 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Model Selection for Predictive Pattern Mining Model by Safe Pattern Pruning
Jun 23, 2023



Predictive pattern mining is an approach used to construct prediction models when the input is represented by structured data, such as sets, graphs, and sequences. The main idea behind predictive pattern mining is to build a prediction model by considering substructures, such as subsets, subgraphs, and subsequences (referred to as patterns), present in the structured data as features of the model. The primary challenge in predictive pattern mining lies in the exponential growth of the number of patterns with the complexity of the structured data. In this study, we propose the Safe Pattern Pruning (SPP) method to address the explosion of pattern numbers in predictive pattern mining. We also discuss how it can be effectively employed throughout the entire model building process in practical data analysis. To demonstrate the effectiveness of the proposed method, we conduct numerical experiments on regression and classification problems involving sets, graphs, and sequences.
Selective Inference Approach for Statistically Sound Predictive Pattern Mining
Mar 09, 2016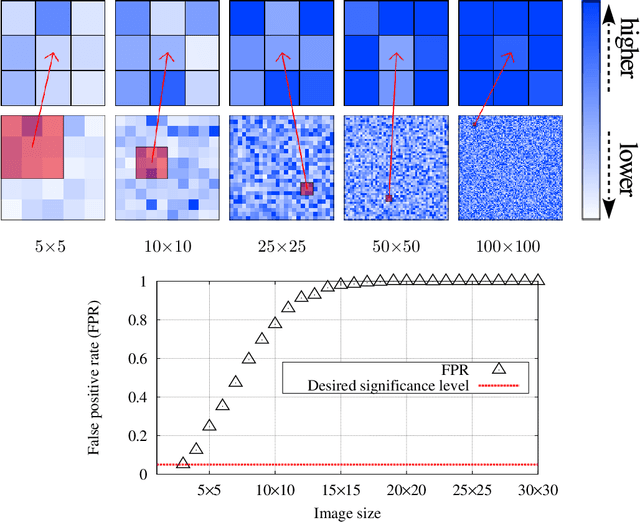
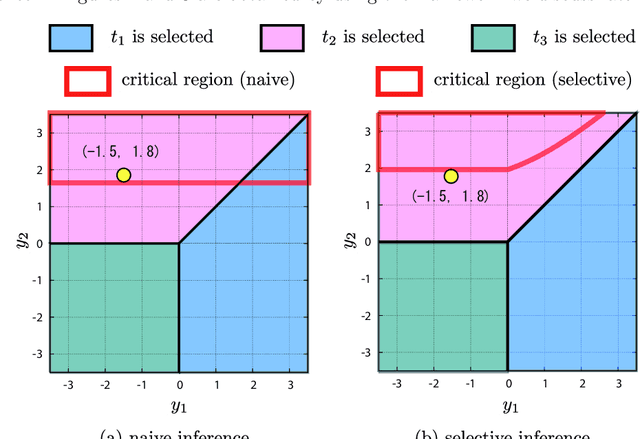
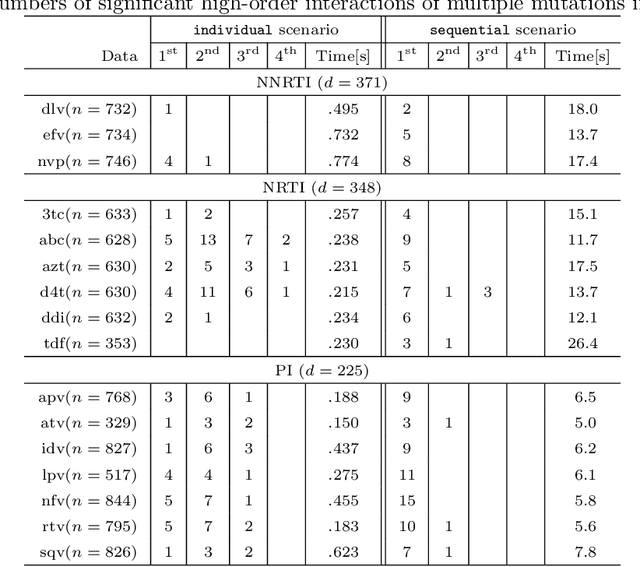
Discovering statistically significant patterns from databases is an important challenging problem. The main obstacle of this problem is in the difficulty of taking into account the selection bias, i.e., the bias arising from the fact that patterns are selected from extremely large number of candidates in databases. In this paper, we introduce a new approach for predictive pattern mining problems that can address the selection bias issue. Our approach is built on a recently popularized statistical inference framework called selective inference. In selective inference, statistical inferences (such as statistical hypothesis testing) are conducted based on sampling distributions conditional on a selection event. If the selection event is characterized in a tractable way, statistical inferences can be made without minding selection bias issue. However, in pattern mining problems, it is difficult to characterize the entire selection process of mining algorithms. Our main contribution in this paper is to solve this challenging problem for a class of predictive pattern mining problems by introducing a novel algorithmic framework. We demonstrate that our approach is useful for finding statistically significant patterns from databases.
Safe Pattern Pruning: An Efficient Approach for Predictive Pattern Mining
Feb 15, 2016


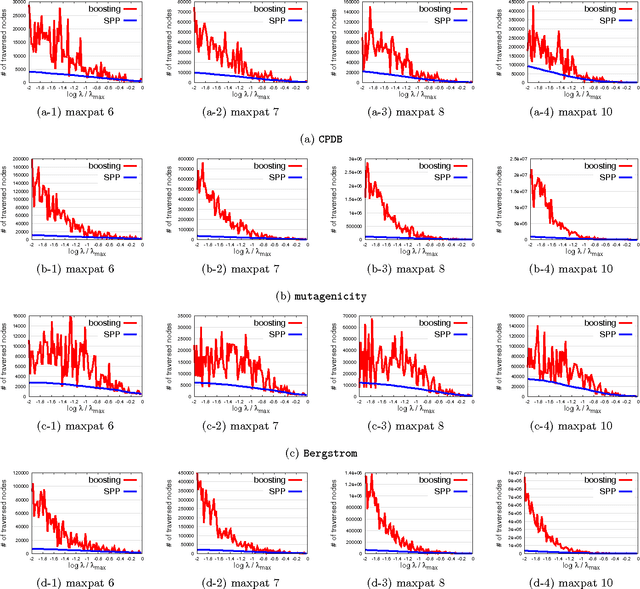
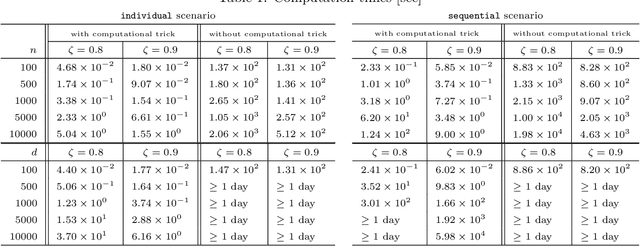
In this paper we study predictive pattern mining problems where the goal is to construct a predictive model based on a subset of predictive patterns in the database. Our main contribution is to introduce a novel method called safe pattern pruning (SPP) for a class of predictive pattern mining problems. The SPP method allows us to efficiently find a superset of all the predictive patterns in the database that are needed for the optimal predictive model. The advantage of the SPP method over existing boosting-type method is that the former can find the superset by a single search over the database, while the latter requires multiple searches. The SPP method is inspired by recent development of safe feature screening. In order to extend the idea of safe feature screening into predictive pattern mining, we derive a novel pruning rule called safe pattern pruning (SPP) rule that can be used for searching over the tree defined among patterns in the database. The SPP rule has a property that, if a node corresponding to a pattern in the database is pruned out by the SPP rule, then it is guaranteed that all the patterns corresponding to its descendant nodes are never needed for the optimal predictive model. We apply the SPP method to graph mining and item-set mining problems, and demonstrate its computational advantage.
Safe Feature Pruning for Sparse High-Order Interaction Models
Jun 26, 2015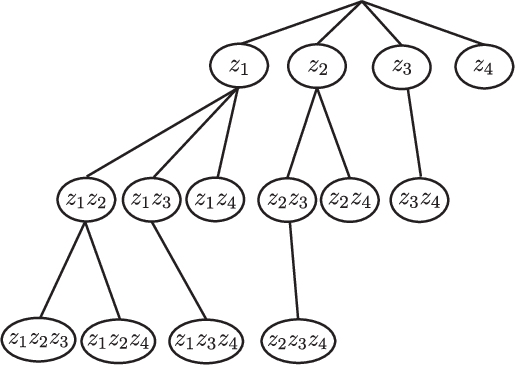


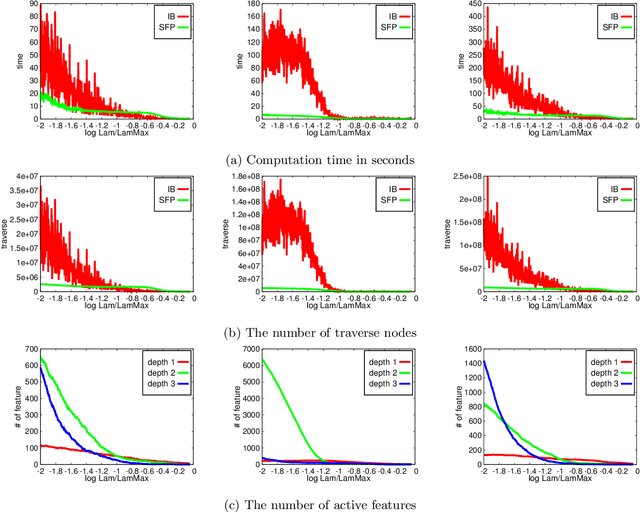
Taking into account high-order interactions among covariates is valuable in many practical regression problems. This is, however, computationally challenging task because the number of high-order interaction features to be considered would be extremely large unless the number of covariates is sufficiently small. In this paper, we propose a novel efficient algorithm for LASSO-based sparse learning of such high-order interaction models. Our basic strategy for reducing the number of features is to employ the idea of recently proposed safe feature screening (SFS) rule. An SFS rule has a property that, if a feature satisfies the rule, then the feature is guaranteed to be non-active in the LASSO solution, meaning that it can be safely screened-out prior to the LASSO training process. If a large number of features can be screened-out before training the LASSO, the computational cost and the memory requirment can be dramatically reduced. However, applying such an SFS rule to each of the extremely large number of high-order interaction features would be computationally infeasible. Our key idea for solving this computational issue is to exploit the underlying tree structure among high-order interaction features. Specifically, we introduce a pruning condition called safe feature pruning (SFP) rule which has a property that, if the rule is satisfied in a certain node of the tree, then all the high-order interaction features corresponding to its descendant nodes can be guaranteed to be non-active at the optimal solution. Our algorithm is extremely efficient, making it possible to work, e.g., with 3rd order interactions of 10,000 original covariates, where the number of possible high-order interaction features is greater than 10^{12}.