 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphEval2000: Benchmarking and Improving Large Language Models on Graph Datasets
Jun 23, 2024


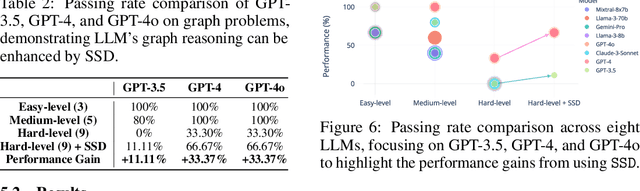
Large language models (LLMs) have achieved remarkable success in natural language processing (NLP), demonstrating significant capabilities in processing and understanding text data. However, recent studies have identified limitations in LLMs' ability to reason about graph-structured data. To address this gap, we introduce GraphEval2000, the first comprehensive graph dataset, comprising 40 graph data structure problems along with 2000 test cases. Additionally, we introduce an evaluation framework based on GraphEval2000, designed to assess the graph reasoning abilities of LLMs through coding challenges. Our dataset categorizes test cases into four primary and four sub-categories, ensuring a comprehensive evaluation. We evaluate eight popular LLMs on GraphEval2000, revealing that LLMs exhibit a better understanding of directed graphs compared to undirected ones. While private LLMs consistently outperform open-source models, the performance gap is narrowing. Furthermore, to improve the usability of our evaluation framework, we propose Structured Symbolic Decomposition (SSD), an instruction-based method designed to enhance LLM performance on GraphEval2000. Results show that SSD improves the performance of GPT-3.5, GPT-4, and GPT-4o on complex graph problems, with an increase of 11.11\%, 33.37\%, and 33.37\%, respectively.
IDKM: Memory Efficient Neural Network Quantization via Implicit, Differentiable k-Means
Dec 15, 2023Compressing large neural networks with minimal performance loss is crucial to enabling their deployment on edge devices. (Cho et al., 2022) proposed a weight quantization method that uses an attention-based clustering algorithm called differentiable $k$-means (DKM). Despite achieving state-of-the-art results, DKM's performance is constrained by its heavy memory dependency. We propose an implicit, differentiable $k$-means algorithm (IDKM), which eliminates the major memory restriction of DKM. Let $t$ be the number of $k$-means iterations, $m$ be the number of weight-vectors, and $b$ be the number of bits per cluster address. IDKM reduces the overall memory complexity of a single $k$-means layer from $\mathcal{O}(t \cdot m \cdot 2^b)$ to $\mathcal{O}( m \cdot 2^b)$. We also introduce a variant, IDKM with Jacobian-Free-Backpropagation (IDKM-JFB), for which the time complexity of the gradient calculation is independent of $t$ as well. We provide a proof of concept of our methods by showing that, under the same settings, IDKM achieves comparable performance to DKM with less compute time and less memory. We also use IDKM and IDKM-JFB to quantize a large neural network, Resnet18, on hardware where DKM cannot train at all.
Learning Interpretable Models for Coupled Networks Under Domain Constraints
Apr 19, 2021
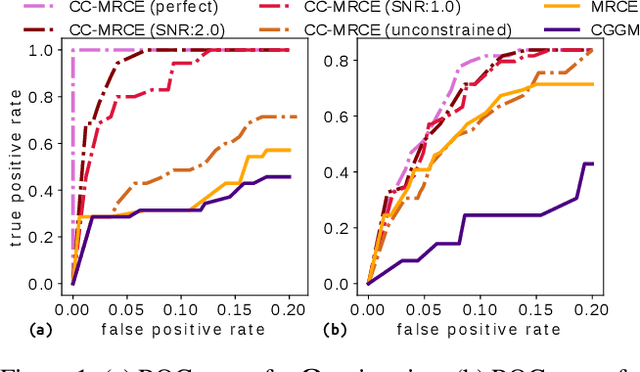

Modeling the behavior of coupled networks is challenging due to their intricate dynamics. For example in neuroscience, it is of critical importance to understand the relationship between the functional neural processes and anatomical connectivities. Modern neuroimaging techniques allow us to separately measure functional connectivity through fMRI imaging and the underlying white matter wiring through diffusion imaging. Previous studies have shown that structural edges in brain networks improve the inference of functional edges and vice versa. In this paper, we investigate the idea of coupled networks through an optimization framework by focusing on interactions between structural edges and functional edges of brain networks. We consider both types of edges as observed instances of random variables that represent different underlying network processes. The proposed framework does not depend on Gaussian assumptions and achieves a more robust performance on general data compared with existing approaches. To incorporate existing domain knowledge into such studies, we propose a novel formulation to place hard network constraints on the noise term while estimating interactions. This not only leads to a cleaner way of applying network constraints but also provides a more scalable solution when network connectivity is sparse. We validate our method on multishell diffusion and task-evoked fMRI datasets from the Human Connectome Project, leading to both important insights on structural backbones that support various types of task activities as well as general solutions to the study of coupled networks.
Expertise and confidence explain how social influence evolves along intellective tasks
Nov 13, 2020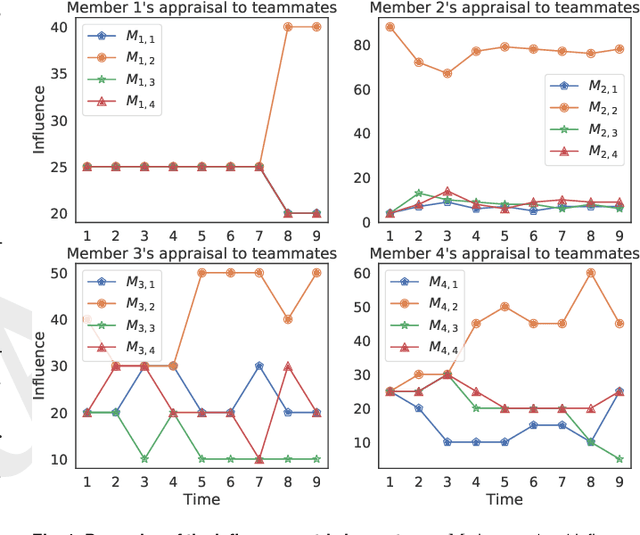
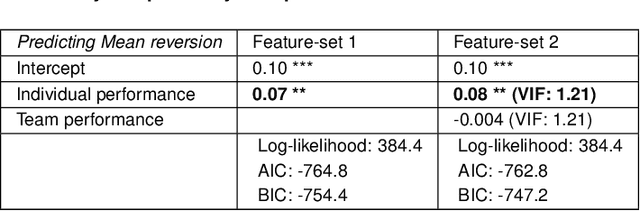
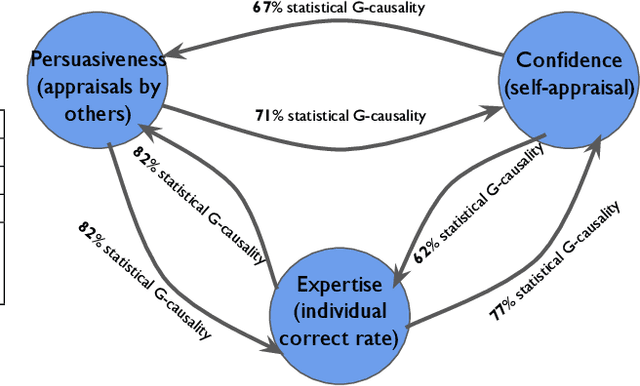

Discovering the antecedents of individuals' influence in collaborative environments is an important, practical, and challenging problem. In this paper, we study interpersonal influence in small groups of individuals who collectively execute a sequence of intellective tasks. We observe that along an issue sequence with feedback, individuals with higher expertise and social confidence are accorded higher interpersonal influence. We also observe that low-performing individuals tend to underestimate their high-performing teammate's expertise. Based on these observations, we introduce three hypotheses and present empirical and theoretical support for their validity. We report empirical evidence on longstanding theories of transactive memory systems, social comparison, and confidence heuristics on the origins of social influence. We propose a cognitive dynamical model inspired by these theories to describe the process by which individuals adjust interpersonal influences over time. We demonstrate the model's accuracy in predicting individuals' influence and provide analytical results on its asymptotic behavior for the case with identically performing individuals. Lastly, we propose a novel approach using deep neural networks on a pre-trained text embedding model for predicting the influence of individuals. Using message contents, message times, and individual correctness collected during tasks, we are able to accurately predict individuals' self-reported influence over time. Extensive experiments verify the accuracy of the proposed models compared to baselines such as structural balance and reflected appraisal model. While the neural networks model is the most accurate, the dynamical model is the most interpretable for influence prediction.
DANR: Discrepancy-aware Network Regularization
May 31, 2020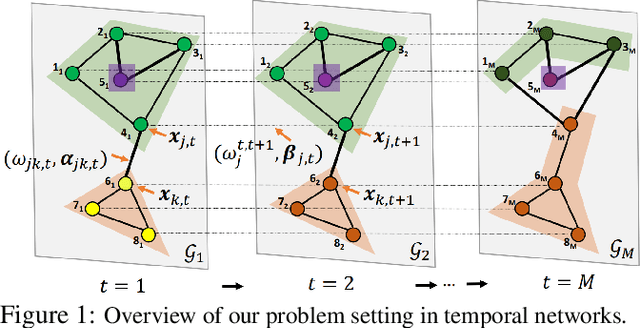
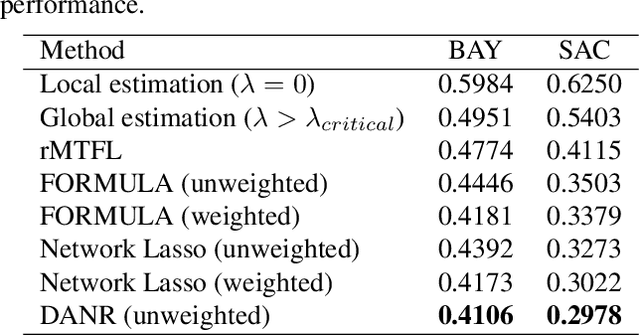
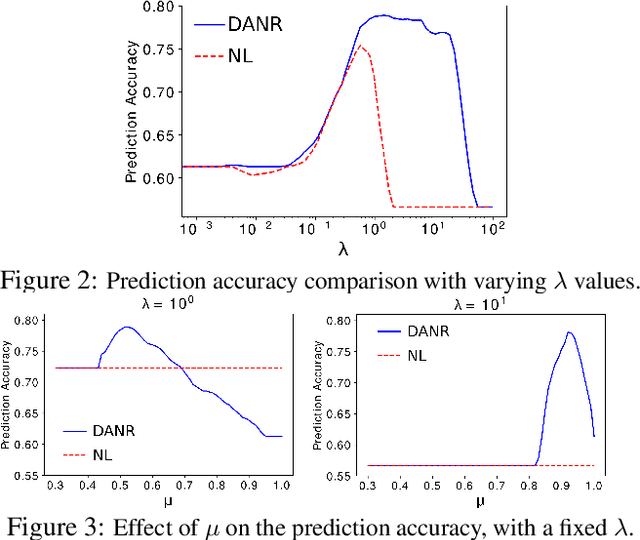
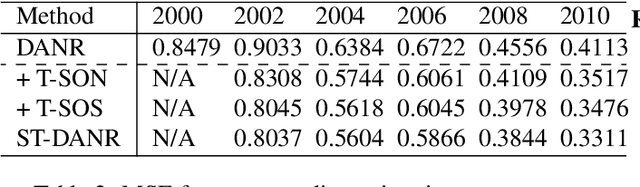
Network regularization is an effective tool for incorporating structural prior knowledge to learn coherent models over networks, and has yielded provably accurate estimates in applications ranging from spatial economics to neuroimaging studies. Recently, there has been an increasing interest in extending network regularization to the spatio-temporal case to accommodate the evolution of networks. However, in both static and spatio-temporal cases, missing or corrupted edge weights can compromise the ability of network regularization to discover desired solutions. To address these gaps, we propose a novel approach---{\it discrepancy-aware network regularization} (DANR)---that is robust to inadequate regularizations and effectively captures model evolution and structural changes over spatio-temporal networks. We develop a distributed and scalable algorithm based on the alternating direction method of multipliers (ADMM) to solve the proposed problem with guaranteed convergence to global optimum solutions. Experimental results on both synthetic and real-world networks demonstrate that our approach achieves improved performance on various tasks, and enables interpretation of model changes in evolving networks.
Estimating localized complexity of white-matter wiring with GANs
Oct 02, 2019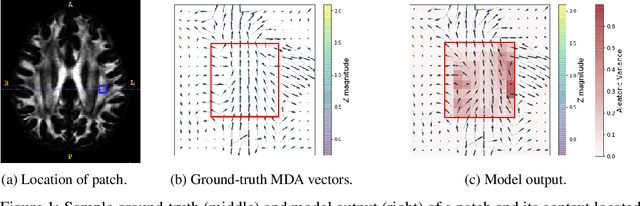
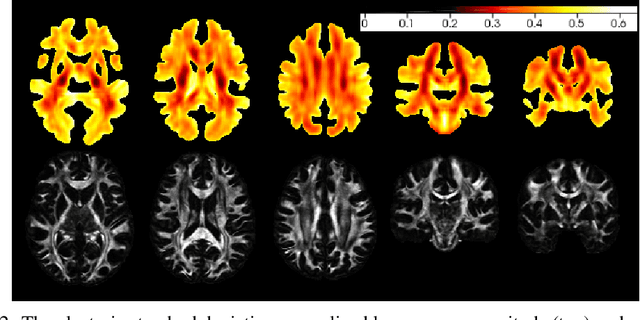
In-vivo examination of the physical connectivity of axonal projections through the white matter of the human brain is made possible by diffusion weighted magnetic resonance imaging (dMRI) Analysis of dMRI commonly considers derived scalar metrics such as fractional anisotrophy as proxies for "white matter integrity," and differences of such measures have been observed as significantly correlating with various neurological diagnosis and clinical measures such as executive function, presence of multiple sclerosis, and genetic similarity. The analysis of such voxel measures is confounded in areas of more complicated fiber wiring due to crossing, kissing, and dispersing fibers. Recently, Volz et al. introduced a simple probabilistic measure of the count of distinct fiber populations within a voxel, which was shown to reduce variance in group comparisons. We propose a complementary measure that considers the complexity of a voxel in context of its local region, with an aim to quantify the localized wiring complexity of every part of white matter. This allows, for example, identification of particularly ambiguous regions of the brain for tractographic approaches of modeling global wiring connectivity. Our method builds on recent advances in image inpainting, in which the task is to plausibly fill in a missing region of an image. Our proposed method builds on a Bayesian estimate of heteroscedastic aleatoric uncertainty of a region of white matter by inpainting it from its context. We define the localized wiring complexity of white matter as how accurately and confidently a well-trained model can predict the missing patch. In our results, we observe low aleatoric uncertainty along major neuronal pathways which increases at junctions and towards cortex boundaries. This directly quantifies the difficulty of lesion inpainting of dMRI images at all parts of white matter.
Spatial Coherence of Oriented White Matter Microstructure: Applications to White Matter Regions Associated with Genetic Similarity
Feb 14, 2018
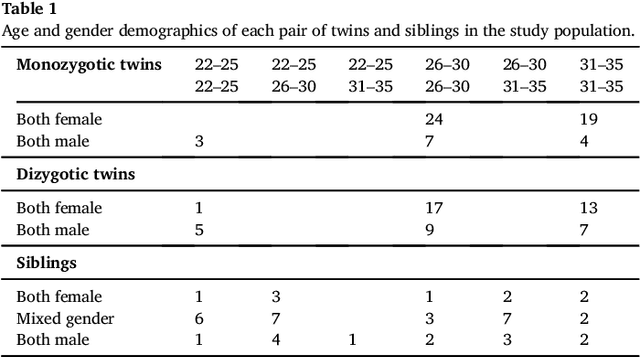
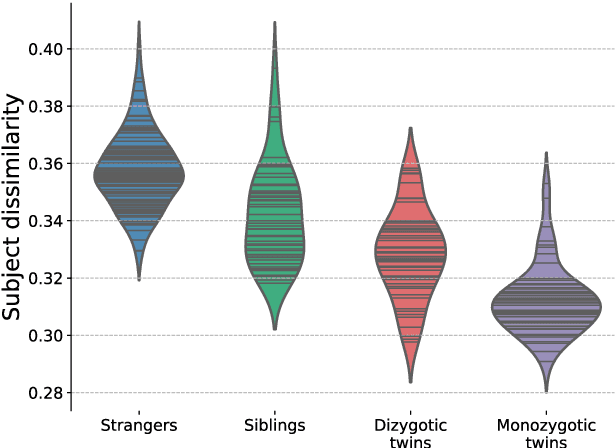
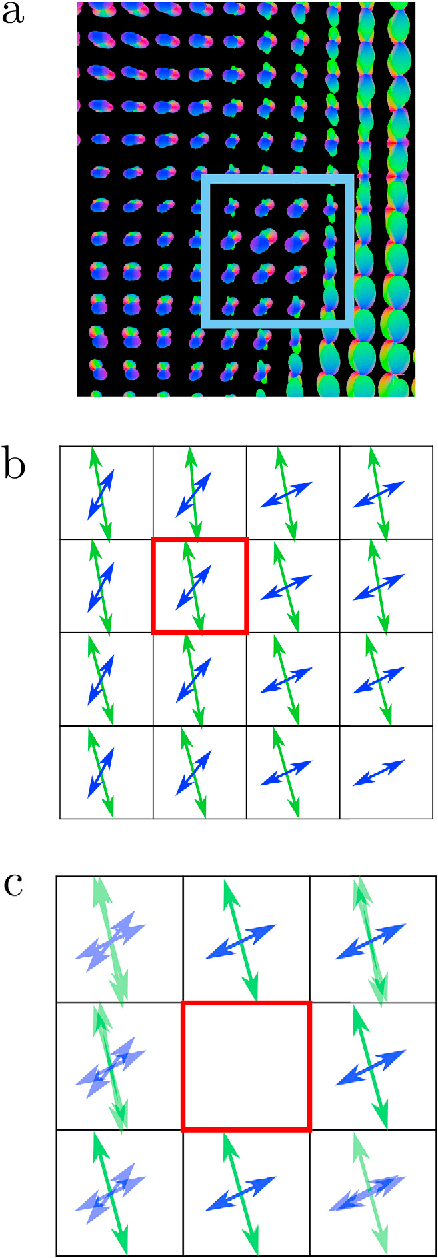
We present a method to discover differences between populations with respect to the spatial coherence of their oriented white matter microstructure in arbitrarily shaped white matter regions. This method is applied to diffusion MRI scans of a subset of the Human Connectome Project dataset: 57 pairs of monozygotic and 52 pairs of dizygotic twins. After controlling for morphological similarity between twins, we identify 3.7% of all white matter as being associated with genetic similarity (35.1k voxels, $p < 10^{-4}$, false discovery rate 1.5%), 75% of which spatially clusters into twenty-two contiguous white matter regions. Furthermore, we show that the orientation similarity within these regions generalizes to a subset of 47 pairs of non-twin siblings, and show that these siblings are on average as similar as dizygotic twins. The regions are located in deep white matter including the superior longitudinal fasciculus, the optic radiations, the middle cerebellar peduncle, the corticospinal tract, and within the anterior temporal lobe, as well as the cerebellum, brain stem, and amygdalae. These results extend previous work using undirected fractional anisotrophy for measuring putative heritable influences in white matter. Our multidirectional extension better accounts for crossing fiber connections within voxels. This bottom up approach has at its basis a novel measurement of coherence within neighboring voxel dyads between subjects, and avoids some of the fundamental ambiguities encountered with tractographic approaches to white matter analysis that estimate global connectivity.
Discriminative Subnetworks with Regularized Spectral Learning for Global-state Network Data
Dec 19, 2015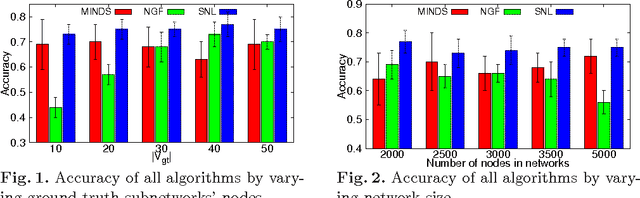
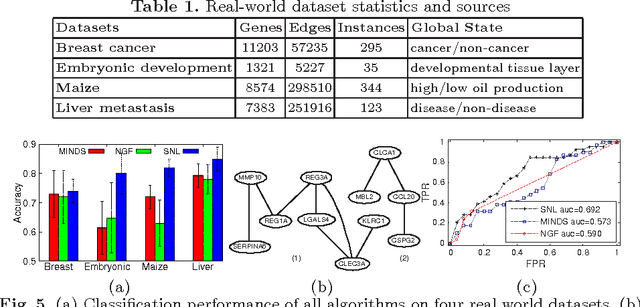
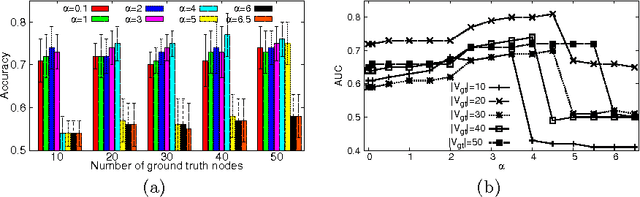
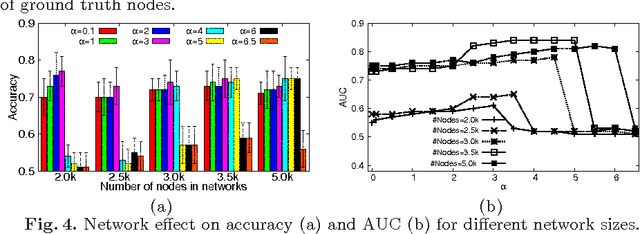
Data mining practitioners are facing challenges from data with network structure. In this paper, we address a specific class of global-state networks which comprises of a set of network instances sharing a similar structure yet having different values at local nodes. Each instance is associated with a global state which indicates the occurrence of an event. The objective is to uncover a small set of discriminative subnetworks that can optimally classify global network values. Unlike most existing studies which explore an exponential subnetwork space, we address this difficult problem by adopting a space transformation approach. Specifically, we present an algorithm that optimizes a constrained dual-objective function to learn a low-dimensional subspace that is capable of discriminating networks labelled by different global states, while reconciling with common network topology sharing across instances. Our algorithm takes an appealing approach from spectral graph learning and we show that the globally optimum solution can be achieved via matrix eigen-decomposition.
Behavior Query Discovery in System-Generated Temporal Graphs
Nov 19, 2015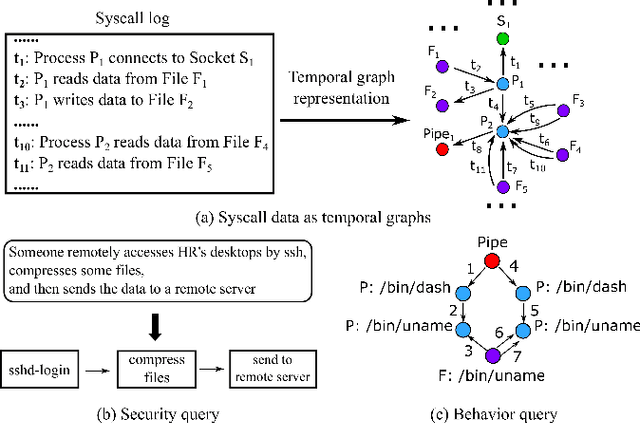
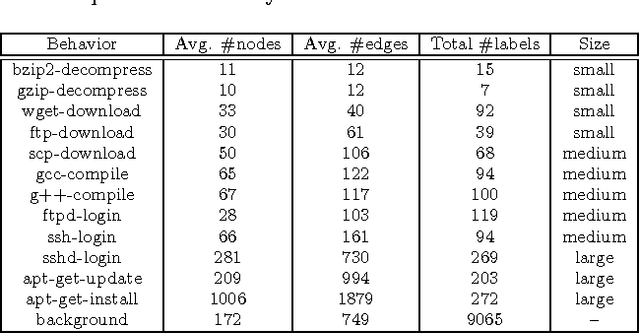
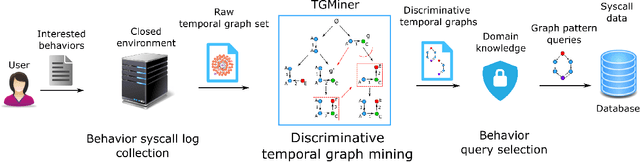
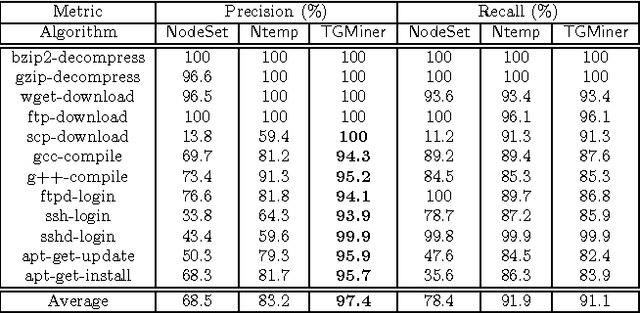
Computer system monitoring generates huge amounts of logs that record the interaction of system entities. How to query such data to better understand system behaviors and identify potential system risks and malicious behaviors becomes a challenging task for system administrators due to the dynamics and heterogeneity of the data. System monitoring data are essentially heterogeneous temporal graphs with nodes being system entities and edges being their interactions over time. Given the complexity of such graphs, it becomes time-consuming for system administrators to manually formulate useful queries in order to examine abnormal activities, attacks, and vulnerabilities in computer systems. In this work, we investigate how to query temporal graphs and treat query formulation as a discriminative temporal graph pattern mining problem. We introduce TGMiner to mine discriminative patterns from system logs, and these patterns can be taken as templates for building more complex queries. TGMiner leverages temporal information in graphs to prune graph patterns that share similar growth trend without compromising pattern quality. Experimental results on real system data show that TGMiner is 6-32 times faster than baseline methods. The discovered patterns were verified by system experts; they achieved high precision (97%) and recall (91%).
Inferring the Underlying Structure of Information Cascades
Oct 12, 2012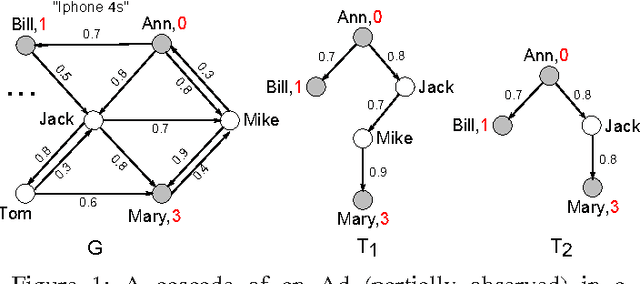
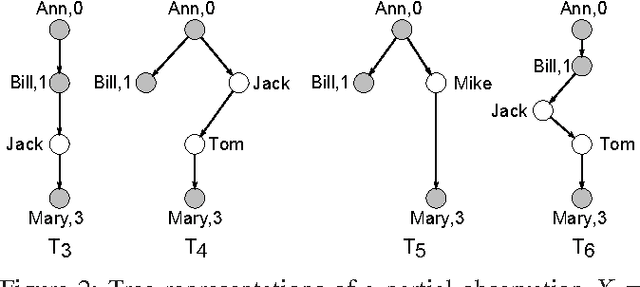
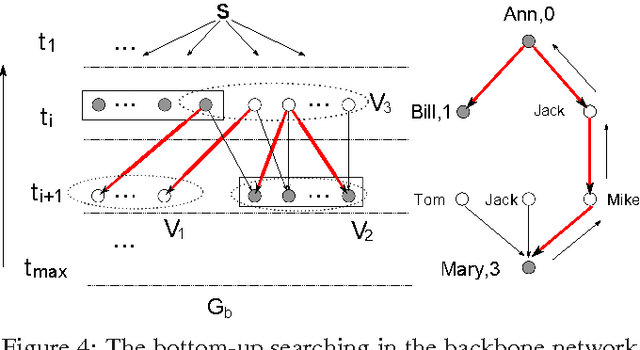
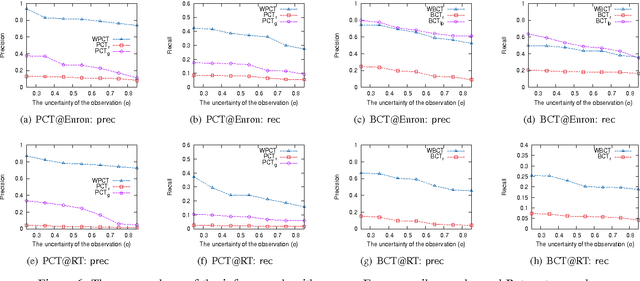
In social networks, information and influence diffuse among users as cascades. While the importance of studying cascades has been recognized in various applications, it is difficult to observe the complete structure of cascades in practice. Moreover, much less is known on how to infer cascades based on partial observations. In this paper we study the cascade inference problem following the independent cascade model, and provide a full treatment from complexity to algorithms: (a) We propose the idea of consistent trees as the inferred structures for cascades; these trees connect source nodes and observed nodes with paths satisfying the constraints from the observed temporal information. (b) We introduce metrics to measure the likelihood of consistent trees as inferred cascades, as well as several optimization problems for finding them. (c) We show that the decision problems for consistent trees are in general NP-complete, and that the optimization problems are hard to approximate. (d) We provide approximation algorithms with performance guarantees on the quality of the inferred cascades, as well as heuristics. We experimentally verify the efficiency and effectiveness of our inference algorithms, using real and synthetic data.