 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Reader: Reconstructing complex images from brain activities
Sep 30, 2022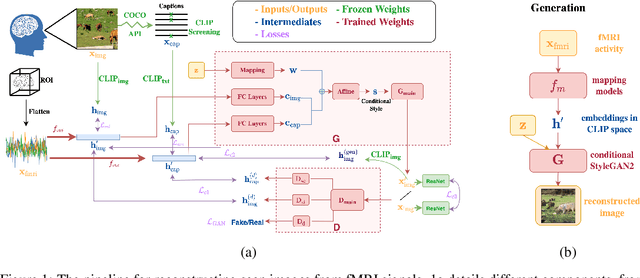


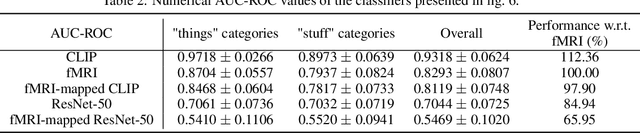
Understanding how the brain encodes external stimuli and how these stimuli can be decoded from the measured brain activities are long-standing and challenging questions in neuroscience. In this paper, we focus on reconstructing the complex image stimuli from fMRI (functional magnetic resonance imaging) signals. Unlike previous works that reconstruct images with single objects or simple shapes, our work aims to reconstruct image stimuli that are rich in semantics, closer to everyday scenes, and can reveal more perspectives. However, data scarcity of fMRI datasets is the main obstacle to applying state-of-the-art deep learning models to this problem. We find that incorporating an additional text modality is beneficial for the reconstruction problem compared to directly translating brain signals to images. Therefore, the modalities involved in our method are: (i) voxel-level fMRI signals, (ii) observed images that trigger the brain signals, and (iii) textual description of the images. To further address data scarcity, we leverage an aligned vision-language latent space pre-trained on massive datasets. Instead of training models from scratch to find a latent space shared by the three modalities, we encode fMRI signals into this pre-aligned latent space. Then, conditioned on embeddings in this space, we reconstruct images with a generative model. The reconstructed images from our pipeline balance both naturalness and fidelity: they are photo-realistic and capture the ground truth image contents well.
SplitMixer: Fat Trimmed From MLP-like Models
Jul 25, 2022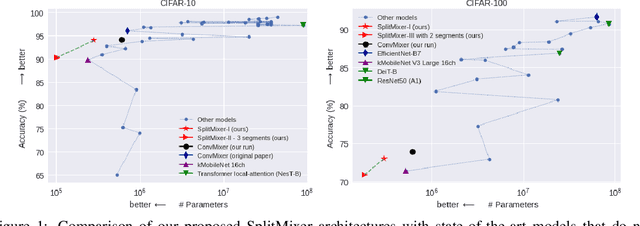
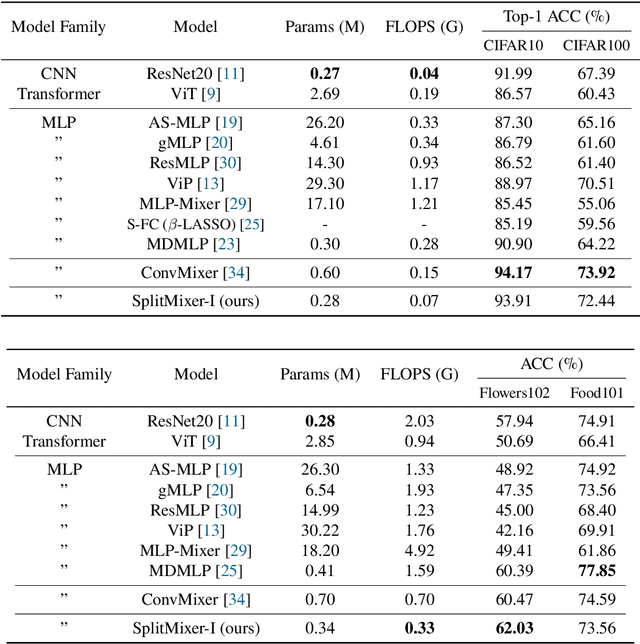
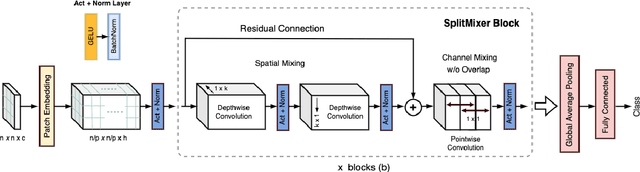
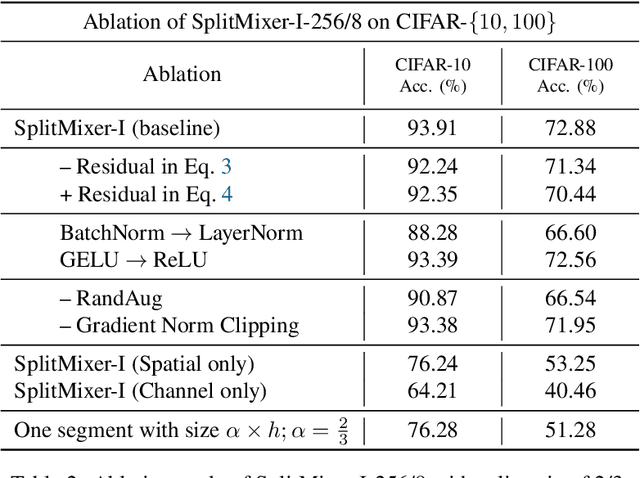
We present SplitMixer, a simple and lightweight isotropic MLP-like architecture, for visual recognition. It contains two types of interleaving convolutional operations to mix information across spatial locations (spatial mixing) and channels (channel mixing). The first one includes sequentially applying two depthwise 1D kernels, instead of a 2D kernel, to mix spatial information. The second one is splitting the channels into overlapping or non-overlapping segments, with or without shared parameters, and applying our proposed channel mixing approaches or 3D convolution to mix channel information. Depending on design choices, a number of SplitMixer variants can be constructed to balance accuracy, the number of parameters, and speed. We show, both theoretically and experimentally, that SplitMixer performs on par with the state-of-the-art MLP-like models while having a significantly lower number of parameters and FLOPS. For example, without strong data augmentation and optimization, SplitMixer achieves around 94% accuracy on CIFAR-10 with only 0.28M parameters, while ConvMixer achieves the same accuracy with about 0.6M parameters. The well-known MLP-Mixer achieves 85.45% with 17.1M parameters. On CIFAR-100 dataset, SplitMixer achieves around 73% accuracy, on par with ConvMixer, but with about 52% fewer parameters and FLOPS. We hope that our results spark further research towards finding more efficient vision architectures and facilitate the development of MLP-like models. Code is available at https://github.com/aliborji/splitmixer.
Deep Representations for Time-varying Brain Datasets
May 23, 2022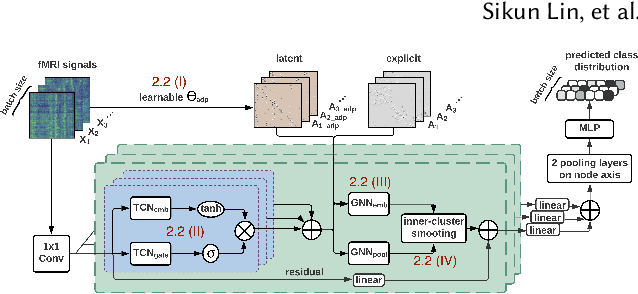

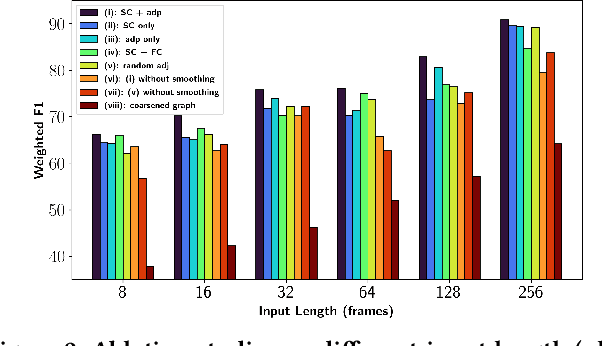
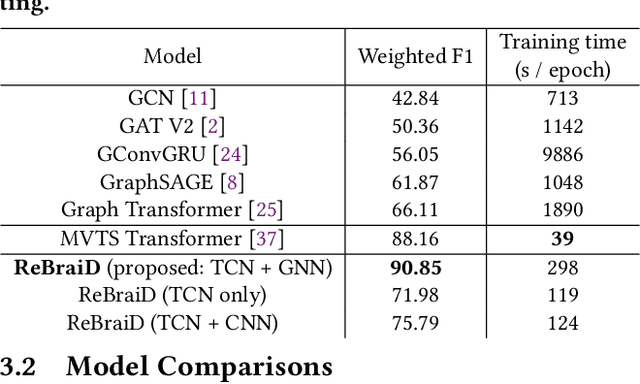
Finding an appropriate representation of dynamic activities in the brain is crucial for many downstream applications. Due to its highly dynamic nature, temporally averaged fMRI (functional magnetic resonance imaging) can only provide a narrow view of underlying brain activities. Previous works lack the ability to learn and interpret the latent dynamics in brain architectures. This paper builds an efficient graph neural network model that incorporates both region-mapped fMRI sequences and structural connectivities obtained from DWI (diffusion-weighted imaging) as inputs. We find good representations of the latent brain dynamics through learning sample-level adaptive adjacency matrices and performing a novel multi-resolution inner cluster smoothing. These modules can be easily adapted to and are potentially useful for other applications outside the neuroscience domain. We also attribute inputs with integrated gradients, which enables us to infer (1) highly involved brain connections and subnetworks for each task, (2) temporal keyframes of imaging sequences that characterize tasks, and (3) subnetworks that discriminate between individual subjects. This ability to identify critical subnetworks that characterize signal states across heterogeneous tasks and individuals is of great importance to neuroscience and other scientific domains. Extensive experiments and ablation studies demonstrate our proposed method's superiority and efficiency in spatial-temporal graph signal modeling with insightful interpretations of brain dynamics.
Learning Interpretable Models for Coupled Networks Under Domain Constraints
Apr 19, 2021
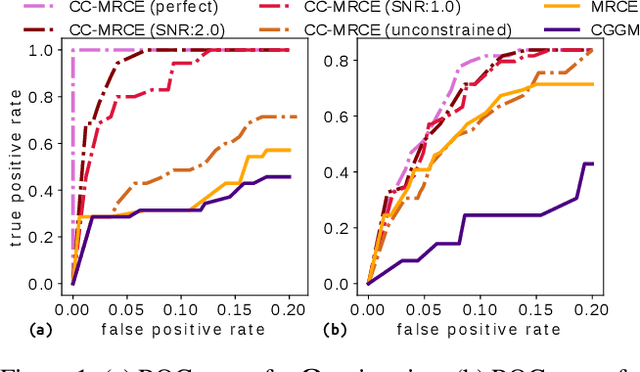
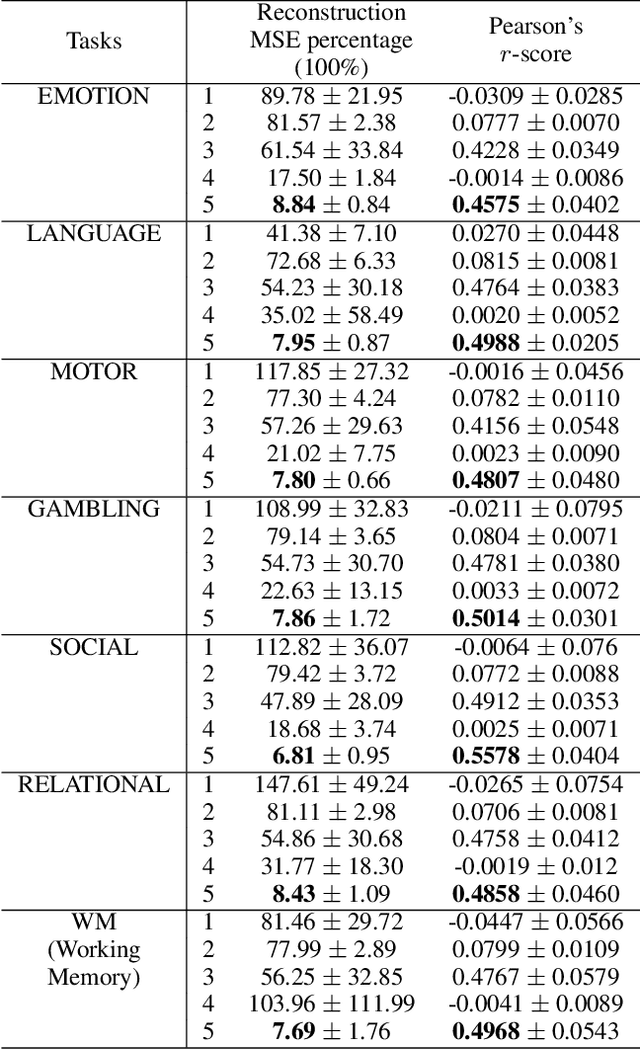

Modeling the behavior of coupled networks is challenging due to their intricate dynamics. For example in neuroscience, it is of critical importance to understand the relationship between the functional neural processes and anatomical connectivities. Modern neuroimaging techniques allow us to separately measure functional connectivity through fMRI imaging and the underlying white matter wiring through diffusion imaging. Previous studies have shown that structural edges in brain networks improve the inference of functional edges and vice versa. In this paper, we investigate the idea of coupled networks through an optimization framework by focusing on interactions between structural edges and functional edges of brain networks. We consider both types of edges as observed instances of random variables that represent different underlying network processes. The proposed framework does not depend on Gaussian assumptions and achieves a more robust performance on general data compared with existing approaches. To incorporate existing domain knowledge into such studies, we propose a novel formulation to place hard network constraints on the noise term while estimating interactions. This not only leads to a cleaner way of applying network constraints but also provides a more scalable solution when network connectivity is sparse. We validate our method on multishell diffusion and task-evoked fMRI datasets from the Human Connectome Project, leading to both important insights on structural backbones that support various types of task activities as well as general solutions to the study of coupled networks.
White Noise Analysis of Neural Networks
Dec 23, 2019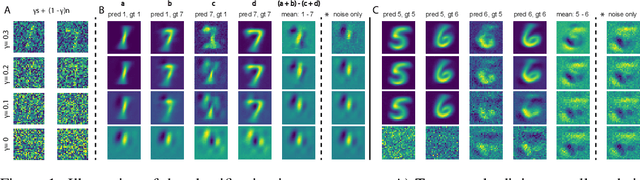
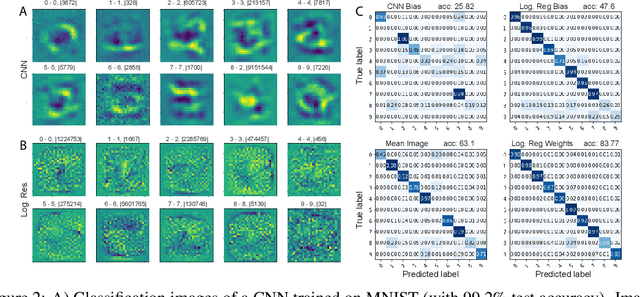

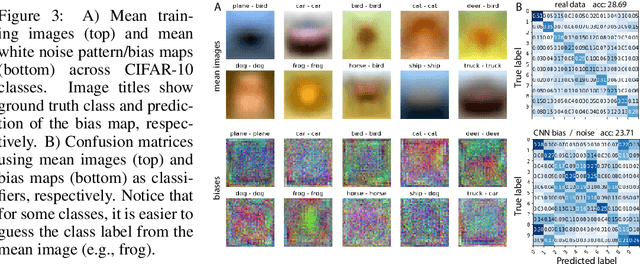
A white noise analysis of modern deep neural networks is presented to unveil their biases at the whole network level or the single neuron level. Our analysis is based on two popular and related methods in psychophysics and neurophysiology namely classification images and spike triggered analysis. These methods have been widely used to understand the underlying mechanisms of sensory systems in humans and monkeys. We leverage them to investigate the inherent biases of deep neural networks and to obtain a first-order approximation of their functionality. We emphasize on CNNs since they are currently the state of the art methods in computer vision and are a decent model of human visual processing. In addition, we study multi-layer perceptrons, logistic regression, and recurrent neural networks. Experiments over four classic datasets, MNIST, Fashion-MNIST, CIFAR-10, and ImageNet, show that the computed bias maps resemble the target classes and when used for classification lead to an over twofold performance than the chance level. Further, we show that classification images can be used to attack a black-box classifier and to detect adversarial patch attacks. Finally, we utilize spike triggered averaging to derive the filters of CNNs and explore how the behavior of a network changes when neurons in different layers are modulated. Our effort illustrates a successful example of borrowing from neurosciences to study ANNs and highlights the importance of cross-fertilization and synergy across machine learning, deep learning, and computational neuroscience.
Where's YOUR focus: Personalized Attention
Feb 22, 2018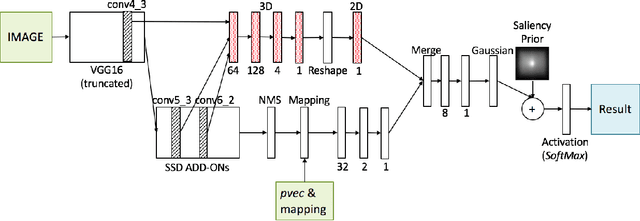
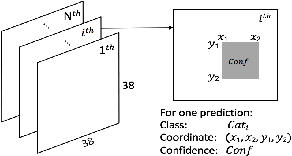
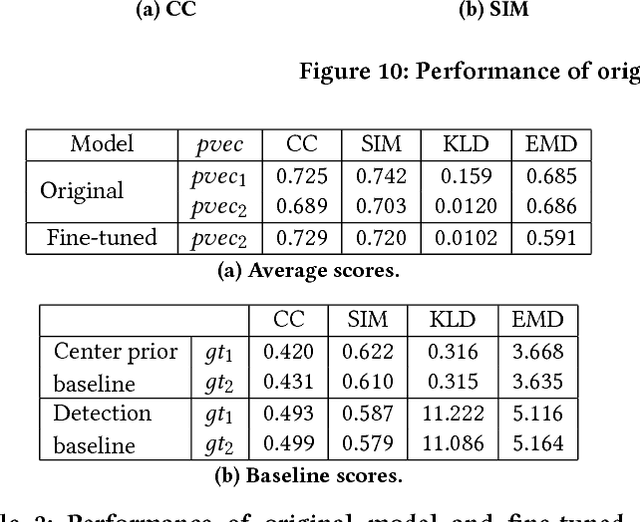
Human visual attention is subjective and biased according to the personal preference of the viewer, however, current works of saliency detection are general and objective, without counting the factor of the observer. This will make the attention prediction for a particular person not accurate enough. In this work, we present the novel idea of personalized attention prediction and develop Personalized Attention Network (PANet), a convolutional network that predicts saliency in images with personal preference. The model consists of two streams which share common feature extraction layers, and one stream is responsible for saliency prediction, while the other is adapted from the detection model and used to fit user preference. We automatically collect user preference from their albums and leaves them freedom to define what and how many categories their preferences are divided into. To train PANet, we dynamically generate ground truth saliency maps upon existing detection labels and saliency labels, and the generation parameters are based upon our collected datasets consists of 1k images. We evaluate the model with saliency prediction metrics and test the trained model on different preference vectors. The results have shown that our system is much better than general models in personalized saliency prediction and is efficient to use for different preferences.