Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Algorithmic Framework for Computing Validation Performance Bounds by Using Suboptimal Models
Feb 10, 2014
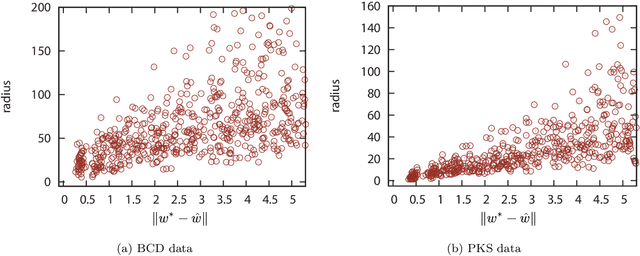

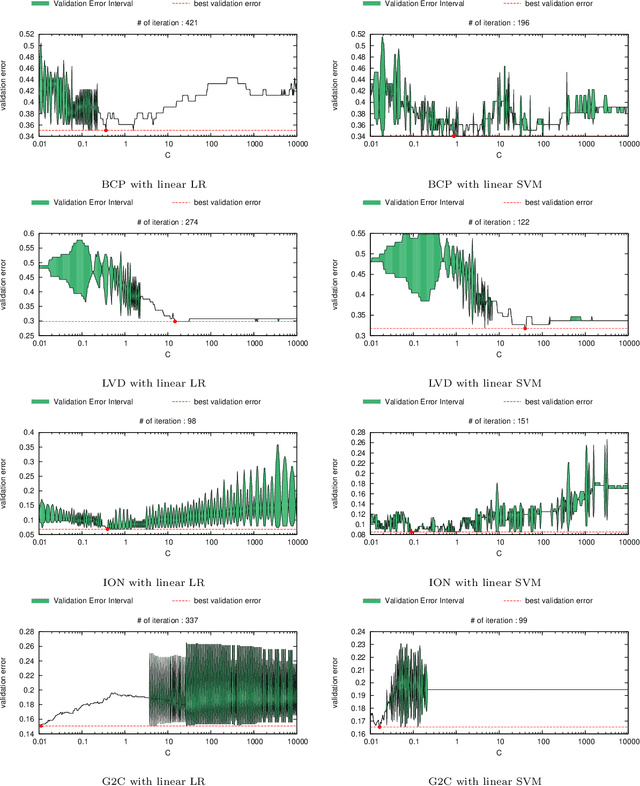
Practical model building processes are often time-consuming because many different models must be trained and validated. In this paper, we introduce a novel algorithm that can be used for computing the lower and the upper bounds of model validation errors without actually training the model itself. A key idea behind our algorithm is using a side information available from a suboptimal model. If a reasonably good suboptimal model is available, our algorithm can compute lower and upper bounds of many useful quantities for making inferences on the unknown target model. We demonstrate the advantage of our algorithm in the context of model selection for regularized learning problems.
Via