 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Selection Bias Issue for Online Advertising
Jun 07, 2022
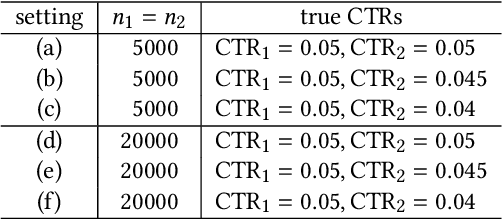
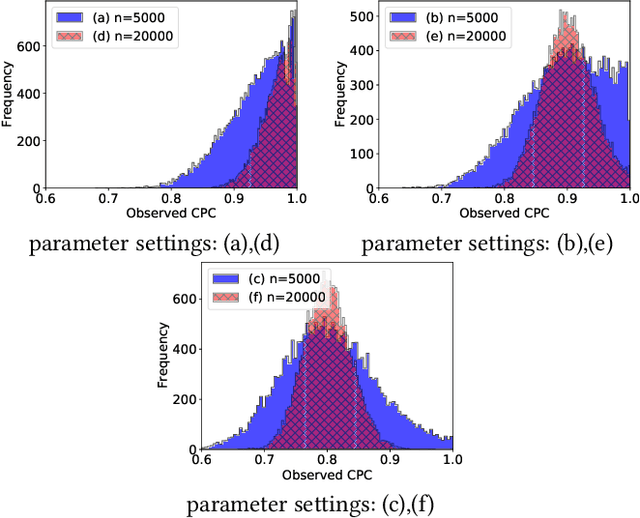
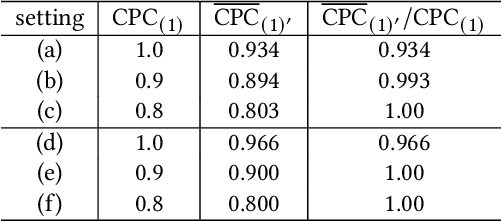
In online advertising, a set of potential advertisements can be ranked by a certain auction system where usually the top-1 advertisement would be selected and displayed at an advertising space. In this paper, we show a selection bias issue that is present in an auction system. We analyze that the selection bias destroy truthfulness of the auction, which implies that the buyers (advertisers) on the auction can not maximize their profits. Although selection bias is well known in the field of statistics and there are lot of studies for it, our main contribution is to combine the theoretical analysis of the bias with the auction mechanism. In our experiment using online A/B testing, we evaluate the selection bias on an auction system whose ranking score is the function of predicted CTR (click through rate) of advertisement. The experiment showed that the selection bias is drastically reduced by using a multi-task learning which learns the data for all advertisements.
Selective Inference Approach for Statistically Sound Predictive Pattern Mining
Mar 09, 2016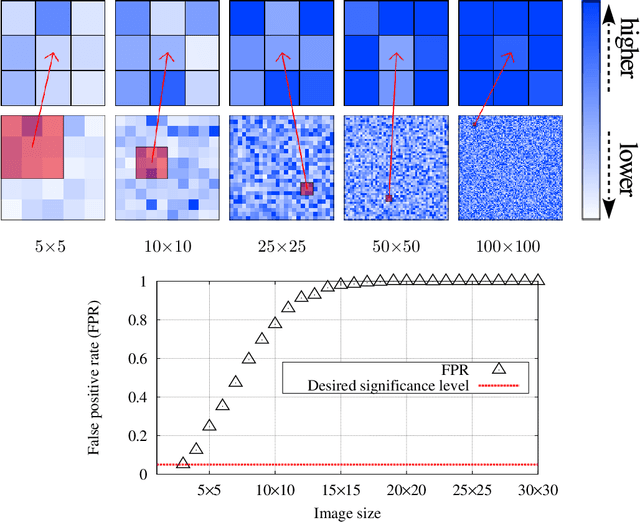
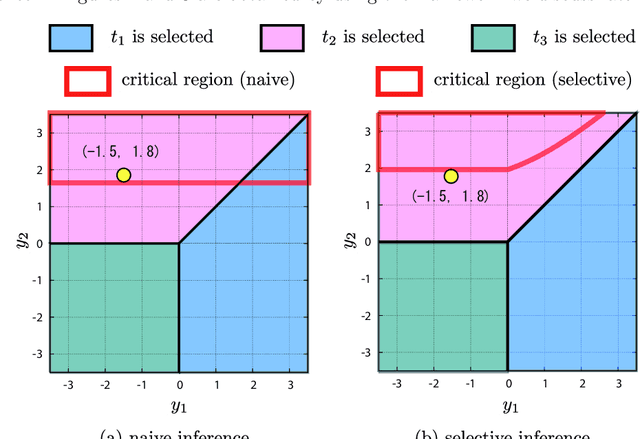
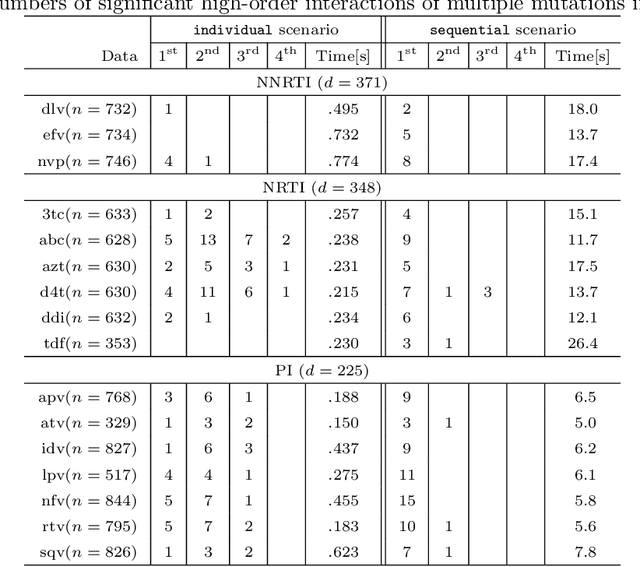
Discovering statistically significant patterns from databases is an important challenging problem. The main obstacle of this problem is in the difficulty of taking into account the selection bias, i.e., the bias arising from the fact that patterns are selected from extremely large number of candidates in databases. In this paper, we introduce a new approach for predictive pattern mining problems that can address the selection bias issue. Our approach is built on a recently popularized statistical inference framework called selective inference. In selective inference, statistical inferences (such as statistical hypothesis testing) are conducted based on sampling distributions conditional on a selection event. If the selection event is characterized in a tractable way, statistical inferences can be made without minding selection bias issue. However, in pattern mining problems, it is difficult to characterize the entire selection process of mining algorithms. Our main contribution in this paper is to solve this challenging problem for a class of predictive pattern mining problems by introducing a novel algorithmic framework. We demonstrate that our approach is useful for finding statistically significant patterns from databases.
Safe Pattern Pruning: An Efficient Approach for Predictive Pattern Mining
Feb 15, 2016


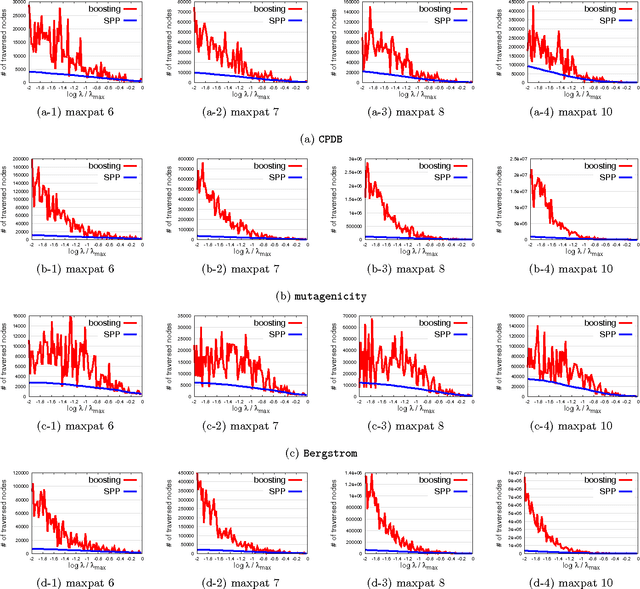
In this paper we study predictive pattern mining problems where the goal is to construct a predictive model based on a subset of predictive patterns in the database. Our main contribution is to introduce a novel method called safe pattern pruning (SPP) for a class of predictive pattern mining problems. The SPP method allows us to efficiently find a superset of all the predictive patterns in the database that are needed for the optimal predictive model. The advantage of the SPP method over existing boosting-type method is that the former can find the superset by a single search over the database, while the latter requires multiple searches. The SPP method is inspired by recent development of safe feature screening. In order to extend the idea of safe feature screening into predictive pattern mining, we derive a novel pruning rule called safe pattern pruning (SPP) rule that can be used for searching over the tree defined among patterns in the database. The SPP rule has a property that, if a node corresponding to a pattern in the database is pruned out by the SPP rule, then it is guaranteed that all the patterns corresponding to its descendant nodes are never needed for the optimal predictive model. We apply the SPP method to graph mining and item-set mining problems, and demonstrate its computational advantage.
Homotopy Continuation Approaches for Robust SV Classification and Regression
Jul 12, 2015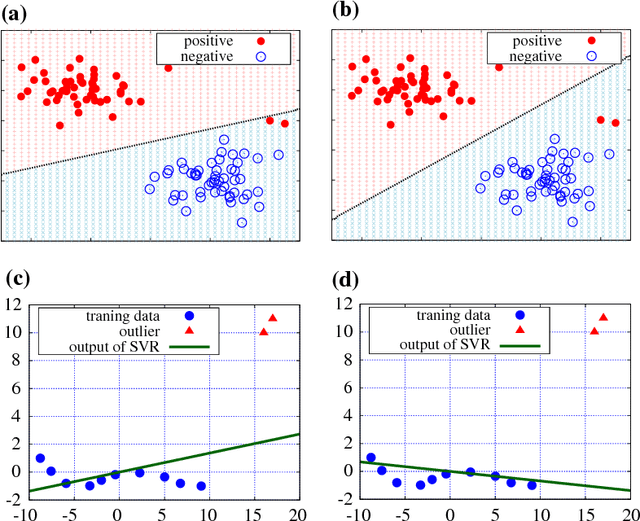
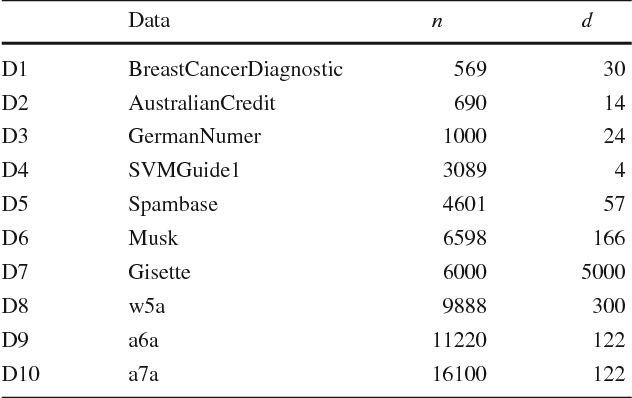
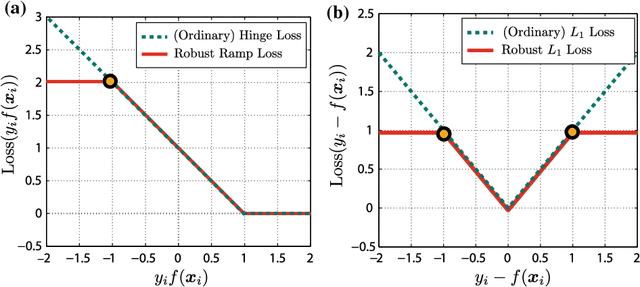
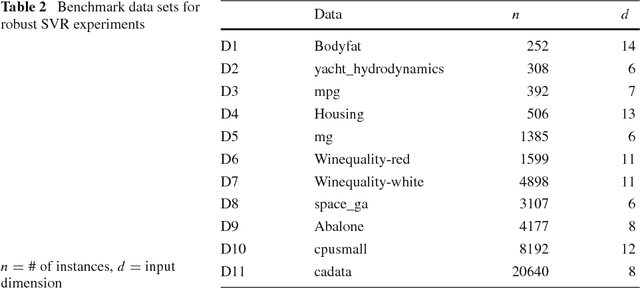
In support vector machine (SVM) applications with unreliable data that contains a portion of outliers, non-robustness of SVMs often causes considerable performance deterioration. Although many approaches for improving the robustness of SVMs have been studied, two major challenges remain in robust SVM learning. First, robust learning algorithms are essentially formulated as non-convex optimization problems. It is thus important to develop a non-convex optimization method for robust SVM that can find a good local optimal solution. The second practical issue is how one can tune the hyperparameter that controls the balance between robustness and efficiency. Unfortunately, due to the non-convexity, robust SVM solutions with slightly different hyper-parameter values can be significantly different, which makes model selection highly unstable. In this paper, we address these two issues simultaneously by introducing a novel homotopy approach to non-convex robust SVM learning. Our basic idea is to introduce parametrized formulations of robust SVM which bridge the standard SVM and fully robust SVM via the parameter that represents the influence of outliers. We characterize the necessary and sufficient conditions of the local optimal solutions of robust SVM, and develop an algorithm that can trace a path of local optimal solutions when the influence of outliers is gradually decreased. An advantage of our homotopy approach is that it can be interpreted as simulated annealing, a common approach for finding a good local optimal solution in non-convex optimization problems. In addition, our homotopy method allows stable and efficient model selection based on the path of local optimal solutions. Empirical performances of the proposed approach are demonstrated through intensive numerical experiments both on robust classification and regression problems.
Safe Feature Pruning for Sparse High-Order Interaction Models
Jun 26, 2015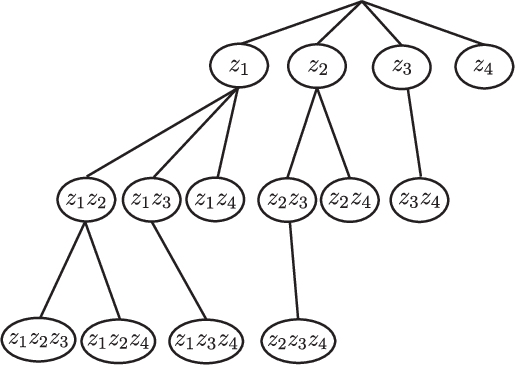


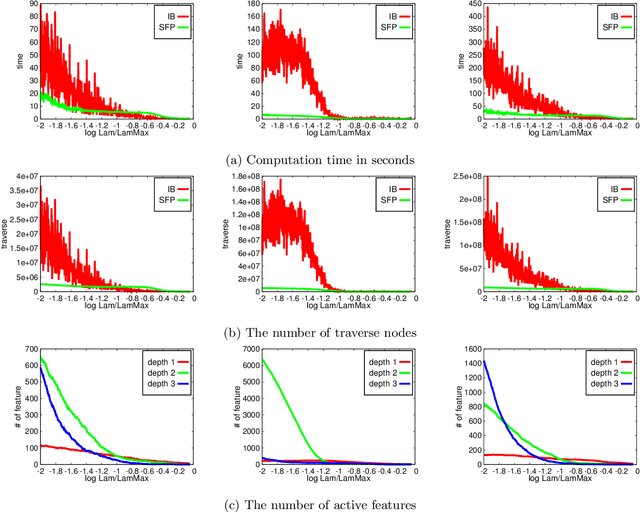
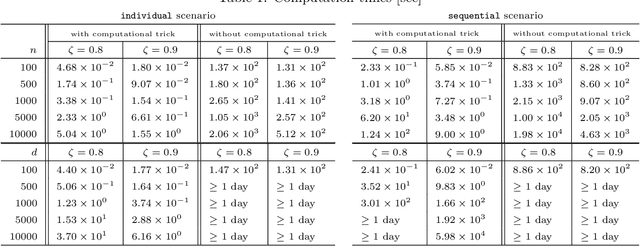
Taking into account high-order interactions among covariates is valuable in many practical regression problems. This is, however, computationally challenging task because the number of high-order interaction features to be considered would be extremely large unless the number of covariates is sufficiently small. In this paper, we propose a novel efficient algorithm for LASSO-based sparse learning of such high-order interaction models. Our basic strategy for reducing the number of features is to employ the idea of recently proposed safe feature screening (SFS) rule. An SFS rule has a property that, if a feature satisfies the rule, then the feature is guaranteed to be non-active in the LASSO solution, meaning that it can be safely screened-out prior to the LASSO training process. If a large number of features can be screened-out before training the LASSO, the computational cost and the memory requirment can be dramatically reduced. However, applying such an SFS rule to each of the extremely large number of high-order interaction features would be computationally infeasible. Our key idea for solving this computational issue is to exploit the underlying tree structure among high-order interaction features. Specifically, we introduce a pruning condition called safe feature pruning (SFP) rule which has a property that, if the rule is satisfied in a certain node of the tree, then all the high-order interaction features corresponding to its descendant nodes can be guaranteed to be non-active at the optimal solution. Our algorithm is extremely efficient, making it possible to work, e.g., with 3rd order interactions of 10,000 original covariates, where the number of possible high-order interaction features is greater than 10^{12}.
Safe Sample Screening for Support Vector Machines
Jan 27, 2014
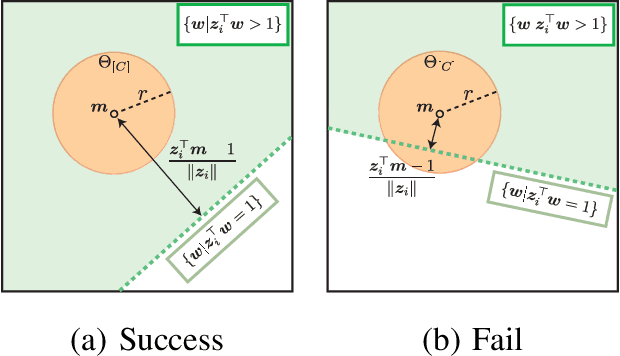

Sparse classifiers such as the support vector machines (SVM) are efficient in test-phases because the classifier is characterized only by a subset of the samples called support vectors (SVs), and the rest of the samples (non SVs) have no influence on the classification result. However, the advantage of the sparsity has not been fully exploited in training phases because it is generally difficult to know which sample turns out to be SV beforehand. In this paper, we introduce a new approach called safe sample screening that enables us to identify a subset of the non-SVs and screen them out prior to the training phase. Our approach is different from existing heuristic approaches in the sense that the screened samples are guaranteed to be non-SVs at the optimal solution. We investigate the advantage of the safe sample screening approach through intensive numerical experiments, and demonstrate that it can substantially decrease the computational cost of the state-of-the-art SVM solvers such as LIBSVM. In the current big data era, we believe that safe sample screening would be of great practical importance since the data size can be reduced without sacrificing the optimality of the final solution.