 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Rank Multi-Dictionary Selection at Scale
Jun 11, 2024



The sparse dictionary coding framework represents signals as a linear combination of a few predefined dictionary atoms. It has been employed for images, time series, graph signals and recently for 2-way (or 2D) spatio-temporal data employing jointly temporal and spatial dictionaries. Large and over-complete dictionaries enable high-quality models, but also pose scalability challenges which are exacerbated in multi-dictionary settings. Hence, an important problem that we address in this paper is: How to scale multi-dictionary coding for large dictionaries and datasets? We propose a multi-dictionary atom selection technique for low-rank sparse coding named LRMDS. To enable scalability to large dictionaries and datasets, it progressively selects groups of row-column atom pairs based on their alignment with the data and performs convex relaxation coding via the corresponding sub-dictionaries. We demonstrate both theoretically and experimentally that when the data has a low-rank encoding with a sparse subset of the atoms, LRMDS is able to select them with strong guarantees under mild assumptions. Furthermore, we demonstrate the scalability and quality of LRMDS in both synthetic and real-world datasets and for a range of coding dictionaries. It achieves 3X to 10X speed-up compared to baselines, while obtaining up to two orders of magnitude improvement in representation quality on some of the real world datasets given a fixed target number of atoms.
Multi-Dictionary Tensor Decomposition
Sep 18, 2023



Tensor decomposition methods are popular tools for analysis of multi-way datasets from social media, healthcare, spatio-temporal domains, and others. Widely adopted models such as Tucker and canonical polyadic decomposition (CPD) follow a data-driven philosophy: they decompose a tensor into factors that approximate the observed data well. In some cases side information is available about the tensor modes. For example, in a temporal user-item purchases tensor a user influence graph, an item similarity graph, and knowledge about seasonality or trends in the temporal mode may be available. Such side information may enable more succinct and interpretable tensor decomposition models and improved quality in downstream tasks. We propose a framework for Multi-Dictionary Tensor Decomposition (MDTD) which takes advantage of prior structural information about tensor modes in the form of coding dictionaries to obtain sparsely encoded tensor factors. We derive a general optimization algorithm for MDTD that handles both complete input and input with missing values. Our framework handles large sparse tensors typical to many real-world application domains. We demonstrate MDTD's utility via experiments with both synthetic and real-world datasets. It learns more concise models than dictionary-free counterparts and improves (i) reconstruction quality ($60\%$ fewer non-zero coefficients coupled with smaller error); (ii) missing values imputation quality (two-fold MSE reduction with up to orders of magnitude time savings) and (iii) the estimation of the tensor rank. MDTD's quality improvements do not come with a running time premium: it can decompose $19GB$ datasets in less than a minute. It can also impute missing values in sparse billion-entry tensors more accurately and scalably than state-of-the-art competitors.
Unsupervised Instance and Subnetwork Selection for Network Data
Dec 24, 2022Unlike tabular data, features in network data are interconnected within a domain-specific graph. Examples of this setting include gene expression overlaid on a protein interaction network (PPI) and user opinions in a social network. Network data is typically high-dimensional (large number of nodes) and often contains outlier snapshot instances and noise. In addition, it is often non-trivial and time-consuming to annotate instances with global labels (e.g., disease or normal). How can we jointly select discriminative subnetworks and representative instances for network data without supervision? We address these challenges within an unsupervised framework for joint subnetwork and instance selection in network data, called UISS, via a convex self-representation objective. Given an unlabeled network dataset, UISS identifies representative instances while ignoring outliers. It outperforms state-of-the-art baselines on both discriminative subnetwork selection and representative instance selection, achieving up to 10% accuracy improvement on all real-world data sets we use for evaluation. When employed for exploratory analysis in RNA-seq network samples from multiple studies it produces interpretable and informative summaries.
Temporal Scale Estimation for Oversampled Network Cascades: Theory, Algorithms, and Experiment
Sep 22, 2021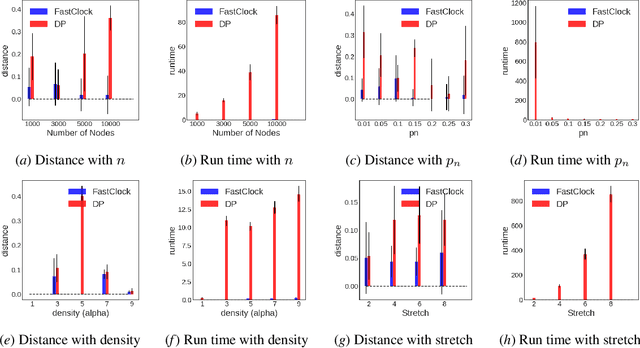
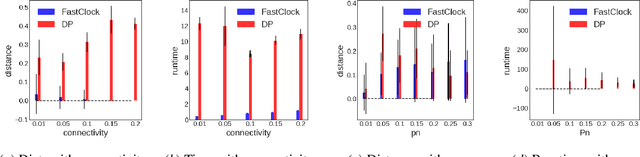
Spreading processes on graphs arise in a host of application domains, from the study of online social networks to viral marketing to epidemiology. Various discrete-time probabilistic models for spreading processes have been proposed. These are used for downstream statistical estimation and prediction problems, often involving messages or other information that is transmitted along with infections caused by the process. It is thus important to design models of cascade observation that take into account phenomena that lead to uncertainty about the process state at any given time. We highlight one such phenomenon -- temporal distortion -- caused by a misalignment between the rate at which observations of a cascade process are made and the rate at which the process itself operates, and argue that failure to correct for it results in degradation of performance on downstream statistical tasks. To address these issues, we formulate the clock estimation problem in terms of a natural distortion measure. We give a clock estimation algorithm, which we call FastClock, that runs in linear time in the size of its input and is provably statistically accurate for a broad range of model parameters when cascades are generated from the independent cascade process with known parameters and when the underlying graph is Erd\H{o}s-R\'enyi. We further give empirical results on the performance of our algorithm in comparison to the state of the art estimator, a likelihood proxy maximization-based estimator implemented via dynamic programming. We find that, in a broad parameter regime, our algorithm substantially outperforms the dynamic programming algorithm in terms of both running time and accuracy.
Temporal Graph Signal Decomposition
Jun 25, 2021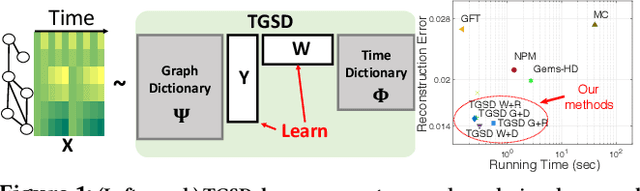

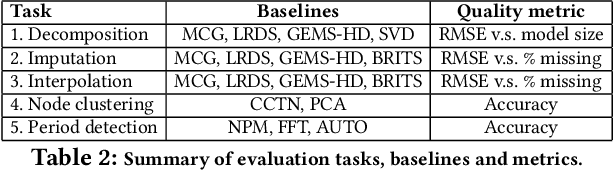
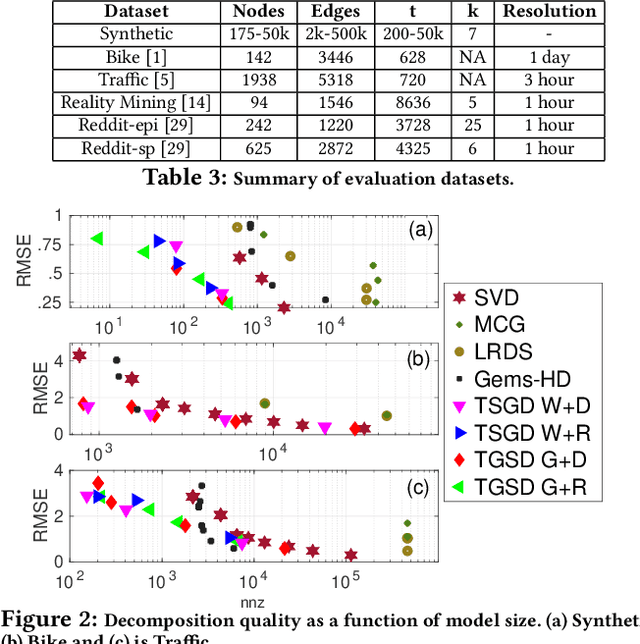
Temporal graph signals are multivariate time series with individual components associated with nodes of a fixed graph structure. Data of this kind arises in many domains including activity of social network users, sensor network readings over time, and time course gene expression within the interaction network of a model organism. Traditional matrix decomposition methods applied to such data fall short of exploiting structural regularities encoded in the underlying graph and also in the temporal patterns of the signal. How can we take into account such structure to obtain a succinct and interpretable representation of temporal graph signals? We propose a general, dictionary-based framework for temporal graph signal decomposition (TGSD). The key idea is to learn a low-rank, joint encoding of the data via a combination of graph and time dictionaries. We propose a highly scalable decomposition algorithm for both complete and incomplete data, and demonstrate its advantage for matrix decomposition, imputation of missing values, temporal interpolation, clustering, period estimation, and rank estimation in synthetic and real-world data ranging from traffic patterns to social media activity. Our framework achieves 28% reduction in RMSE compared to baselines for temporal interpolation when as many as 75% of the observations are missing. It scales best among baselines taking under 20 seconds on 3.5 million data points and produces the most parsimonious models. To the best of our knowledge, TGSD is the first framework to jointly model graph signals by temporal and graph dictionaries.
LinksIQ: Robust and Efficient Modulation Recognition with Imperfect Spectrum Scans
May 07, 2020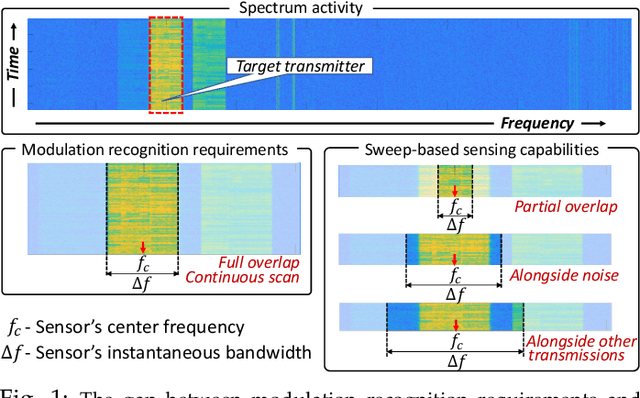
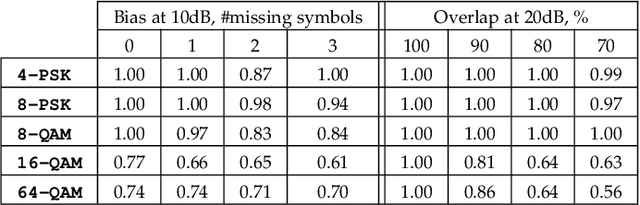

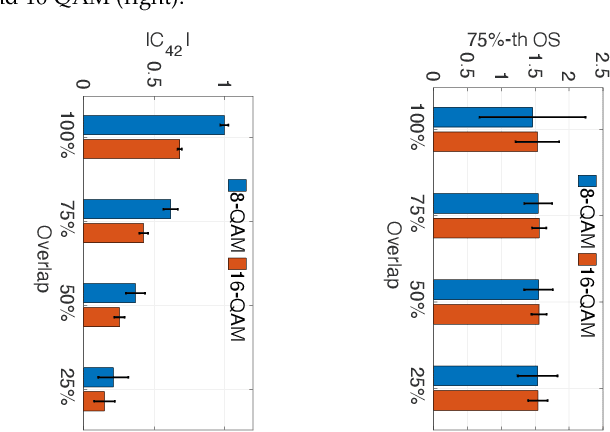
While critical for the practical progress of spectrum sharing, modulation recognition has so far been investigated under unrealistic assumptions: (i) a transmitter's bandwidth must be scanned alone and in full, (ii) prior knowledge of the technology must be available and (iii) a transmitter must be trustworthy. In reality these assumptions cannot be readily met, as a transmitter's bandwidth may only be scanned intermittently, partially, or alongside other transmitters, and modulation obfuscation may be introduced by short-lived scans or malicious activity. This paper presents LinksIQ, which bridges the gap between real-world spectrum sensing and the growing body of modrec methods designed under simplifying assumptions. Our key insight is that ordered IQ samples form distinctive patterns across modulations, which persist even with scan deficiencies. We mine these patterns through a Fisher Kernel framework and employ lightweight linear support vector machine for modulation classification. LinksIQ is robust to noise, scan partiality and data biases without utilizing prior knowledge of transmitter technology. Its accuracy consistently outperforms baselines in both simulated and real traces. We evaluate LinksIQ performance in a testbed using two popular SDR platforms, RTL-SDR and USRP. We demonstrate high detection accuracy (i.e. 0.74) even with a $20 RTL-SDR scanning at 50% transmitter overlap. This constitutes an average of 43% improvement over existing counterparts employed on RTL-SDR scans. We also explore the effects of platform-aware classifier training and discuss implications on real-world modrec system design. Our results demonstrate the feasibility of low-cost transmitter fingerprinting at scale.
DSL: Discriminative Subgraph Learning via Sparse Self-Representation
Mar 24, 2019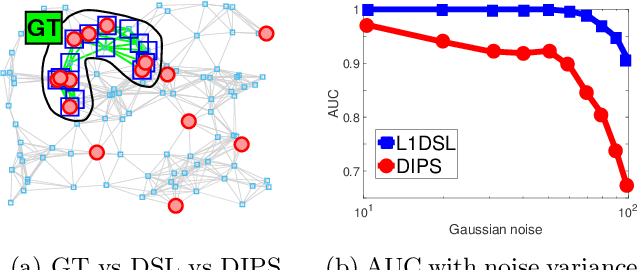
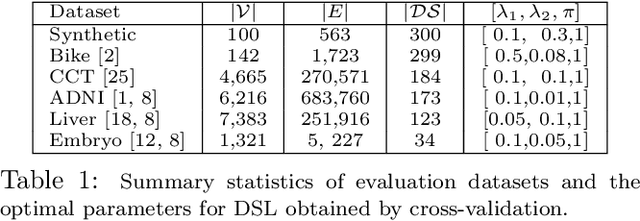

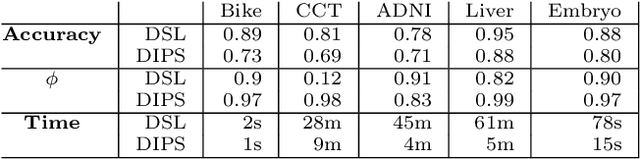
The goal in network state prediction (NSP) is to classify the global state (label) associated with features embedded in a graph. This graph structure encoding feature relationships is the key distinctive aspect of NSP compared to classical supervised learning. NSP arises in various applications: gene expression samples embedded in a protein-protein interaction (PPI) network, temporal snapshots of infrastructure or sensor networks, and fMRI coherence network samples from multiple subjects to name a few. Instances from these domains are typically ``wide'' (more features than samples), and thus, feature sub-selection is required for robust and generalizable prediction. How to best employ the network structure in order to learn succinct connected subgraphs encompassing the most discriminative features becomes a central challenge in NSP. Prior work employs connected subgraph sampling or graph smoothing within optimization frameworks, resulting in either large variance of quality or weak control over the connectivity of selected subgraphs. In this work we propose an optimization framework for discriminative subgraph learning (DSL) which simultaneously enforces (i) sparsity, (ii) connectivity and (iii) high discriminative power of the resulting subgraphs of features. Our optimization algorithm is a single-step solution for the NSP and the associated feature selection problem. It is rooted in the rich literature on maximal-margin optimization, spectral graph methods and sparse subspace self-representation. DSL simultaneously ensures solution interpretability and superior predictive power (up to 16% improvement in challenging instances compared to baselines), with execution times up to an hour for large instances.
* 9 pages
Discriminative Subnetworks with Regularized Spectral Learning for Global-state Network Data
Dec 19, 2015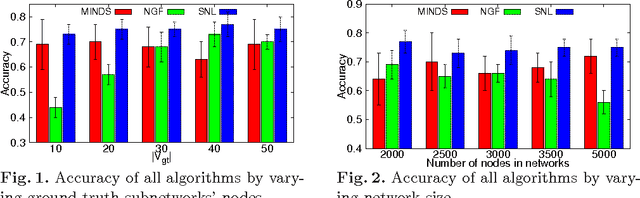
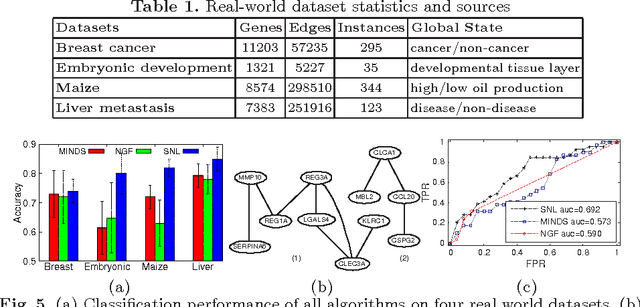
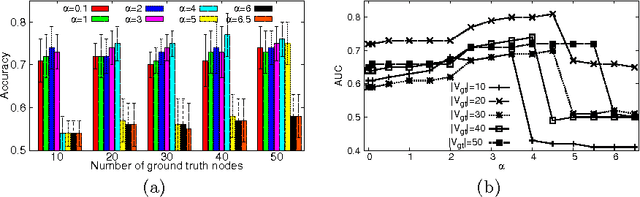
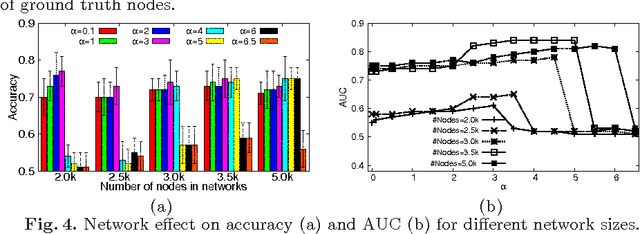
Data mining practitioners are facing challenges from data with network structure. In this paper, we address a specific class of global-state networks which comprises of a set of network instances sharing a similar structure yet having different values at local nodes. Each instance is associated with a global state which indicates the occurrence of an event. The objective is to uncover a small set of discriminative subnetworks that can optimally classify global network values. Unlike most existing studies which explore an exponential subnetwork space, we address this difficult problem by adopting a space transformation approach. Specifically, we present an algorithm that optimizes a constrained dual-objective function to learn a low-dimensional subspace that is capable of discriminating networks labelled by different global states, while reconciling with common network topology sharing across instances. Our algorithm takes an appealing approach from spectral graph learning and we show that the globally optimum solution can be achieved via matrix eigen-decomposition.
A Distance Measure for the Analysis of Polar Opinion Dynamics in Social Networks
Oct 17, 2015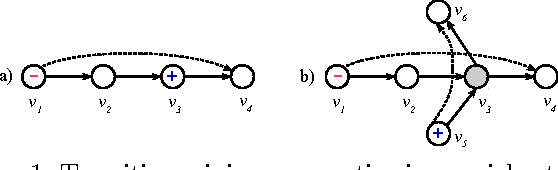
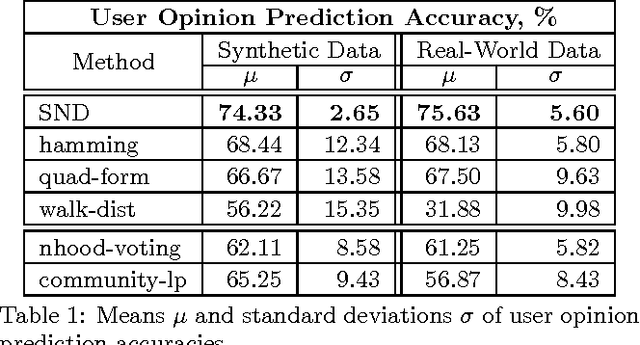
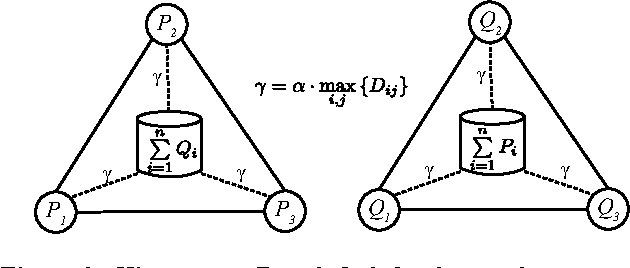
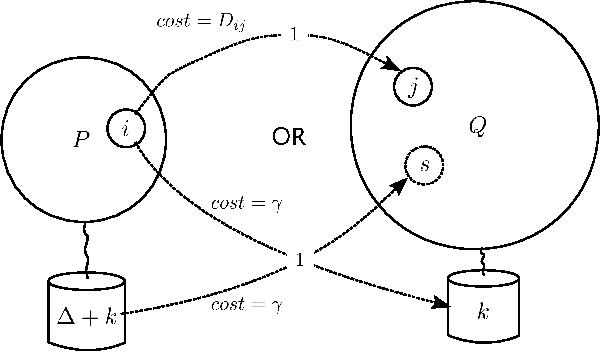
Analysis of opinion dynamics in social networks plays an important role in today's life. For applications such as predicting users' political preference, it is particularly important to be able to analyze the dynamics of competing opinions. While observing the evolution of polar opinions of a social network's users over time, can we tell when the network "behaved" abnormally? Furthermore, can we predict how the opinions of the users will change in the future? Do opinions evolve according to existing network opinion dynamics models? To answer such questions, it is not sufficient to study individual user behavior, since opinions can spread far beyond users' egonets. We need a method to analyze opinion dynamics of all network users simultaneously and capture the effect of individuals' behavior on the global evolution pattern of the social network. In this work, we introduce Social Network Distance (SND) - a distance measure that quantifies the "cost" of evolution of one snapshot of a social network into another snapshot under various models of polar opinion propagation. SND has a rich semantics of a transportation problem, yet, is computable in time linear in the number of users, which makes SND applicable to the analysis of large-scale online social networks. In our experiments with synthetic and real-world Twitter data, we demonstrate the utility of our distance measure for anomalous event detection. It achieves a true positive rate of 0.83, twice as high as that of alternatives. When employed for opinion prediction in Twitter, our method's accuracy is 75.63%, which is 7.5% higher than that of the next best method. Source Code: https://cs.ucsb.edu/~victor/pub/ucsb/dbl/snd/