 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Sample Screening for Support Vector Machines
Paper and Code
Jan 27, 2014
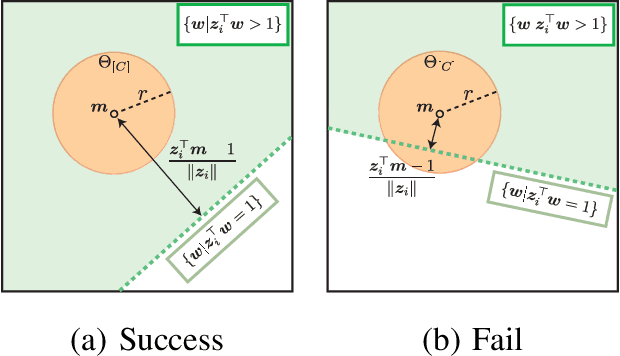

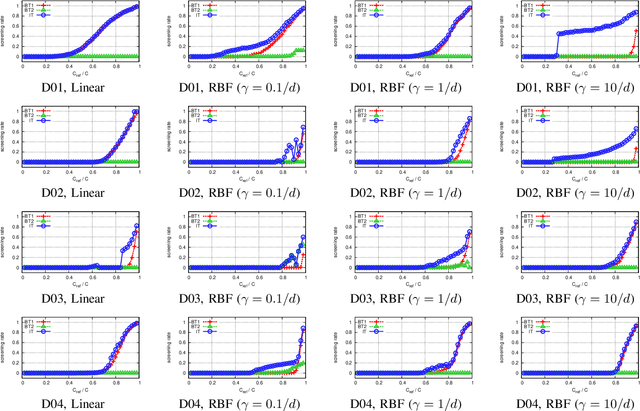
Sparse classifiers such as the support vector machines (SVM) are efficient in test-phases because the classifier is characterized only by a subset of the samples called support vectors (SVs), and the rest of the samples (non SVs) have no influence on the classification result. However, the advantage of the sparsity has not been fully exploited in training phases because it is generally difficult to know which sample turns out to be SV beforehand. In this paper, we introduce a new approach called safe sample screening that enables us to identify a subset of the non-SVs and screen them out prior to the training phase. Our approach is different from existing heuristic approaches in the sense that the screened samples are guaranteed to be non-SVs at the optimal solution. We investigate the advantage of the safe sample screening approach through intensive numerical experiments, and demonstrate that it can substantially decrease the computational cost of the state-of-the-art SVM solvers such as LIBSVM. In the current big data era, we believe that safe sample screening would be of great practical importance since the data size can be reduced without sacrificing the optimality of the final solution.