regularization parameter is indispensable in many machine learning tasks because it has a significant impact on generalization performances. Nevertheless, current practice of regularization parameter tuning is more of an art than a science, e.g., it is hard to tell how many grid-points would be needed in cross-validation (CV) for obtaining a solution with sufficiently small CV error. In this paper we propose a novel framework for computing a lower bound of the CV errors as a function of the regularization parameter, which we call regularization path of CV error lower bounds. The proposed framework can be used for providing a theoretical approximation guarantee on a set of solutions in the sense that how far the CV error of the current best solution could be away from best possible CV error in the entire range of the regularization parameters. We demonstrate through numerical experiments that a theoretically guaranteed a choice of regularization parameter in the above sense is possible with reasonable computational costs.
Quick sensitivity analysis for incremental data modification and its application to leave-one-out CV in linear classification problems
Apr 11, 2015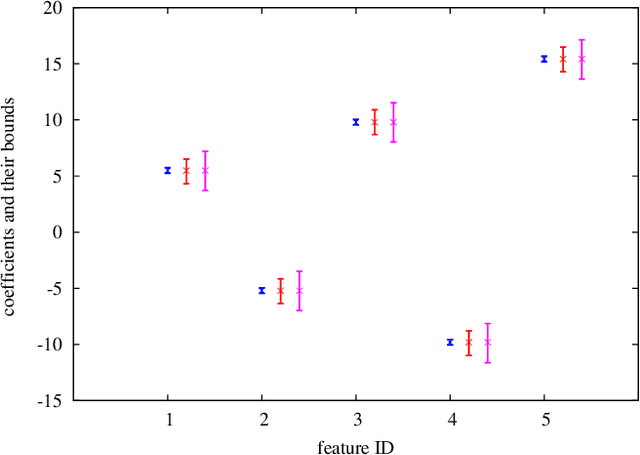
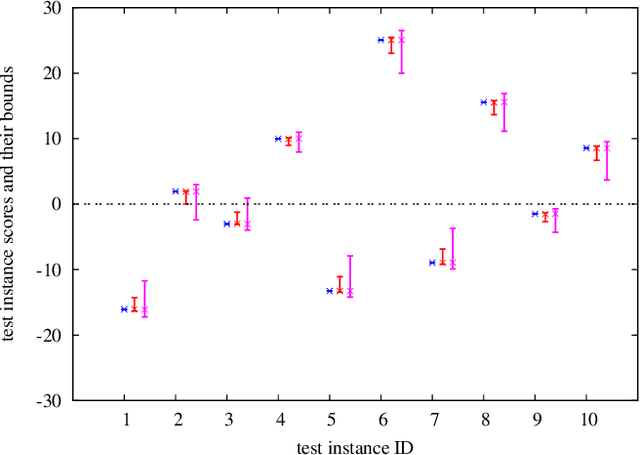

We introduce a novel sensitivity analysis framework for large scale classification problems that can be used when a small number of instances are incrementally added or removed. For quickly updating the classifier in such a situation, incremental learning algorithms have been intensively studied in the literature. Although they are much more efficient than solving the optimization problem from scratch, their computational complexity yet depends on the entire training set size. It means that, if the original training set is large, completely solving an incremental learning problem might be still rather expensive. To circumvent this computational issue, we propose a novel framework that allows us to make an inference about the updated classifier without actually re-optimizing it. Specifically, the proposed framework can quickly provide a lower and an upper bounds of a quantity on the unknown updated classifier. The main advantage of the proposed framework is that the computational cost of computing these bounds depends only on the number of updated instances. This property is quite advantageous in a typical sensitivity analysis task where only a small number of instances are updated. In this paper we demonstrate that the proposed framework is applicable to various practical sensitivity analysis tasks, and the bounds provided by the framework are often sufficiently tight for making desired inferences.
An Algorithmic Framework for Computing Validation Performance Bounds by Using Suboptimal Models
Feb 10, 2014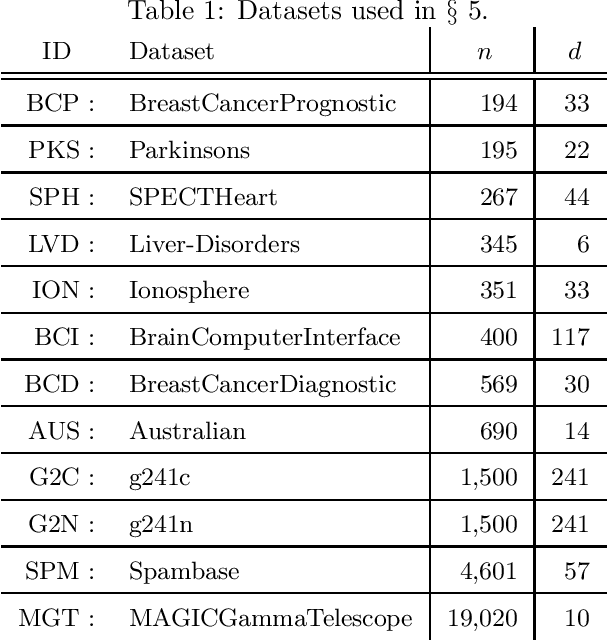
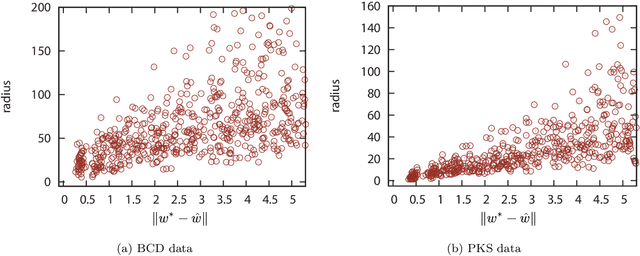

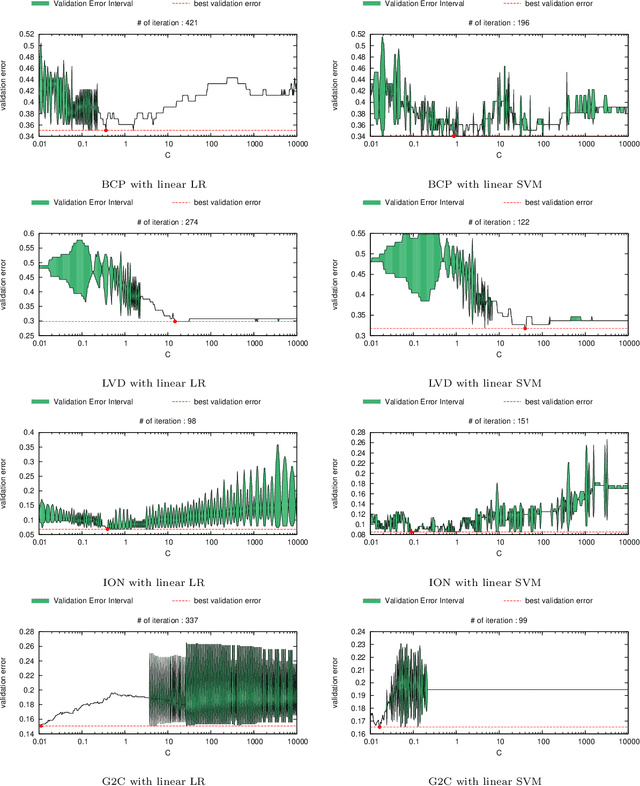
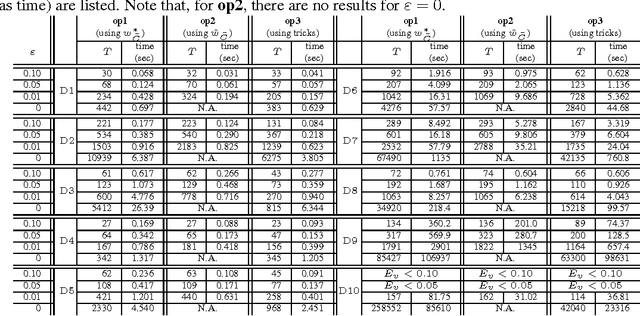
Practical model building processes are often time-consuming because many different models must be trained and validated. In this paper, we introduce a novel algorithm that can be used for computing the lower and the upper bounds of model validation errors without actually training the model itself. A key idea behind our algorithm is using a side information available from a suboptimal model. If a reasonably good suboptimal model is available, our algorithm can compute lower and upper bounds of many useful quantities for making inferences on the unknown target model. We demonstrate the advantage of our algorithm in the context of model selection for regularized learning problems.
Safe Sample Screening for Support Vector Machines
Jan 27, 2014
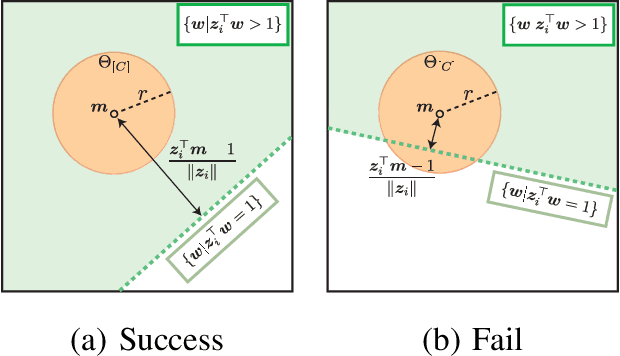

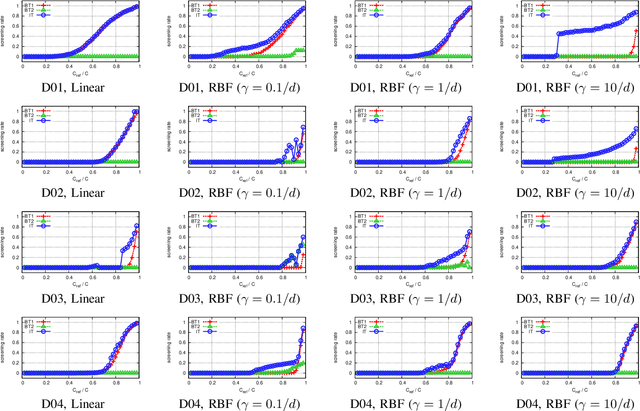
Sparse classifiers such as the support vector machines (SVM) are efficient in test-phases because the classifier is characterized only by a subset of the samples called support vectors (SVs), and the rest of the samples (non SVs) have no influence on the classification result. However, the advantage of the sparsity has not been fully exploited in training phases because it is generally difficult to know which sample turns out to be SV beforehand. In this paper, we introduce a new approach called safe sample screening that enables us to identify a subset of the non-SVs and screen them out prior to the training phase. Our approach is different from existing heuristic approaches in the sense that the screened samples are guaranteed to be non-SVs at the optimal solution. We investigate the advantage of the safe sample screening approach through intensive numerical experiments, and demonstrate that it can substantially decrease the computational cost of the state-of-the-art SVM solvers such as LIBSVM. In the current big data era, we believe that safe sample screening would be of great practical importance since the data size can be reduced without sacrificing the optimality of the final solution.