 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Coding with Bayesian Priors via Proximal Gradients
Jun 06, 2026We recast predictive coding as continuous-time proximal gradient descent applied to a regularized maximum-a-posteriori (MAP) objective. We study first a single-level problem and then a multi-level hierarchy. For the single-level problem, we show that proximal gradient descent is precisely a leaky firing-rate network: the membrane leak, the effective recurrent matrix, the local synaptic drive, and the static nonlinearity all follow from one optimization principle, and the resulting circuit is the one proposed by Rao and Ballard. The prior selects the nonlinearity through its proximal operator, and the likelihood precision sets the gain on the observation. For the hierarchy, we show that a classical variable-splitting relaxation of the deep MAP problem yields hierarchical predictive coding as the interconnection of local and distributed solvers. In probabilistic modeling terms, this relaxation replaces the directed generative chain by an undirected Markov random field whose node potentials are the level-wise priors. Each level then applies its own activation function, namely the proximal operator of its prior.
A Nonlinear Separation Principle: Applications to Neural Networks, Control and Learning
Apr 16, 2026This paper investigates continuous-time and discrete-time firing-rate and Hopfield recurrent neural networks (RNNs), with applications in nonlinear control design and implicit deep learning. First, we introduce a nonlinear separation principle that guarantees global exponential stability for the interconnection of a contracting state-feedback controller and a contracting observer, alongside parametric extensions for robustness and equilibrium tracking. Second, we derive sharp linear matrix inequality (LMI) conditions that guarantee the contractivity of both firing rate and Hopfield neural network architectures. We establish structural relationships among these certificates-demonstrating that continuous-time models with monotone non-decreasing activations maximize the admissible weight space, and extend these stability guarantees to interconnected systems and Graph RNNs. Third, we combine our separation principle and LMI framework to solve the output reference tracking problem for RNN-modeled plants. We provide LMI synthesis methods for feedback controllers and observers, and rigorously design a low-gain integral controller to eliminate steady-state error. Finally, we derive an exact, unconstrained algebraic parameterization of our contraction LMIs to design highly expressive implicit neural networks, achieving competitive accuracy and parameter efficiency on standard image classification benchmarks.
Energy-Based Dynamical Models for Neurocomputation, Learning, and Optimization
Apr 06, 2026Recent advances at the intersection of control theory, neuroscience, and machine learning have revealed novel mechanisms by which dynamical systems perform computation. These advances encompass a wide range of conceptual, mathematical, and computational ideas, with applications for model learning and training, memory retrieval, data-driven control, and optimization. This tutorial focuses on neuro-inspired approaches to computation that aim to improve scalability, robustness, and energy efficiency across such tasks, bridging the gap between artificial and biological systems. Particular emphasis is placed on energy-based dynamical models that encode information through gradient flows and energy landscapes. We begin by reviewing classical formulations, such as continuous-time Hopfield networks and Boltzmann machines, and then extend the framework to modern developments. These include dense associative memory models for high-capacity storage, oscillator-based networks for large-scale optimization, and proximal-descent dynamics for composite and constrained reconstruction. The tutorial demonstrates how control-theoretic principles can guide the design of next-generation neurocomputing systems, steering the discussion beyond conventional feedforward and backpropagation-based approaches to artificial intelligence.
Oscillator-Based Associative Memory with Exponential Capacity: Theory, Algorithms, and Hardware Implementation
Apr 01, 2026Associative memory systems enable content-addressable storage and retrieval of patterns, a capability central to biological neural computation and artificial intelligence. Classical implementations such as Hopfield networks face fundamental limitations in memory capacity, scaling at most linearly with network size. We present an associative memory architecture based on Kuramoto oscillator networks with honeycomb topology in which memories are encoded as stable phase-locked configurations. The honeycomb network consists of multiple cycles that share nodes in a chain-like arrangement, creating a one-dimensional lattice of chained+loops. We prove that this architecture achieves exponential memory capacity: a network of $N$ oscillators can store $(2\lceil n_c/4 \rceil - 1)^m$ distinct patterns, where $m$ honeycomb cycles each contain $n_c$ oscillators. Moreover, we fully characterize all stable configurations and prove that each memory's basin of attraction maintains a guaranteed minimum size independent of network scale. Simulations using charge-density-wave (CDW) oscillators validate predicted phase-locking behavior, demonstrating practical realizability in neuromorphic hardware.
Detection of adversarial intent in Human-AI teams using LLMs
Mar 21, 2026Large language models (LLMs) are increasingly deployed in human-AI teams as support agents for complex tasks such as information retrieval, programming, and decision-making assistance. While these agents' autonomy and contextual knowledge enables them to be useful, it also exposes them to a broad range of attacks, including data poisoning, prompt injection, and even prompt engineering. Through these attack vectors, malicious actors can manipulate an LLM agent to provide harmful information, potentially manipulating human agents to make harmful decisions. While prior work has focused on LLMs as attack targets or adversarial actors, this paper studies their potential role as defensive supervisors within mixed human-AI teams. Using a dataset consisting of multi-party conversations and decisions for a real human-AI team over a 25 round horizon, we formulate the problem of malicious behavior detection from interaction traces. We find that LLMs are capable of identifying malicious behavior in real-time, and without task-specific information, indicating the potential for task-agnostic defense. Moreover, we find that the malicious behavior of interest is not easily identified using simple heuristics, further suggesting the introduction of LLM defenders could render human teams more robust to certain classes of attack.
FlowSymm: Physics Aware, Symmetry Preserving Graph Attention for Network Flow Completion
Jan 29, 2026Recovering missing flows on the edges of a network, while exactly respecting local conservation laws, is a fundamental inverse problem that arises in many systems such as transportation, energy, and mobility. We introduce FlowSymm, a novel architecture that combines (i) a group-action on divergence-free flows, (ii) a graph-attention encoder to learn feature-conditioned weights over these symmetry-preserving actions, and (iii) a lightweight Tikhonov refinement solved via implicit bilevel optimization. The method first anchors the given observation on a minimum-norm divergence-free completion. We then compute an orthonormal basis for all admissible group actions that leave the observed flows invariant and parameterize the valid solution subspace, which shows an Abelian group structure under vector addition. A stack of GATv2 layers then encodes the graph and its edge features into per-edge embeddings, which are pooled over the missing edges and produce per-basis attention weights. This attention-guided process selects a set of physics-aware group actions that preserve the observed flows. Finally, a scalar Tikhonov penalty refines the missing entries via a convex least-squares solver, with gradients propagated implicitly through Cholesky factorization. Across three real-world flow benchmarks (traffic, power, bike), FlowSymm outperforms state-of-the-art baselines in RMSE, MAE and correlation metrics.
Similarity Matching Networks: Hebbian Learning and Convergence Over Multiple Time Scales
Jun 06, 2025A recent breakthrough in biologically-plausible normative frameworks for dimensionality reduction is based upon the similarity matching cost function and the low-rank matrix approximation problem. Despite clear biological interpretation, successful application in several domains, and experimental validation, a formal complete convergence analysis remains elusive. Building on this framework, we consider and analyze a continuous-time neural network, the \emph{similarity matching network}, for principal subspace projection. Derived from a min-max-min objective, this biologically-plausible network consists of three coupled dynamics evolving at different time scales: neural dynamics, lateral synaptic dynamics, and feedforward synaptic dynamics at the fast, intermediate, and slow time scales, respectively. The feedforward and lateral synaptic dynamics consist of Hebbian and anti-Hebbian learning rules, respectively. By leveraging a multilevel optimization framework, we prove convergence of the dynamics in the offline setting. Specifically, at the first level (fast time scale), we show strong convexity of the cost function and global exponential convergence of the corresponding gradient-flow dynamics. At the second level (intermediate time scale), we prove strong concavity of the cost function and exponential convergence of the corresponding gradient-flow dynamics within the space of positive definite matrices. At the third and final level (slow time scale), we study a non-convex and non-smooth cost function, provide explicit expressions for its global minima, and prove almost sure convergence of the corresponding gradient-flow dynamics to the global minima. These results rely on two empirically motivated conjectures that are supported by thorough numerical experiments. Finally, we validate the effectiveness of our approach via a numerical example.
Firing Rate Models as Associative Memory: Excitatory-Inhibitory Balance for Robust Retrieval
Nov 11, 2024


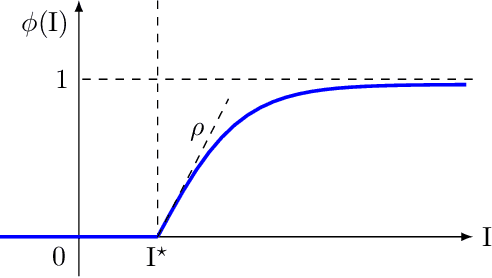
Firing rate models are dynamical systems widely used in applied and theoretical neuroscience to describe local cortical dynamics in neuronal populations. By providing a macroscopic perspective of neuronal activity, these models are essential for investigating oscillatory phenomena, chaotic behavior, and associative memory processes. Despite their widespread use, the application of firing rate models to associative memory networks has received limited mathematical exploration, and most existing studies are focused on specific models. Conversely, well-established associative memory designs, such as Hopfield networks, lack key biologically-relevant features intrinsic to firing rate models, including positivity and interpretable synaptic matrices that reflect excitatory and inhibitory interactions. To address this gap, we propose a general framework that ensures the emergence of re-scaled memory patterns as stable equilibria in the firing rate dynamics. Furthermore, we analyze the conditions under which the memories are locally and globally asymptotically stable, providing insights into constructing biologically-plausible and robust systems for associative memory retrieval.
Proximal Gradient Dynamics: Monotonicity, Exponential Convergence, and Applications
Sep 16, 2024In this letter, we study the proximal gradient dynamics. This recently-proposed continuous-time dynamics solves optimization problems whose cost functions are separable into a nonsmooth convex and a smooth component. First, we show that the cost function decreases monotonically along the trajectories of the proximal gradient dynamics. We then introduce a new condition that guarantees exponential convergence of the cost function to its optimal value, and show that this condition implies the proximal Polyak-{\L}ojasiewicz condition. We also show that the proximal Polyak-{\L}ojasiewicz condition guarantees exponential convergence of the cost function. Moreover, we extend these results to time-varying optimization problems, providing bounds for equilibrium tracking. Finally, we discuss applications of these findings, including the LASSO problem, quadratic optimization with polytopic constraints, and certain matrix based problems.
Learning Neural Contracting Dynamics: Extended Linearization and Global Guarantees
Feb 14, 2024



Global stability and robustness guarantees in learned dynamical systems are essential to ensure well-behavedness of the systems in the face of uncertainty. We present Extended Linearized Contracting Dynamics (ELCD), the first neural network-based dynamical system with global contractivity guarantees in arbitrary metrics. The key feature of ELCD is a parametrization of the extended linearization of the nonlinear vector field. In its most basic form, ELCD is guaranteed to be (i) globally exponentially stable, (ii) equilibrium contracting, and (iii) globally contracting with respect to some metric. To allow for contraction with respect to more general metrics in the data space, we train diffeomorphisms between the data space and a latent space and enforce contractivity in the latent space, which ensures global contractivity in the data space. We demonstrate the performance of ELCD on the $2$D, $4$D, and $8$D LASA datasets.