 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMExplainer: a Knowledge-Enhanced Explainer for Language Models
Mar 29, 2023



Large language models (LMs) such as GPT-4 are very powerful and can process different kinds of natural language processing (NLP) tasks. However, it can be difficult to interpret the results due to the multi-layer nonlinear model structure and millions of parameters. Lack of understanding of how the model works can make the model unreliable and dangerous for everyday users in real-world scenarios. Most recent works exploit the weights of attention to provide explanations for model predictions. However, pure attention-based explanation is unable to support the growing complexity of the models, and cannot reason about their decision-making processes. Thus, we propose LMExplainer, a knowledge-enhanced interpretation module for language models that can provide human-understandable explanations. We use a knowledge graph (KG) and a graph attention neural network to extract the key decision signals of the LM. We further explore whether interpretation can also help AI understand the task better. Our experimental results show that LMExplainer outperforms existing LM+KG methods on CommonsenseQA and OpenBookQA. We also compare the explanation results with generated explanation methods and human-annotated results. The comparison shows our method can provide more comprehensive and clearer explanations. LMExplainer demonstrates the potential to enhance model performance and furnish explanations for the reasoning processes of models in natural language.
Mind Reader: Reconstructing complex images from brain activities
Sep 30, 2022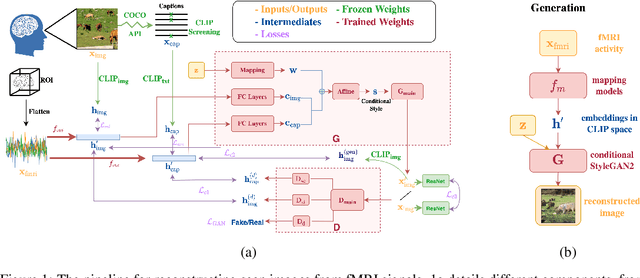


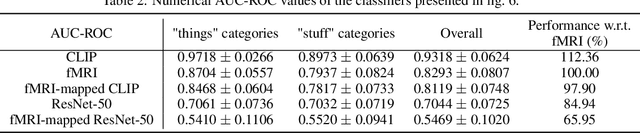
Understanding how the brain encodes external stimuli and how these stimuli can be decoded from the measured brain activities are long-standing and challenging questions in neuroscience. In this paper, we focus on reconstructing the complex image stimuli from fMRI (functional magnetic resonance imaging) signals. Unlike previous works that reconstruct images with single objects or simple shapes, our work aims to reconstruct image stimuli that are rich in semantics, closer to everyday scenes, and can reveal more perspectives. However, data scarcity of fMRI datasets is the main obstacle to applying state-of-the-art deep learning models to this problem. We find that incorporating an additional text modality is beneficial for the reconstruction problem compared to directly translating brain signals to images. Therefore, the modalities involved in our method are: (i) voxel-level fMRI signals, (ii) observed images that trigger the brain signals, and (iii) textual description of the images. To further address data scarcity, we leverage an aligned vision-language latent space pre-trained on massive datasets. Instead of training models from scratch to find a latent space shared by the three modalities, we encode fMRI signals into this pre-aligned latent space. Then, conditioned on embeddings in this space, we reconstruct images with a generative model. The reconstructed images from our pipeline balance both naturalness and fidelity: they are photo-realistic and capture the ground truth image contents well.
Modeling Human-AI Team Decision Making
Jan 08, 2022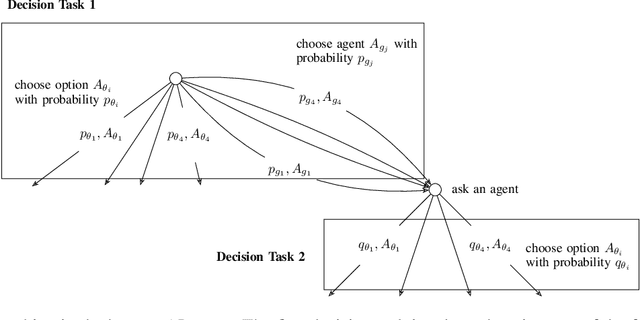

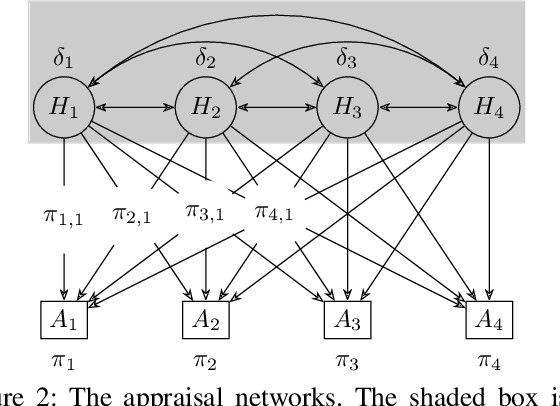

AI and humans bring complementary skills to group deliberations. Modeling this group decision making is especially challenging when the deliberations include an element of risk and an exploration-exploitation process of appraising the capabilities of the human and AI agents. To investigate this question, we presented a sequence of intellective issues to a set of human groups aided by imperfect AI agents. A group's goal was to appraise the relative expertise of the group's members and its available AI agents, evaluate the risks associated with different actions, and maximize the overall reward by reaching consensus. We propose and empirically validate models of human-AI team decision making under such uncertain circumstances, and show the value of socio-cognitive constructs of prospect theory, influence dynamics, and Bayesian learning in predicting the behavior of human-AI groups.