 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Inference Approach for Statistically Sound Predictive Pattern Mining
Paper and Code
Mar 09, 2016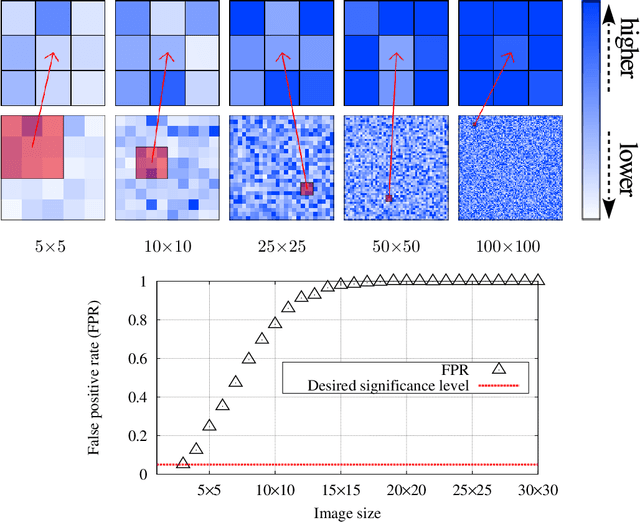
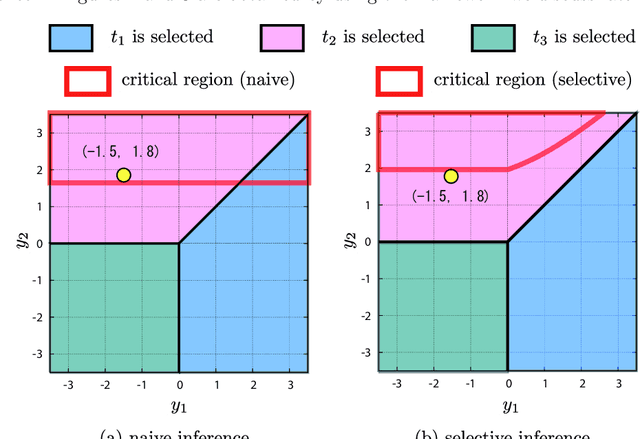
Discovering statistically significant patterns from databases is an important challenging problem. The main obstacle of this problem is in the difficulty of taking into account the selection bias, i.e., the bias arising from the fact that patterns are selected from extremely large number of candidates in databases. In this paper, we introduce a new approach for predictive pattern mining problems that can address the selection bias issue. Our approach is built on a recently popularized statistical inference framework called selective inference. In selective inference, statistical inferences (such as statistical hypothesis testing) are conducted based on sampling distributions conditional on a selection event. If the selection event is characterized in a tractable way, statistical inferences can be made without minding selection bias issue. However, in pattern mining problems, it is difficult to characterize the entire selection process of mining algorithms. Our main contribution in this paper is to solve this challenging problem for a class of predictive pattern mining problems by introducing a novel algorithmic framework. We demonstrate that our approach is useful for finding statistically significant patterns from databases.